 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing the Empirical Attainment Function for Analyzing Single-objective Black-box Optimization Algorithms
Apr 02, 2024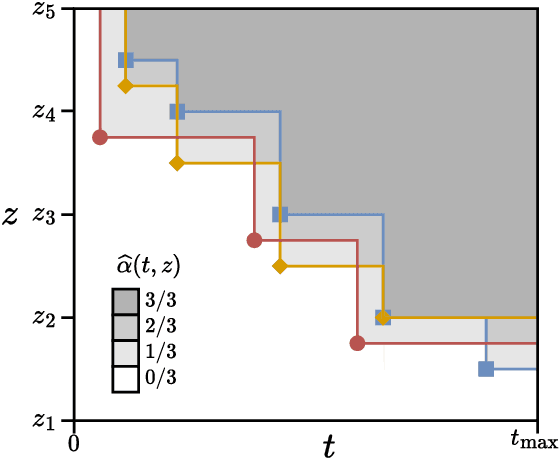
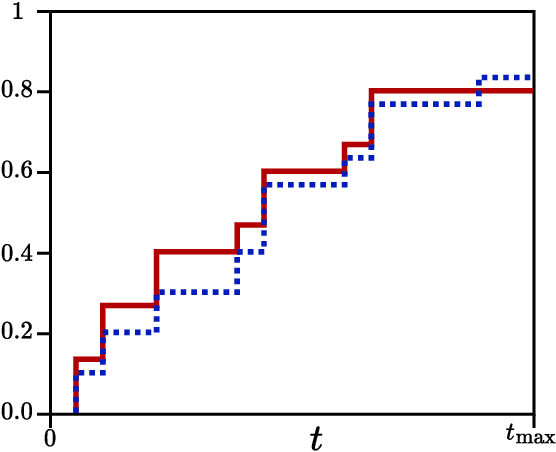
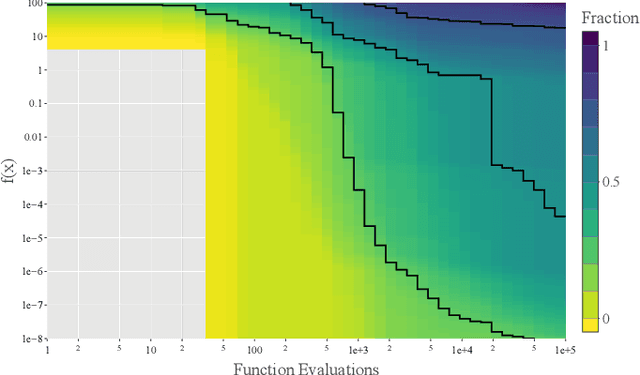
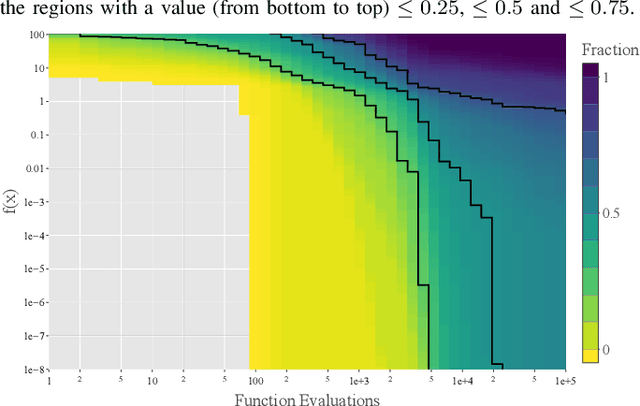
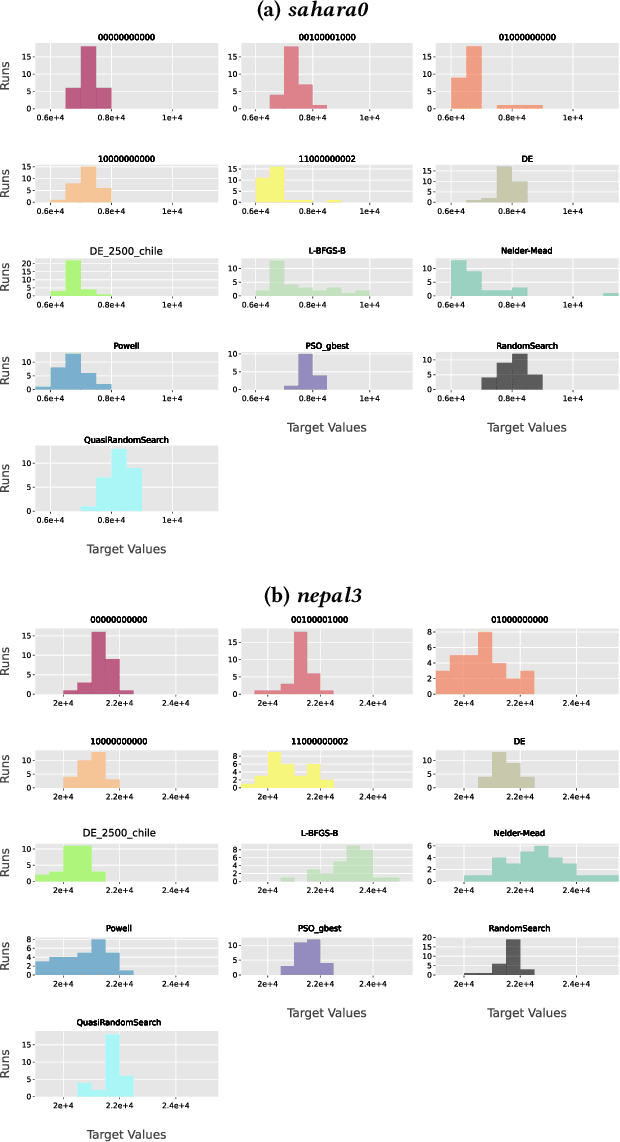
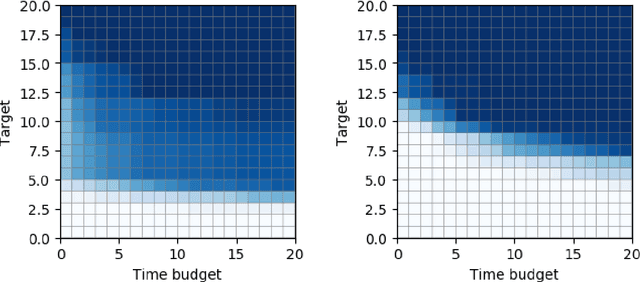
A widely accepted way to assess the performance of iterative black-box optimizers is to analyze their empirical cumulative distribution function (ECDF) of pre-defined quality targets achieved not later than a given runtime. In this work, we consider an alternative approach, based on the empirical attainment function (EAF) and we show that the target-based ECDF is an approximation of the EAF. We argue that the EAF has several advantages over the target-based ECDF. In particular, it does not require defining a priori quality targets per function, captures performance differences more precisely, and enables the use of additional summary statistics that enrich the analysis. We also show that the average area over the convergence curves is a simpler-to-calculate, but equivalent, measure of anytime performance. To facilitate the accessibility of the EAF, we integrate a module to compute it into the IOHanalyzer platform. Finally, we illustrate the use of the EAF via synthetic examples and via the data available for the BBOB suite.
MultiZenoTravel: a Tunable Benchmark for Multi-Objective Planning with Known Pareto Front
Apr 28, 2023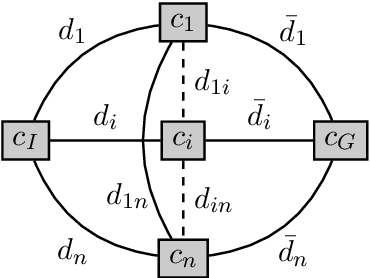


Multi-objective AI planning suffers from a lack of benchmarks exhibiting known Pareto Fronts. In this work, we propose a tunable benchmark generator, together with a dedicated solver that provably computes the true Pareto front of the resulting instances. First, we prove a proposition allowing us to characterize the optimal plans for a constrained version of the problem, and then show how to reduce the general problem to the constrained one. Second, we provide a constructive way to find all the Pareto-optimal plans and discuss the complexity of the algorithm. We provide an implementation that allows the solver to handle realistic instances in a reasonable time. Finally, as a practical demonstration, we used this solver to find all Pareto-optimal plans between the two largest airports in the world, considering the routes between the 50 largest airports, spherical distances between airports and a made-up risk.
Automated Algorithm Selection for Radar Network Configuration
May 07, 2022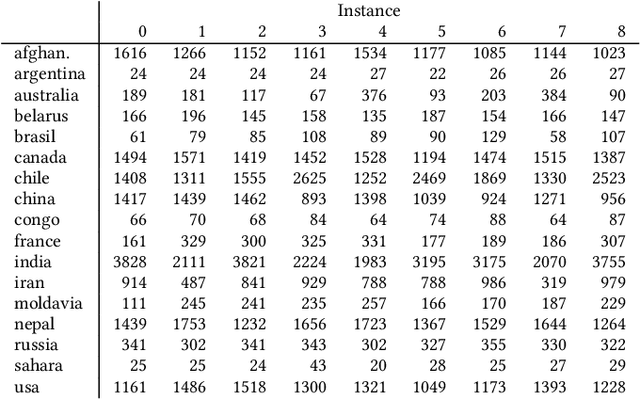

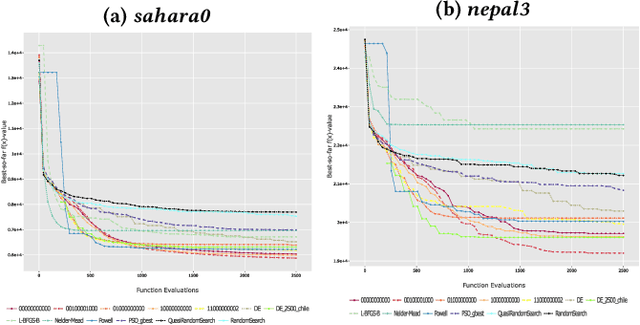
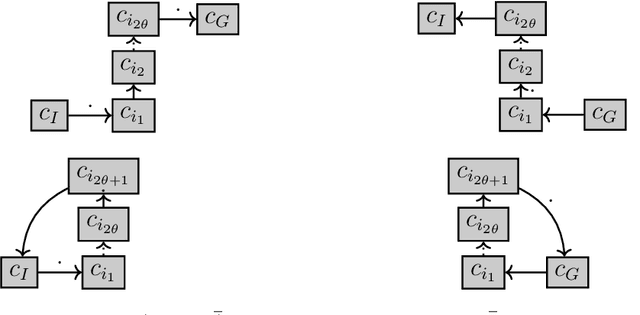
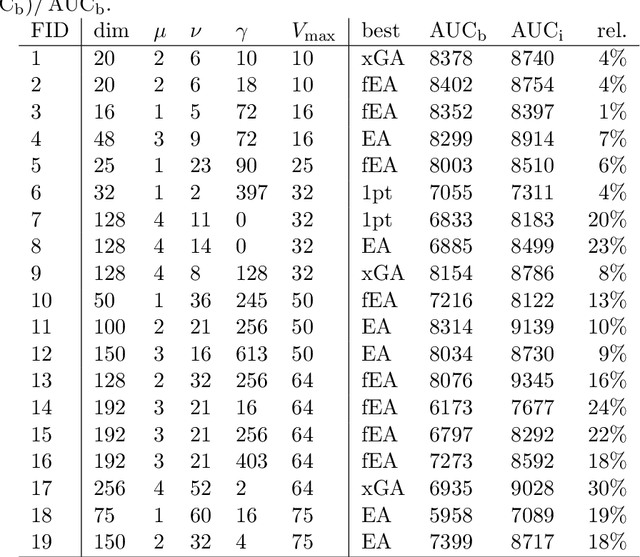
The configuration of radar networks is a complex problem that is often performed manually by experts with the help of a simulator. Different numbers and types of radars as well as different locations that the radars shall cover give rise to different instances of the radar configuration problem. The exact modeling of these instances is complex, as the quality of the configurations depends on a large number of parameters, on internal radar processing, and on the terrains on which the radars need to be placed. Classic optimization algorithms can therefore not be applied to this problem, and we rely on "trial-and-error" black-box approaches. In this paper, we study the performances of 13~black-box optimization algorithms on 153~radar network configuration problem instances. The algorithms perform considerably better than human experts. Their ranking, however, depends on the budget of configurations that can be evaluated and on the elevation profile of the location. We therefore also investigate automated algorithm selection approaches. Our results demonstrate that a pipeline that extracts instance features from the elevation of the terrain performs on par with the classical, far more expensive approach that extracts features from the objective function.
Extensible Logging and Empirical Attainment Function for IOHexperimenter
Sep 29, 2021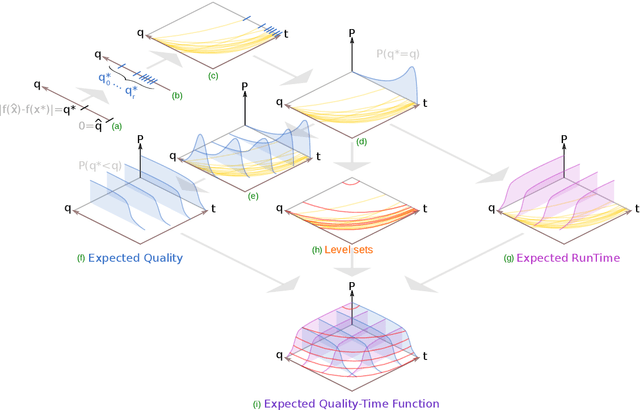
In order to allow for large-scale, landscape-aware, per-instance algorithm selection, a benchmarking platform software is key. IOHexperimenter provides a large set of synthetic problems, a logging system, and a fast implementation. In this work, we refactor IOHexperimenter's logging system, in order to make it more extensible and modular. Using this new system, we implement a new logger, which aims at computing performance metrics of an algorithm across a benchmark. The logger computes the most generic view on an anytime stochastic heuristic performances, in the form of the Empirical Attainment Function (EAF). We also provide some common statistics on the EAF and its discrete counterpart, the Empirical Attainment Histogram. Our work has eventually been merged in the IOHexperimenter codebase.
Paradiseo: From a Modular Framework for Evolutionary Computation to the Automated Design of Metaheuristics ---22 Years of Paradiseo---
May 02, 2021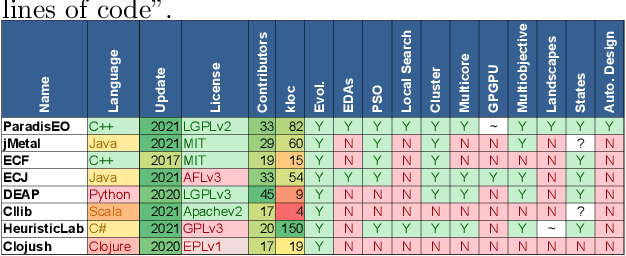
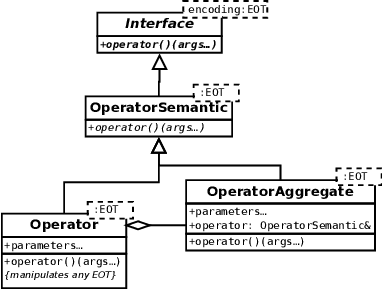
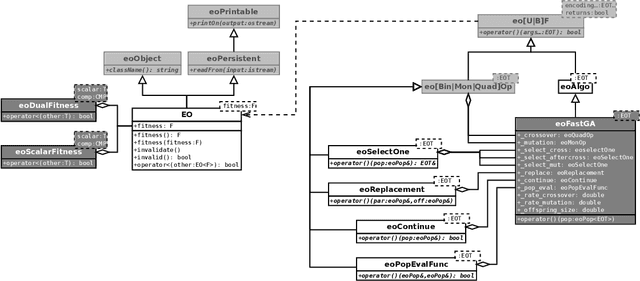
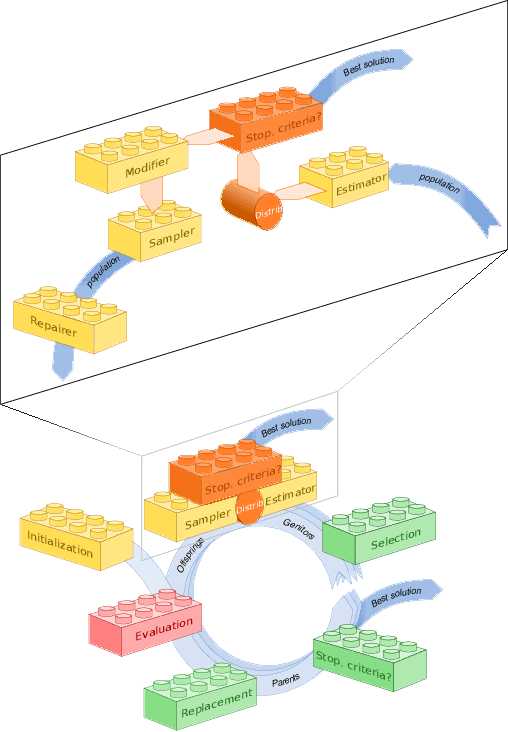
The success of metaheuristic optimization methods has led to the development of a large variety of algorithm paradigms. However, no algorithm clearly dominates all its competitors on all problems. Instead, the underlying variety of landscapes of optimization problems calls for a variety of algorithms to solve them efficiently. It is thus of prior importance to have access to mature and flexible software frameworks which allow for an efficient exploration of the algorithm design space. Such frameworks should be flexible enough to accommodate any kind of metaheuristics, and open enough to connect with higher-level optimization, monitoring and evaluation softwares. This article summarizes the features of the ParadisEO framework, a comprehensive C++ free software which targets the development of modular metaheuristics. ParadisEO provides a highly modular architecture, a large set of components, speed of execution and automated algorithm design features, which are key to modern approaches to metaheuristics development.
Towards Large Scale Automated Algorithm Design by Integrating Modular Benchmarking Frameworks
Feb 12, 2021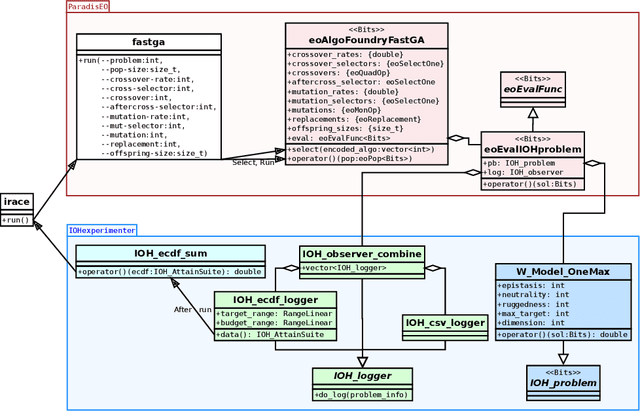

We present a first proof-of-concept use-case that demonstrates the efficiency of interfacing the algorithm framework ParadisEO with the automated algorithm configuration tool irace and the experimental platform IOHprofiler. By combing these three tools, we obtain a powerful benchmarking environment that allows us to systematically analyze large classes of algorithm spaces on complex benchmark problems. Key advantages of our pipeline are fast evaluation times, the possibility to generate rich data sets to support the analysis of the algorithms, and a standardized interface that can be used to benchmark very broad classes of sampling-based optimization heuristics. In addition to enabling systematic algorithm configuration studies, our approach paves a way for assessing the contribution of new ideas in interplay with already existing operators -- a promising avenue for our research domain, which at present may have a too strong focus on comparing entire algorithm instances.
Towards Explainable Exploratory Landscape Analysis: Extreme Feature Selection for Classifying BBOB Functions
Feb 01, 2021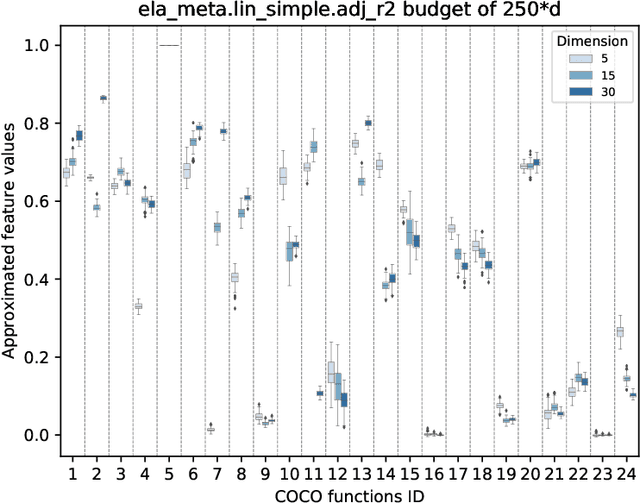
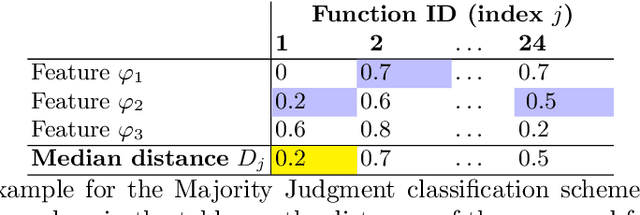
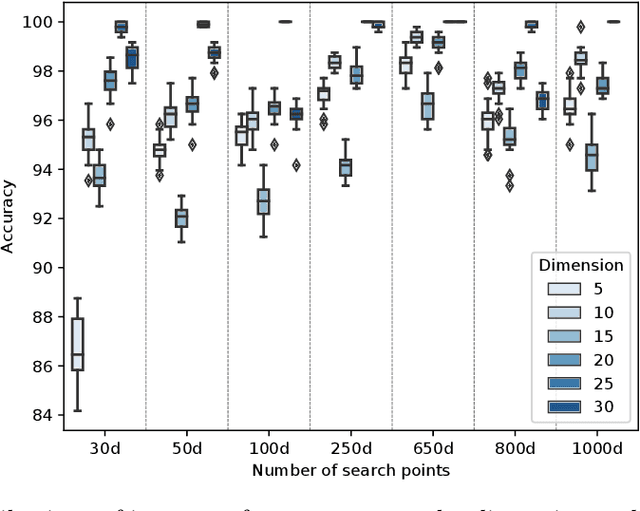
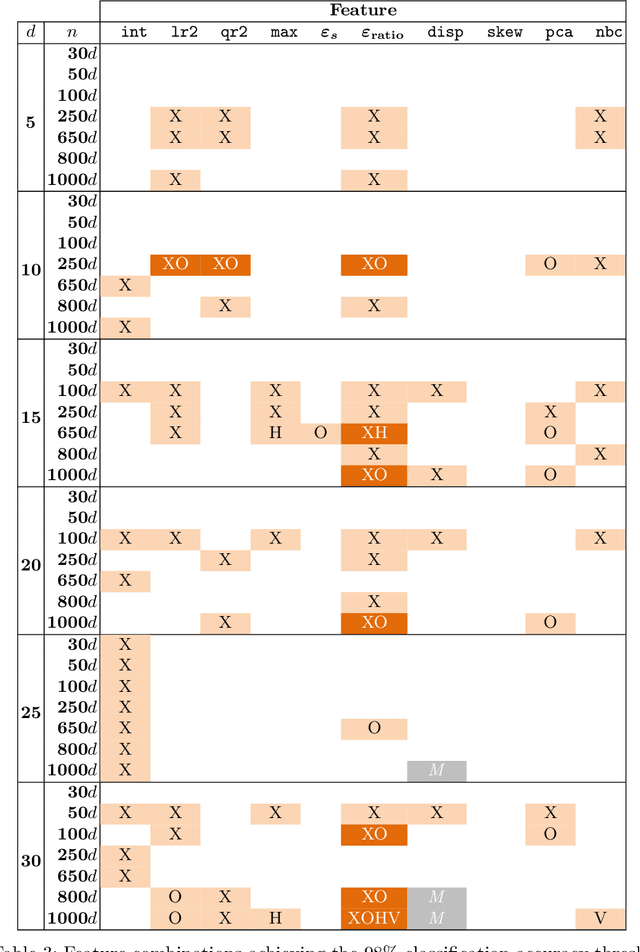
Facilitated by the recent advances of Machine Learning (ML), the automated design of optimization heuristics is currently shaking up evolutionary computation (EC). Where the design of hand-picked guidelines for choosing a most suitable heuristic has long dominated research activities in the field, automatically trained heuristics are now seen to outperform human-derived choices even for well-researched optimization tasks. ML-based EC is therefore not any more a futuristic vision, but has become an integral part of our community. A key criticism that ML-based heuristics are often faced with is their potential lack of explainability, which may hinder future developments. This applies in particular to supervised learning techniques which extrapolate algorithms' performance based on exploratory landscape analysis (ELA). In such applications, it is not uncommon to use dozens of problem features to build the models underlying the specific algorithm selection or configuration task. Our goal in this work is to analyze whether this many features are indeed needed. Using the classification of the BBOB test functions as testbed, we show that a surprisingly small number of features -- often less than four -- can suffice to achieve a 98\% accuracy. Interestingly, the number of features required to meet this threshold is found to decrease with the problem dimension. We show that the classification accuracy transfers to settings in which several instances are involved in training and testing. In the leave-one-instance-out setting, however, classification accuracy drops significantly, and the transformation-invariance of the features becomes a decisive success factor.
Exploratory Landscape Analysis is Strongly Sensitive to the Sampling Strategy
Jun 19, 2020
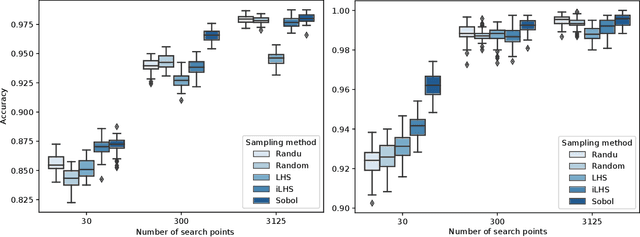
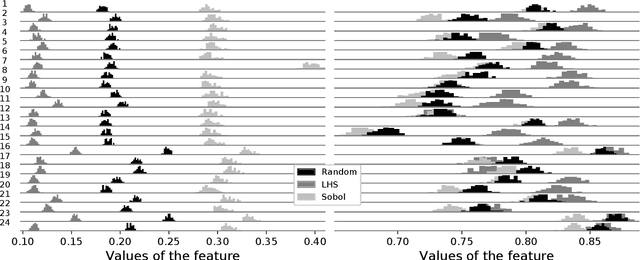
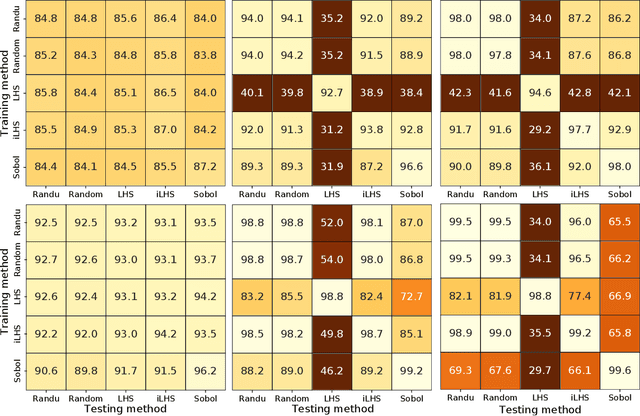
Exploratory landscape analysis (ELA) supports supervised learning approaches for automated algorithm selection and configuration by providing sets of features that quantify the most relevant characteristics of the optimization problem at hand. In black-box optimization, where an explicit problem representation is not available, the feature values need to be approximated from a small number of sample points. In practice, uniformly sampled random point sets and Latin hypercube constructions are commonly used sampling strategies. In this work, we analyze how the sampling method and the sample size influence the quality of the feature value approximations and how this quality impacts the accuracy of a standard classification task. While, not unexpectedly, increasing the number of sample points gives more robust estimates for the feature values, to our surprise we find that the feature value approximations for different sampling strategies do not converge to the same value. This implies that approximated feature values cannot be interpreted independently of the underlying sampling strategy. As our classification experiments show, this also implies that the feature approximations used for training a classifier must stem from the same sampling strategy as those used for the actual classification tasks. As a side result we show that classifiers trained with feature values approximated by Sobol' sequences achieve higher accuracy than any of the standard sampling techniques. This may indicate improvement potential for ELA-trained machine learning models.