 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Exploratory Landscape Analysis: Extreme Feature Selection for Classifying BBOB Functions
Paper and Code
Feb 01, 2021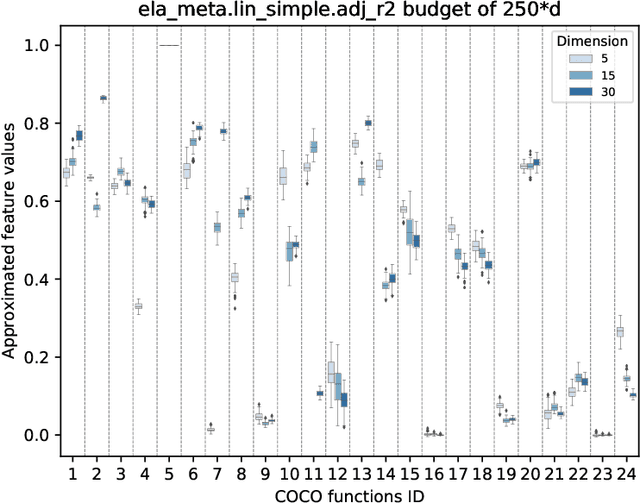
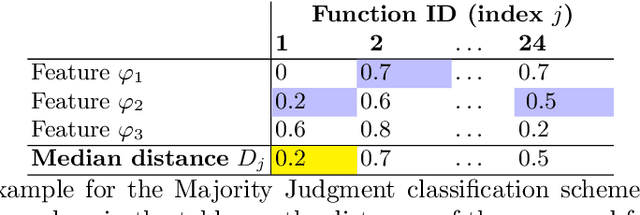
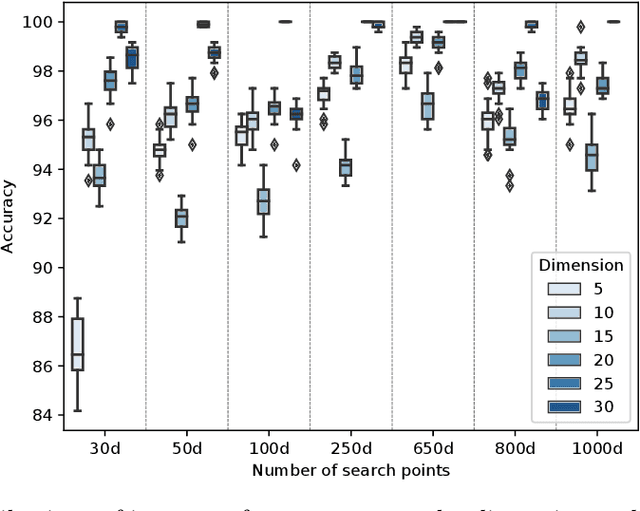
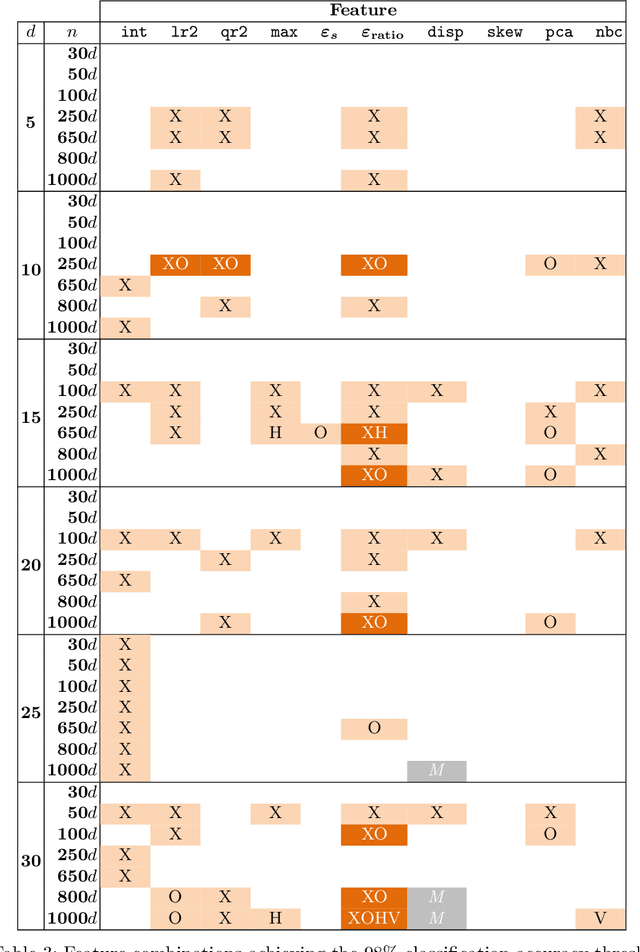
Facilitated by the recent advances of Machine Learning (ML), the automated design of optimization heuristics is currently shaking up evolutionary computation (EC). Where the design of hand-picked guidelines for choosing a most suitable heuristic has long dominated research activities in the field, automatically trained heuristics are now seen to outperform human-derived choices even for well-researched optimization tasks. ML-based EC is therefore not any more a futuristic vision, but has become an integral part of our community. A key criticism that ML-based heuristics are often faced with is their potential lack of explainability, which may hinder future developments. This applies in particular to supervised learning techniques which extrapolate algorithms' performance based on exploratory landscape analysis (ELA). In such applications, it is not uncommon to use dozens of problem features to build the models underlying the specific algorithm selection or configuration task. Our goal in this work is to analyze whether this many features are indeed needed. Using the classification of the BBOB test functions as testbed, we show that a surprisingly small number of features -- often less than four -- can suffice to achieve a 98\% accuracy. Interestingly, the number of features required to meet this threshold is found to decrease with the problem dimension. We show that the classification accuracy transfers to settings in which several instances are involved in training and testing. In the leave-one-instance-out setting, however, classification accuracy drops significantly, and the transformation-invariance of the features becomes a decisive success factor.