 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Optimization for Machine Learning Workflow
Paper and Code

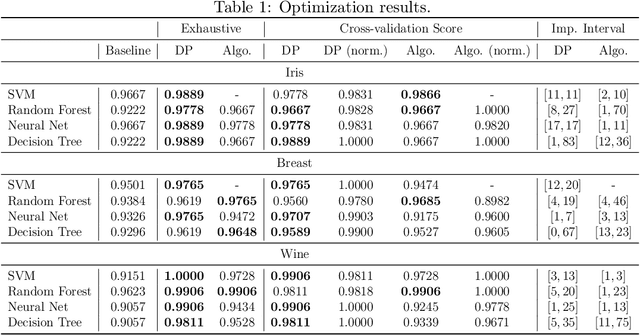
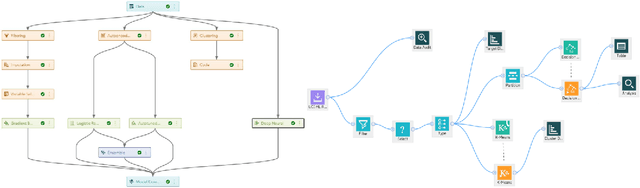
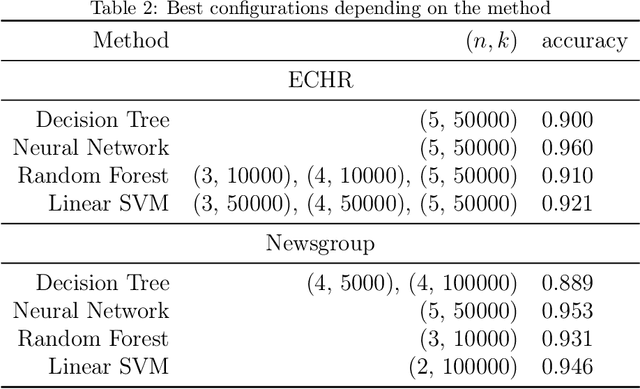
Machines learning techniques plays a preponderant role in dealing with massive amount of data and are employed in almost every possible domain. Building a high quality machine learning model to be deployed in production is a challenging task, from both, the subject matter experts and the machine learning practitioners. For a broader adoption and scalability of machine learning systems, the construction and configuration of machine learning workflow need to gain in automation. In the last few years, several techniques have been developed in this direction, known as autoML. In this paper, we present a two-stage optimization process to build data pipelines and configure machine learning algorithms. First, we study the impact of data pipelines compared to algorithm configuration in order to show the importance of data preprocessing over hyperparameter tuning. The second part presents policies to efficiently allocate search time between data pipeline construction and algorithm configuration. Those policies are agnostic from the metaoptimizer. Last, we present a metric to determine if a data pipeline is specific or independent from the algorithm, enabling fine-grain pipeline pruning and meta-learning for the coldstart problem.