 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiZenoTravel: a Tunable Benchmark for Multi-Objective Planning with Known Pareto Front
Apr 28, 2023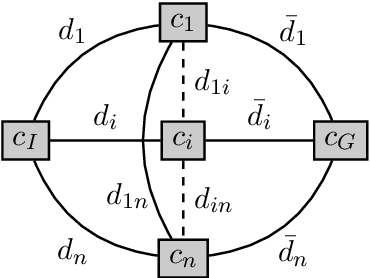


Multi-objective AI planning suffers from a lack of benchmarks exhibiting known Pareto Fronts. In this work, we propose a tunable benchmark generator, together with a dedicated solver that provably computes the true Pareto front of the resulting instances. First, we prove a proposition allowing us to characterize the optimal plans for a constrained version of the problem, and then show how to reduce the general problem to the constrained one. Second, we provide a constructive way to find all the Pareto-optimal plans and discuss the complexity of the algorithm. We provide an implementation that allows the solver to handle realistic instances in a reasonable time. Finally, as a practical demonstration, we used this solver to find all Pareto-optimal plans between the two largest airports in the world, considering the routes between the 50 largest airports, spherical distances between airports and a made-up risk.
First steps towards quantum machine learning applied to the classification of event-related potentials
Feb 06, 2023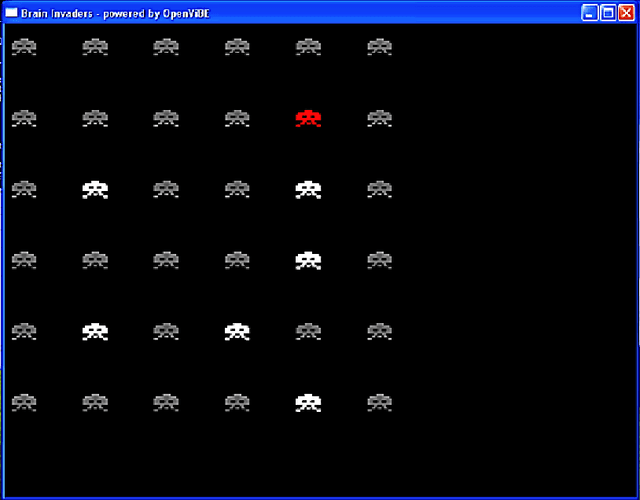
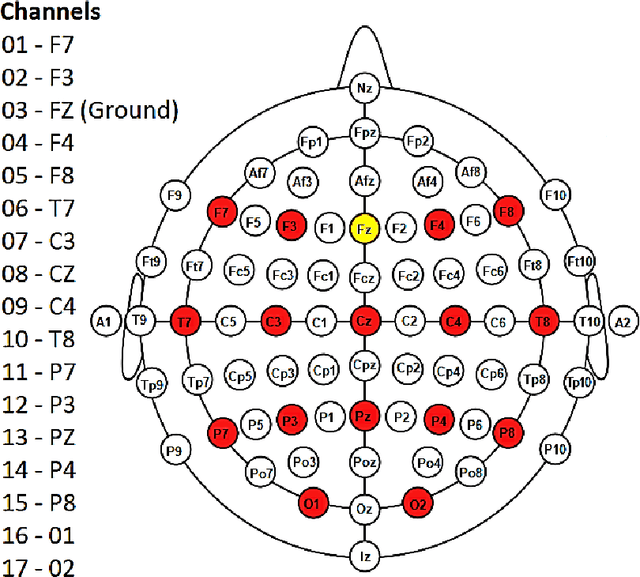
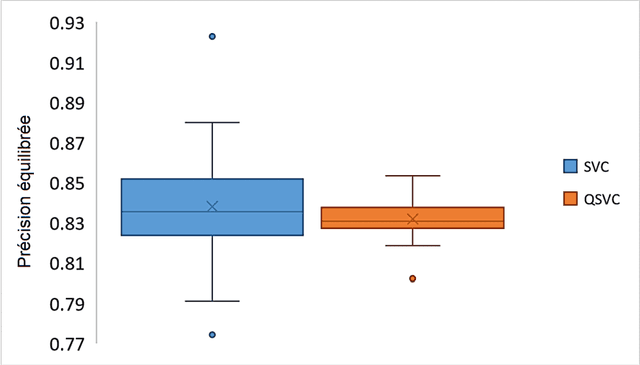
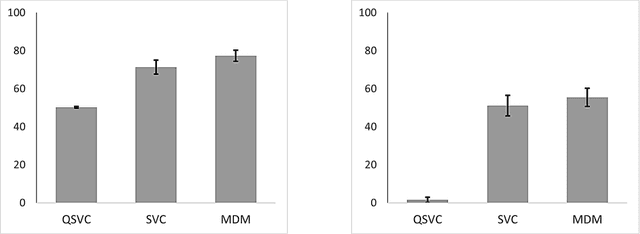
Low information transfer rate is a major bottleneck for brain-computer interfaces based on non-invasive electroencephalography (EEG) for clinical applications. This led to the development of more robust and accurate classifiers. In this study, we investigate the performance of quantum-enhanced support vector classifier (QSVC). Training (predicting) balanced accuracy of QSVC was 83.17 (50.25) %. This result shows that the classifier was able to learn from EEG data, but that more research is required to obtain higher predicting accuracy. This could be achieved by a better configuration of the classifier, such as increasing the number of shots.
Paradiseo: From a Modular Framework for Evolutionary Computation to the Automated Design of Metaheuristics ---22 Years of Paradiseo---
May 02, 2021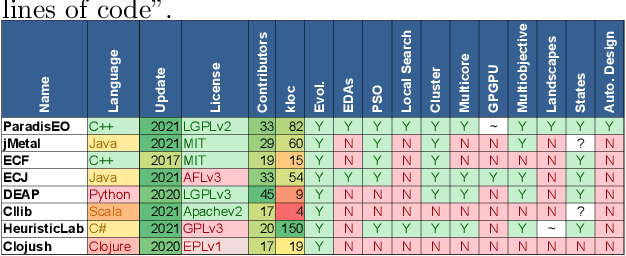
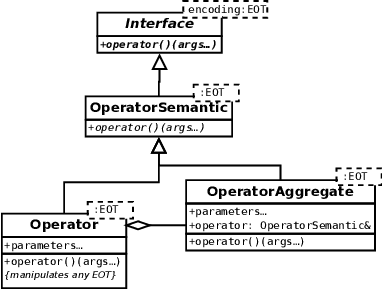
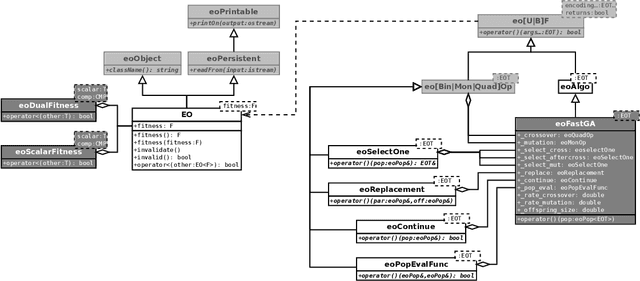
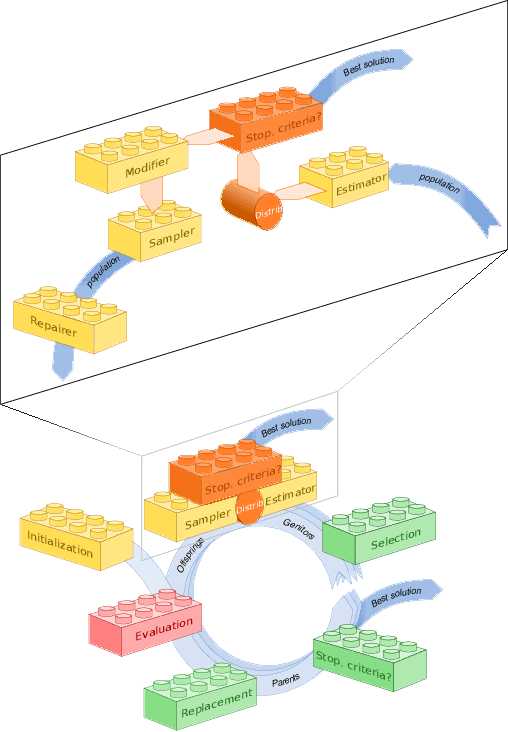
The success of metaheuristic optimization methods has led to the development of a large variety of algorithm paradigms. However, no algorithm clearly dominates all its competitors on all problems. Instead, the underlying variety of landscapes of optimization problems calls for a variety of algorithms to solve them efficiently. It is thus of prior importance to have access to mature and flexible software frameworks which allow for an efficient exploration of the algorithm design space. Such frameworks should be flexible enough to accommodate any kind of metaheuristics, and open enough to connect with higher-level optimization, monitoring and evaluation softwares. This article summarizes the features of the ParadisEO framework, a comprehensive C++ free software which targets the development of modular metaheuristics. ParadisEO provides a highly modular architecture, a large set of components, speed of execution and automated algorithm design features, which are key to modern approaches to metaheuristics development.
Two-stage Optimization for Machine Learning Workflow
Jul 01, 2019
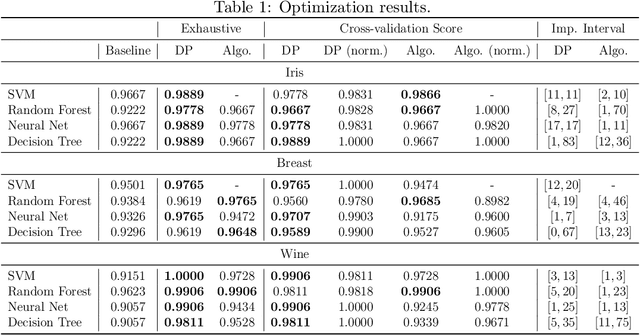
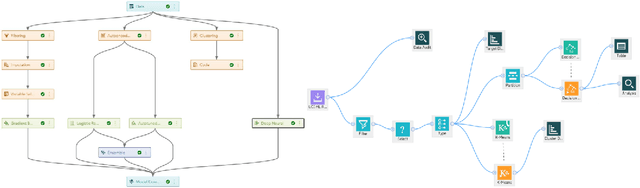
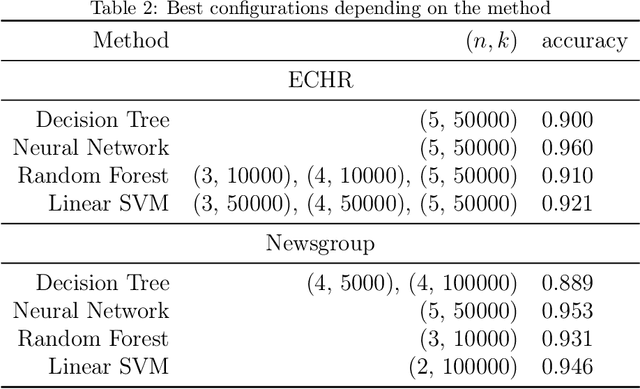
Machines learning techniques plays a preponderant role in dealing with massive amount of data and are employed in almost every possible domain. Building a high quality machine learning model to be deployed in production is a challenging task, from both, the subject matter experts and the machine learning practitioners. For a broader adoption and scalability of machine learning systems, the construction and configuration of machine learning workflow need to gain in automation. In the last few years, several techniques have been developed in this direction, known as autoML. In this paper, we present a two-stage optimization process to build data pipelines and configure machine learning algorithms. First, we study the impact of data pipelines compared to algorithm configuration in order to show the importance of data preprocessing over hyperparameter tuning. The second part presents policies to efficiently allocate search time between data pipeline construction and algorithm configuration. Those policies are agnostic from the metaoptimizer. Last, we present a metric to determine if a data pipeline is specific or independent from the algorithm, enabling fine-grain pipeline pruning and meta-learning for the coldstart problem.
European Court of Human Right Open Data project
Oct 07, 2018
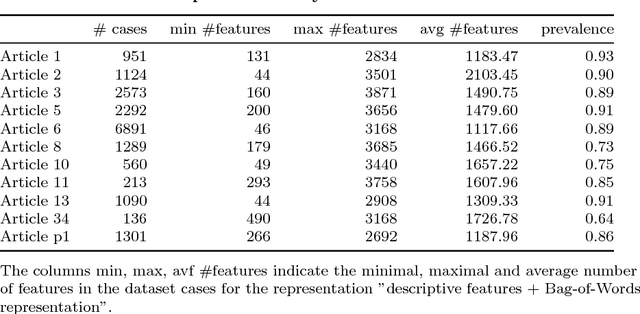
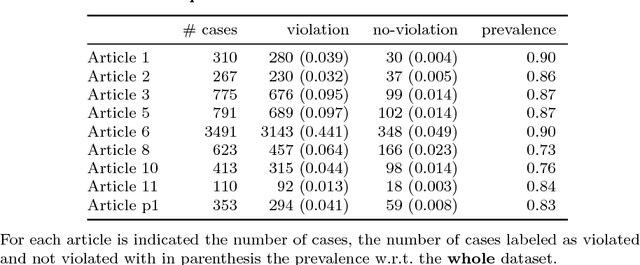
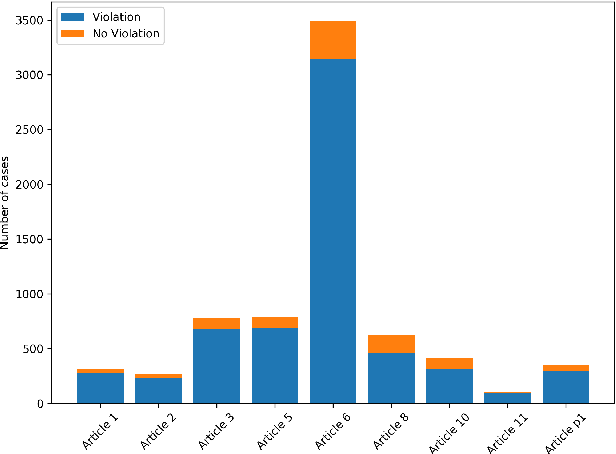
This paper presents thirteen datasets for binary, multiclass and multilabel classification based on the European Court of Human Rights judgments since its creation. The interest of such datasets is explained through the prism of the researcher, the data scientist, the citizen and the legal practitioner. Contrarily to many datasets, the creation process, from the collection of raw data to the feature transformation, is provided under the form of a collection of fully automated and open-source scripts. It ensures reproducibility and a high level of confidence in the processed data which is some of the most important issues in data governance nowadays.
Binary Classification in Unstructured Space With Hypergraph Case-Based Reasoning
Jun 16, 2018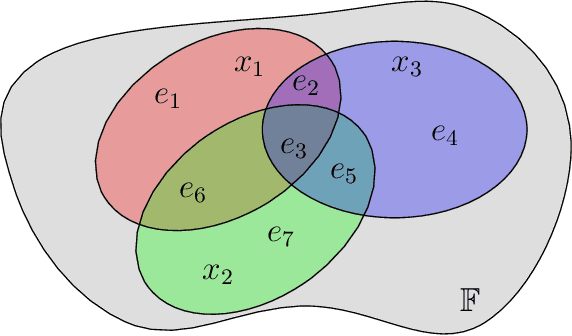
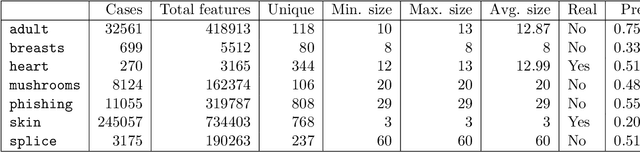
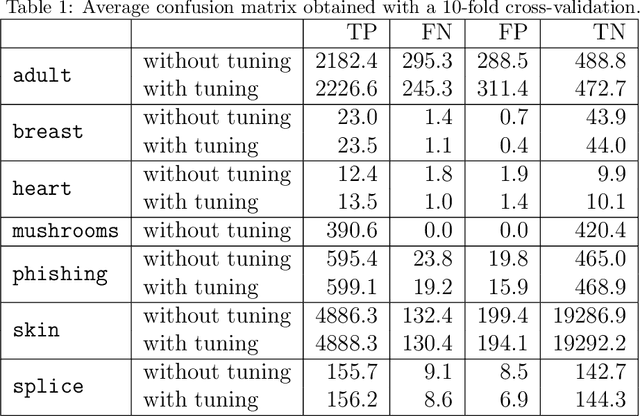
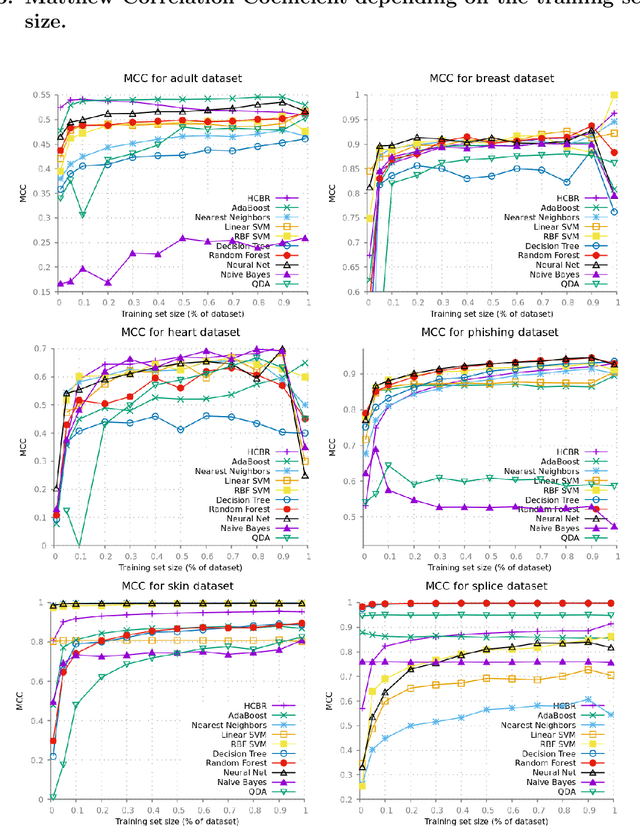
Binary classification is one of the most common problem in machine learning. It consists in predicting whether a given element is of a particular class. In this paper, a new algorithm for binary classification is proposed using a hypergraph representation. Each element to be classified is partitioned according to its interactions with the training set. For each class, the total support is calculated as a convex combination of the {\it evidence} strength of the element of the partition. The evidence measure is pre-computed using the hypergraph induced by the training set and iteratively adjusted through a training phase. It does not require structured information, each case being represented by a set of {\it agnostic information} atoms. Empirical validation demonstrates its high potential on a wide range of well-known datasets and the results are compared to the state-of-art. The time complexity is given and empirically validated. Its capacity to provide good performances without hyperparameter tuning compared to standard classification methods is studied. Finally, the limitation of the model space is discussed and some potential solutions proposed.