 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Inference via Paired Autoencoders
Jan 16, 2026This work describes a novel data-driven latent space inference framework built on paired autoencoders to handle observational inconsistencies when solving inverse problems. Our approach uses two autoencoders, one for the parameter space and one for the observation space, connected by learned mappings between the autoencoders' latent spaces. These mappings enable a surrogate for regularized inversion and optimization in low-dimensional, informative latent spaces. Our flexible framework can work with partial, noisy, or out-of-distribution data, all while maintaining consistency with the underlying physical models. The paired autoencoders enable reconstruction of corrupted data, and then use the reconstructed data for parameter estimation, which produces more accurate reconstructions compared to paired autoencoders alone and end-to-end encoder-decoders of the same architecture, especially in scenarios with data inconsistencies. We demonstrate our approaches on two imaging examples in medical tomography and geophysical seismic-waveform inversion, but the described approaches are broadly applicable to a variety of inverse problems in scientific and engineering applications.
A Paired Autoencoder Framework for Inverse Problems via Bayes Risk Minimization
Jan 24, 2025In this work, we describe a new data-driven approach for inverse problems that exploits technologies from machine learning, in particular autoencoder network structures. We consider a paired autoencoder framework, where two autoencoders are used to efficiently represent the input and target spaces separately and optimal mappings are learned between latent spaces, thus enabling forward and inverse surrogate mappings. We focus on interpretations using Bayes risk and empirical Bayes risk minimization, and we provide various theoretical results and connections to existing works on low-rank matrix approximations. Similar to end-to-end approaches, our paired approach creates a surrogate model for forward propagation and regularized inversion. However, our approach outperforms existing approaches in scenarios where training data for unsupervised learning are readily available but training pairs for supervised learning are scarce. Furthermore, we show that cheaply computable evaluation metrics are available through this framework and can be used to predict whether the solution for a new sample should be predicted well.
Algorithm Selection with Probing Trajectories: Benchmarking the Choice of Classifier Model
Jan 20, 2025Recent approaches to training algorithm selectors in the black-box optimisation domain have advocated for the use of training data that is algorithm-centric in order to encapsulate information about how an algorithm performs on an instance, rather than relying on information derived from features of the instance itself. Probing-trajectories that consist of a sequence of objective performance per function evaluation obtained from a short run of an algorithm have recently shown particular promise in training accurate selectors. However, training models on this type of data requires an appropriately chosen classifier given the sequential nature of the data. There are currently no clear guidelines for choosing the most appropriate classifier for algorithm selection using time-series data from the plethora of models available. To address this, we conduct a large benchmark study using 17 different classifiers and three types of trajectory on a classification task using the BBOB benchmark suite using both leave-one-instance out and leave-one-problem out cross-validation. In contrast to previous studies using tabular data, we find that the choice of classifier has a significant impact, showing that feature-based and interval-based models are the best choices.
Beyond the Hype: Benchmarking LLM-Evolved Heuristics for Bin Packing
Jan 20, 2025
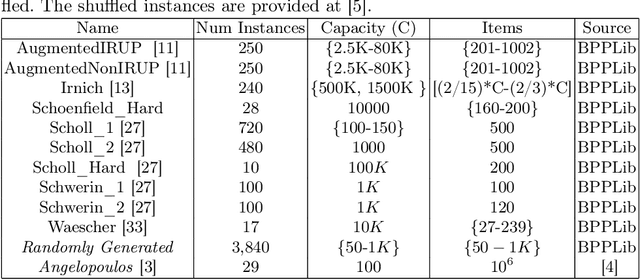
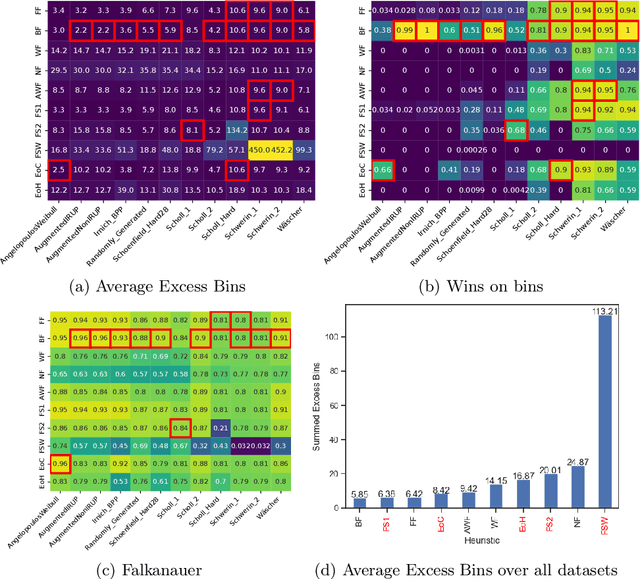
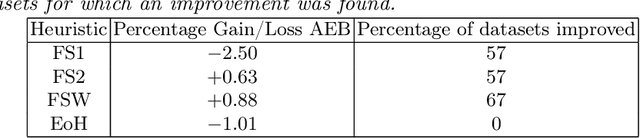
Coupling Large Language Models (LLMs) with Evolutionary Algorithms has recently shown significant promise as a technique to design new heuristics that outperform existing methods, particularly in the field of combinatorial optimisation. An escalating arms race is both rapidly producing new heuristics and improving the efficiency of the processes evolving them. However, driven by the desire to quickly demonstrate the superiority of new approaches, evaluation of the new heuristics produced for a specific domain is often cursory: testing on very few datasets in which instances all belong to a specific class from the domain, and on few instances per class. Taking bin-packing as an example, to the best of our knowledge we conduct the first rigorous benchmarking study of new LLM-generated heuristics, comparing them to well-known existing heuristics across a large suite of benchmark instances using three performance metrics. For each heuristic, we then evolve new instances won by the heuristic and perform an instance space analysis to understand where in the feature space each heuristic performs well. We show that most of the LLM heuristics do not generalise well when evaluated across a broad range of benchmarks in contrast to existing simple heuristics, and suggest that any gains from generating very specialist heuristics that only work in small areas of the instance space need to be weighed carefully against the considerable cost of generating these heuristics.
Stalling in Space: Attractor Analysis for any Algorithm
Dec 20, 2024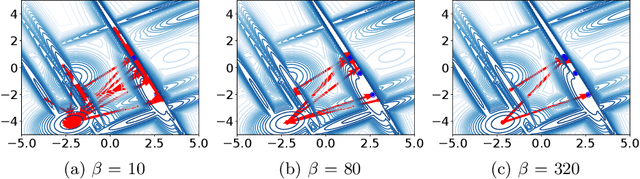

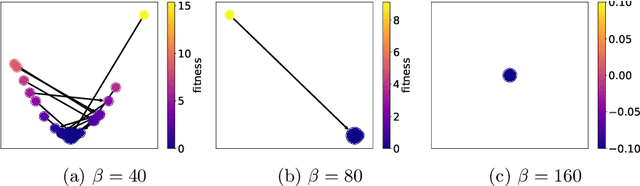

Network-based representations of fitness landscapes have grown in popularity in the past decade; this is probably because of growing interest in explainability for optimisation algorithms. Local optima networks (LONs) have been especially dominant in the literature and capture an approximation of local optima and their connectivity in the landscape. However, thus far, LONs have been constructed according to a strict definition of what a local optimum is: the result of local search. Many evolutionary approaches do not include this, however. Popular algorithms such as CMA-ES have therefore never been subject to LON analysis. Search trajectory networks (STNs) offer a possible alternative: nodes can be any search space location. However, STNs are not typically modelled in such a way that models temporal stalls: that is, a region in the search space where an algorithm fails to find a better solution over a defined period of time. In this work, we approach this by systematically analysing a special case of STN which we name attractor networks. These offer a coarse-grained view of algorithm behaviour with a singular focus on stall locations. We construct attractor networks for CMA-ES, differential evolution, and random search for 24 noiseless black-box optimisation benchmark problems. The properties of attractor networks are systematically explored. They are also visualised and compared to traditional LONs and STN models. We find that attractor networks facilitate insights into algorithm behaviour which other models cannot, and we advocate for the consideration of attractor analysis even for algorithms which do not include local search.
Elucidating the Design Choice of Probability Paths in Flow Matching for Forecasting
Oct 04, 2024Flow matching has recently emerged as a powerful paradigm for generative modeling and has been extended to probabilistic time series forecasting in latent spaces. However, the impact of the specific choice of probability path model on forecasting performance remains under-explored. In this work, we demonstrate that forecasting spatio-temporal data with flow matching is highly sensitive to the selection of the probability path model. Motivated by this insight, we propose a novel probability path model designed to improve forecasting performance. Our empirical results across various dynamical system benchmarks show that our model achieves faster convergence during training and improved predictive performance compared to existing probability path models. Importantly, our approach is efficient during inference, requiring only a few sampling steps. This makes our proposed model practical for real-world applications and opens new avenues for probabilistic forecasting.
Evaluating the Robustness of Deep-Learning Algorithm-Selection Models by Evolving Adversarial Instances
Jun 24, 2024



Deep neural networks (DNN) are increasingly being used to perform algorithm-selection in combinatorial optimisation domains, particularly as they accommodate input representations which avoid designing and calculating features. Mounting evidence from domains that use images as input shows that deep convolutional networks are vulnerable to adversarial samples, in which a small perturbation of an instance can cause the DNN to misclassify. However, it remains unknown as to whether deep recurrent networks (DRN) which have recently been shown promise as algorithm-selectors in the bin-packing domain are equally vulnerable. We use an evolutionary algorithm (EA) to find perturbations of instances from two existing benchmarks for online bin packing that cause trained DRNs to misclassify: adversarial samples are successfully generated from up to 56% of the original instances depending on the dataset. Analysis of the new misclassified instances sheds light on the `fragility' of some training instances, i.e. instances where it is trivial to find a small perturbation that results in a misclassification and the factors that influence this. Finally, the method generates a large number of new instances misclassified with a wide variation in confidence, providing a rich new source of training data to create more robust models.
Identifying Easy Instances to Improve Efficiency of ML Pipelines for Algorithm-Selection
Jun 24, 2024Algorithm-selection (AS) methods are essential in order to obtain the best performance from a portfolio of solvers over large sets of instances. However, many AS methods rely on an analysis phase, e.g. where features are computed by sampling solutions and used as input in a machine-learning model. For AS to be efficient, it is therefore important that this analysis phase is not computationally expensive. We propose a method for identifying easy instances which can be solved quickly using a generalist solver without any need for algorithm-selection. This saves computational budget associated with feature-computation which can then be used elsewhere in an AS pipeline, e.g., enabling additional function evaluations on hard problems. Experiments on the BBOB dataset in two settings (batch and streaming) show that identifying easy instances results in substantial savings in function evaluations. Re-allocating the saved budget to hard problems provides gains in performance compared to both the virtual best solver (VBS) computed with the original budget, the single best solver (SBS) and a trained algorithm-selector.
Paired Autoencoders for Inverse Problems
May 21, 2024



We consider the solution of nonlinear inverse problems where the forward problem is a discretization of a partial differential equation. Such problems are notoriously difficult to solve in practice and require minimizing a combination of a data-fit term and a regularization term. The main computational bottleneck of typical algorithms is the direct estimation of the data misfit. Therefore, likelihood-free approaches have become appealing alternatives. Nonetheless, difficulties in generalization and limitations in accuracy have hindered their broader utility and applicability. In this work, we use a paired autoencoder framework as a likelihood-free estimator for inverse problems. We show that the use of such an architecture allows us to construct a solution efficiently and to overcome some known open problems when using likelihood-free estimators. In particular, our framework can assess the quality of the solution and improve on it if needed. We demonstrate the viability of our approach using examples from full waveform inversion and inverse electromagnetic imaging.
Improving Algorithm-Selection and Performance-Prediction via Learning Discriminating Training Samples
Apr 08, 2024The choice of input-data used to train algorithm-selection models is recognised as being a critical part of the model success. Recently, feature-free methods for algorithm-selection that use short trajectories obtained from running a solver as input have shown promise. However, it is unclear to what extent these trajectories reliably discriminate between solvers. We propose a meta approach to generating discriminatory trajectories with respect to a portfolio of solvers. The algorithm-configuration tool irace is used to tune the parameters of a simple Simulated Annealing algorithm (SA) to produce trajectories that maximise the performance metrics of ML models trained on this data. We show that when the trajectories obtained from the tuned SA algorithm are used in ML models for algorithm-selection and performance prediction, we obtain significantly improved performance metrics compared to models trained both on raw trajectory data and on exploratory landscape features.