 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Sparse Paired Autoencoders (vsPAIR) for Inverse Problems and Uncertainty Quantification
Feb 03, 2026Inverse problems are fundamental to many scientific and engineering disciplines; they arise when one seeks to reconstruct hidden, underlying quantities from noisy measurements. Many applications demand not just point estimates but interpretable uncertainty. Providing fast inference alongside uncertainty estimates remains challenging yet desirable in numerous applications. We propose the Variational Sparse Paired Autoencoder (vsPAIR) to address this challenge. The architecture pairs a standard VAE encoding observations with a sparse VAE encoding quantities of interest, connected through a learned latent mapping. The variational structure enables uncertainty estimation, the paired architecture encourages interpretability by anchoring QoI representations to clean data, and sparse encodings provide structure by concentrating information into identifiable factors rather than diffusing across all dimensions. We also propose modifications to existing sparse VAE methods: a hard-concrete spike-and-slab relaxation for differentiable training and a beta hyperprior for adaptive sparsity levels. To validate the effectiveness of our proposed architecture, we conduct experiments on blind inpainting and computed tomography, demonstrating that vsPAIR is a capable inverse problem solver that can provide interpretable and structured uncertainty estimates.
Latent Space Inference via Paired Autoencoders
Jan 16, 2026This work describes a novel data-driven latent space inference framework built on paired autoencoders to handle observational inconsistencies when solving inverse problems. Our approach uses two autoencoders, one for the parameter space and one for the observation space, connected by learned mappings between the autoencoders' latent spaces. These mappings enable a surrogate for regularized inversion and optimization in low-dimensional, informative latent spaces. Our flexible framework can work with partial, noisy, or out-of-distribution data, all while maintaining consistency with the underlying physical models. The paired autoencoders enable reconstruction of corrupted data, and then use the reconstructed data for parameter estimation, which produces more accurate reconstructions compared to paired autoencoders alone and end-to-end encoder-decoders of the same architecture, especially in scenarios with data inconsistencies. We demonstrate our approaches on two imaging examples in medical tomography and geophysical seismic-waveform inversion, but the described approaches are broadly applicable to a variety of inverse problems in scientific and engineering applications.
Neural Optimal Design of Experiment for Inverse Problems
Dec 28, 2025We introduce Neural Optimal Design of Experiments, a learning-based framework for optimal experimental design in inverse problems that avoids classical bilevel optimization and indirect sparsity regularization. NODE jointly trains a neural reconstruction model and a fixed-budget set of continuous design variables representing sensor locations, sampling times, or measurement angles, within a single optimization loop. By optimizing measurement locations directly rather than weighting a dense grid of candidates, the proposed approach enforces sparsity by design, eliminates the need for l1 tuning, and substantially reduces computational complexity. We validate NODE on an analytically tractable exponential growth benchmark, on MNIST image sampling, and illustrate its effectiveness on a real world sparse view X ray CT example. In all cases, NODE outperforms baseline approaches, demonstrating improved reconstruction accuracy and task-specific performance.
Good Things Come in Pairs: Paired Autoencoders for Inverse Problems
May 10, 2025



In this book chapter, we discuss recent advances in data-driven approaches for inverse problems. In particular, we focus on the \emph{paired autoencoder} framework, which has proven to be a powerful tool for solving inverse problems in scientific computing. The paired autoencoder framework is a novel approach that leverages the strengths of both data-driven and model-based methods by projecting both the data and the quantity of interest into a latent space and mapping these latent spaces to provide surrogate forward and inverse mappings. We illustrate the advantages of this approach through numerical experiments, including seismic imaging and classical inpainting: nonlinear and linear inverse problems, respectively. Although the paired autoencoder framework is likelihood-free, it generates multiple data- and model-based reconstruction metrics that help assess whether examples are in or out of distribution. In addition to direct model estimates from data, the paired autoencoder enables latent-space refinement to fit the observed data accurately. Numerical experiments show that this procedure, combined with the latent-space initial guess, is essential for high-quality estimates, even when data noise exceeds the training regime. We also introduce two novel variants that combine variational and paired autoencoder ideas, maintaining the original benefits while enabling sampling for uncertainty analysis.
Fast $\ell_1$-Regularized EEG Source Localization Using Variable Projection
Feb 27, 2025Electroencephalograms (EEG) are invaluable for treating neurological disorders, however, mapping EEG electrode readings to brain activity requires solving a challenging inverse problem. Due to the time series data, the use of $\ell_1$ regularization quickly becomes intractable for many solvers, and, despite the reconstruction advantages of $\ell_1$ regularization, $\ell_2$-based approaches such as sLORETA are used in practice. In this work, we formulate EEG source localization as a graphical generalized elastic net inverse problem and present a variable projected algorithm (VPAL) suitable for fast EEG source localization. We prove convergence of this solver for a broad class of separable convex, potentially non-smooth functions subject to linear constraints and include a modification of VPAL that reconstructs time points in sequence, suitable for real-time reconstruction. Our proposed methods are compared to state-of-the-art approaches including sLORETA and other methods for $\ell_1$-regularized inverse problems.
A Paired Autoencoder Framework for Inverse Problems via Bayes Risk Minimization
Jan 24, 2025In this work, we describe a new data-driven approach for inverse problems that exploits technologies from machine learning, in particular autoencoder network structures. We consider a paired autoencoder framework, where two autoencoders are used to efficiently represent the input and target spaces separately and optimal mappings are learned between latent spaces, thus enabling forward and inverse surrogate mappings. We focus on interpretations using Bayes risk and empirical Bayes risk minimization, and we provide various theoretical results and connections to existing works on low-rank matrix approximations. Similar to end-to-end approaches, our paired approach creates a surrogate model for forward propagation and regularized inversion. However, our approach outperforms existing approaches in scenarios where training data for unsupervised learning are readily available but training pairs for supervised learning are scarce. Furthermore, we show that cheaply computable evaluation metrics are available through this framework and can be used to predict whether the solution for a new sample should be predicted well.
Paired Wasserstein Autoencoders for Conditional Sampling
Dec 10, 2024


Wasserstein distances greatly influenced and coined various types of generative neural network models. Wasserstein autoencoders are particularly notable for their mathematical simplicity and straight-forward implementation. However, their adaptation to the conditional case displays theoretical difficulties. As a remedy, we propose the use of two paired autoencoders. Under the assumption of an optimal autoencoder pair, we leverage the pairwise independence condition of our prescribed Gaussian latent distribution to overcome this theoretical hurdle. We conduct several experiments to showcase the practical applicability of the resulting paired Wasserstein autoencoders. Here, we consider imaging tasks and enable conditional sampling for denoising, inpainting, and unsupervised image translation. Moreover, we connect our image translation model to the Monge map behind Wasserstein-2 distances.
Sparse $L^1$-Autoencoders for Scientific Data Compression
May 23, 2024
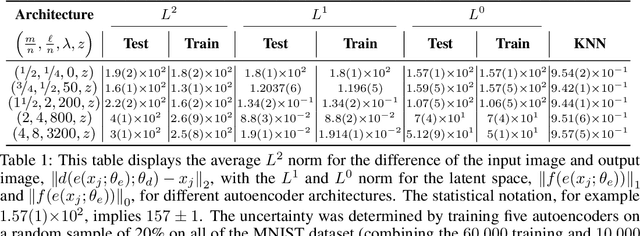
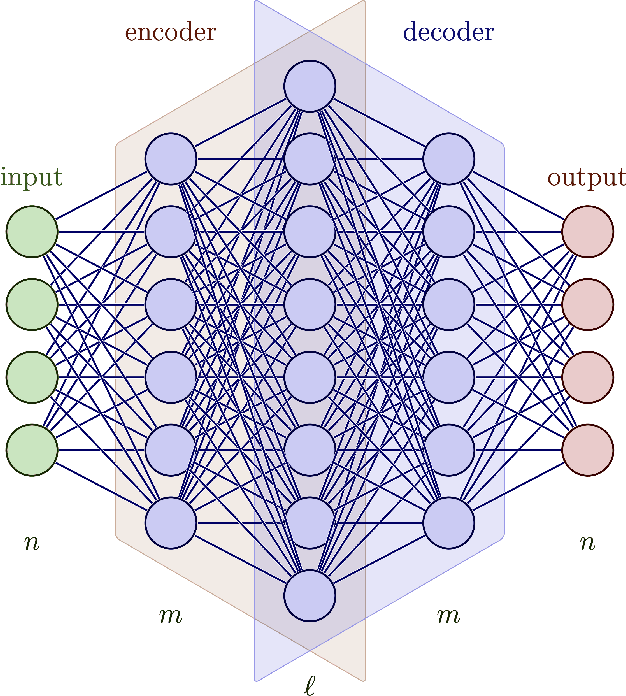
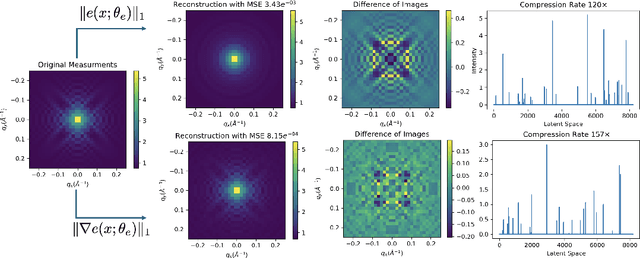
Scientific datasets present unique challenges for machine learning-driven compression methods, including more stringent requirements on accuracy and mitigation of potential invalidating artifacts. Drawing on results from compressed sensing and rate-distortion theory, we introduce effective data compression methods by developing autoencoders using high dimensional latent spaces that are $L^1$-regularized to obtain sparse low dimensional representations. We show how these information-rich latent spaces can be used to mitigate blurring and other artifacts to obtain highly effective data compression methods for scientific data. We demonstrate our methods for short angle scattering (SAS) datasets showing they can achieve compression ratios around two orders of magnitude and in some cases better. Our compression methods show promise for use in addressing current bottlenecks in transmission, storage, and analysis in high-performance distributed computing environments. This is central to processing the large volume of SAS data being generated at shared experimental facilities around the world to support scientific investigations. Our approaches provide general ways for obtaining specialized compression methods for targeted scientific datasets.
Paired Autoencoders for Inverse Problems
May 21, 2024



We consider the solution of nonlinear inverse problems where the forward problem is a discretization of a partial differential equation. Such problems are notoriously difficult to solve in practice and require minimizing a combination of a data-fit term and a regularization term. The main computational bottleneck of typical algorithms is the direct estimation of the data misfit. Therefore, likelihood-free approaches have become appealing alternatives. Nonetheless, difficulties in generalization and limitations in accuracy have hindered their broader utility and applicability. In this work, we use a paired autoencoder framework as a likelihood-free estimator for inverse problems. We show that the use of such an architecture allows us to construct a solution efficiently and to overcome some known open problems when using likelihood-free estimators. In particular, our framework can assess the quality of the solution and improve on it if needed. We demonstrate the viability of our approach using examples from full waveform inversion and inverse electromagnetic imaging.
Goal-oriented Uncertainty Quantification for Inverse Problems via Variational Encoder-Decoder Networks
Apr 17, 2023In this work, we describe a new approach that uses variational encoder-decoder (VED) networks for efficient goal-oriented uncertainty quantification for inverse problems. Contrary to standard inverse problems, these approaches are \emph{goal-oriented} in that the goal is to estimate some quantities of interest (QoI) that are functions of the solution of an inverse problem, rather than the solution itself. Moreover, we are interested in computing uncertainty metrics associated with the QoI, thus utilizing a Bayesian approach for inverse problems that incorporates the prediction operator and techniques for exploring the posterior. This may be particularly challenging, especially for nonlinear, possibly unknown, operators and nonstandard prior assumptions. We harness recent advances in machine learning, i.e., VED networks, to describe a data-driven approach to large-scale inverse problems. This enables a real-time goal-oriented uncertainty quantification for the QoI. One of the advantages of our approach is that we avoid the need to solve challenging inversion problems by training a network to approximate the mapping from observations to QoI. Another main benefit is that we enable uncertainty quantification for the QoI by leveraging probability distributions in the latent space. This allows us to efficiently generate QoI samples and circumvent complicated or even unknown forward models and prediction operators. Numerical results from medical tomography reconstruction and nonlinear hydraulic tomography demonstrate the potential and broad applicability of the approach.