 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-Aware Perturbations for Constrained Generative Modeling
Jan 30, 2026Generative models have enjoyed widespread success in a variety of applications. However, they encounter inherent mathematical limitations in modeling distributions where samples are constrained by equalities, as is frequently the setting in scientific domains. In this work, we develop a computationally cheap, mathematically justified, and highly flexible distributional modification for combating known pitfalls in equality-constrained generative models. We propose perturbing the data distribution in a constraint-aware way such that the new distribution has support matching the ambient space dimension while still implicitly incorporating underlying manifold geometry. Through theoretical analyses and empirical evidence on several representative tasks, we illustrate that our approach consistently enables data distribution recovery and stable sampling with both diffusion models and normalizing flows.
Weight-Parameterization in Continuous Time Deep Neural Networks for Surrogate Modeling
Jul 29, 2025Continuous-time deep learning models, such as neural ordinary differential equations (ODEs), offer a promising framework for surrogate modeling of complex physical systems. A central challenge in training these models lies in learning expressive yet stable time-varying weights, particularly under computational constraints. This work investigates weight parameterization strategies that constrain the temporal evolution of weights to a low-dimensional subspace spanned by polynomial basis functions. We evaluate both monomial and Legendre polynomial bases within neural ODE and residual network (ResNet) architectures under discretize-then-optimize and optimize-then-discretize training paradigms. Experimental results across three high-dimensional benchmark problems show that Legendre parameterizations yield more stable training dynamics, reduce computational cost, and achieve accuracy comparable to or better than both monomial parameterizations and unconstrained weight models. These findings elucidate the role of basis choice in time-dependent weight parameterization and demonstrate that using orthogonal polynomial bases offers a favorable tradeoff between model expressivity and training efficiency.
PyHySCO: GPU-Enabled Susceptibility Artifact Distortion Correction in Seconds
Mar 15, 2024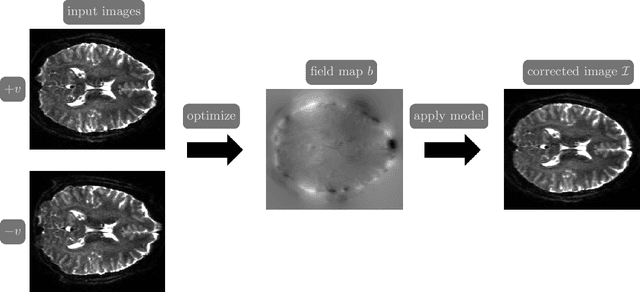

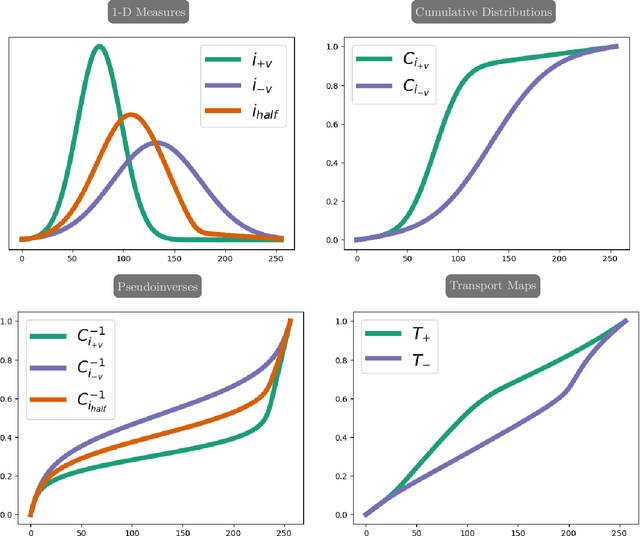
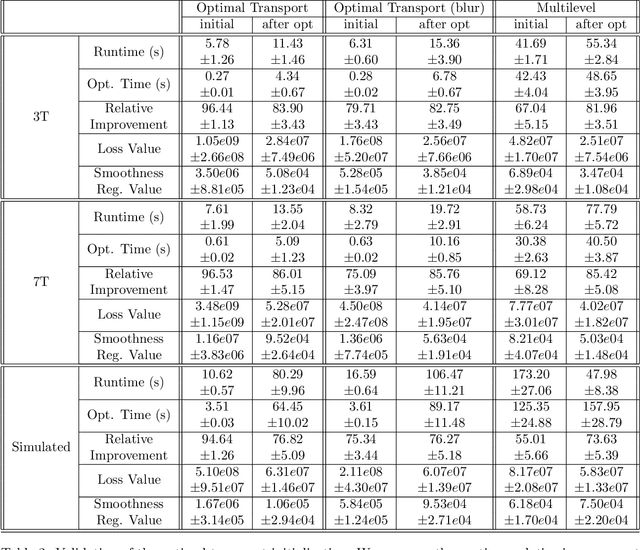
Over the past decade, reversed Gradient Polarity (RGP) methods have become a popular approach for correcting susceptibility artifacts in Echo-Planar Imaging (EPI). Although several post-processing tools for RGP are available, their implementations do not fully leverage recent hardware, algorithmic, and computational advances, leading to correction times of several minutes per image volume. To enable 3D RGP correction in seconds, we introduce PyHySCO, a user-friendly EPI distortion correction tool implemented in PyTorch that enables multi-threading and efficient use of graphics processing units (GPUs). PyHySCO uses a time-tested physical distortion model and mathematical formulation and is, therefore, reliable without training. An algorithmic improvement in PyHySCO is its novel initialization scheme that uses 1D optimal transport. PyHySCO is published under the GNU public license and can be used from the command line or its Python interface. Our extensive numerical validation using 3T and 7T data from the Human Connectome Project suggests that PyHySCO achieves accuracy comparable to that of leading RGP tools at a fraction of the cost. We also validate the new initialization scheme, compare different optimization algorithms, and test the algorithm on different hardware and arithmetic precision.
Differential Equations for Continuous-Time Deep Learning
Jan 08, 2024
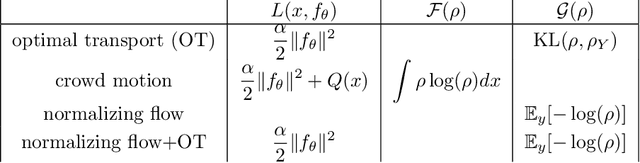
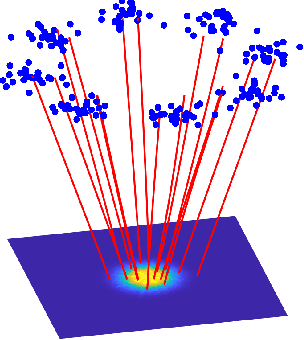
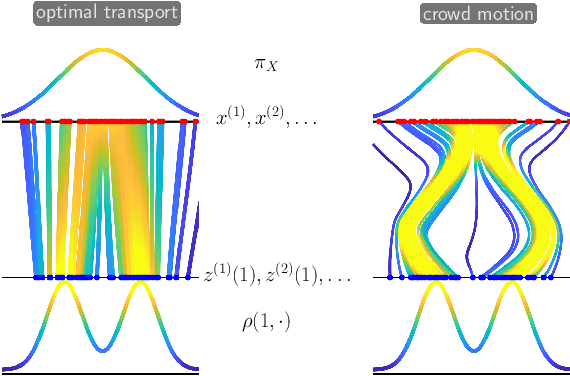
This short, self-contained article seeks to introduce and survey continuous-time deep learning approaches that are based on neural ordinary differential equations (neural ODEs). It primarily targets readers familiar with ordinary and partial differential equations and their analysis who are curious to see their role in machine learning. Using three examples from machine learning and applied mathematics, we will see how neural ODEs can provide new insights into deep learning and a foundation for more efficient algorithms.
Learning Control Policies of Hodgkin-Huxley Neuronal Dynamics
Nov 13, 2023



We present a neural network approach for closed-loop deep brain stimulation (DBS). We cast the problem of finding an optimal neurostimulation strategy as a control problem. In this setting, control policies aim to optimize therapeutic outcomes by tailoring the parameters of a DBS system, typically via electrical stimulation, in real time based on the patient's ongoing neuronal activity. We approximate the value function offline using a neural network to enable generating controls (stimuli) in real time via the feedback form. The neuronal activity is characterized by a nonlinear, stiff system of differential equations as dictated by the Hodgkin-Huxley model. Our training process leverages the relationship between Pontryagin's maximum principle and Hamilton-Jacobi-Bellman equations to update the value function estimates simultaneously. Our numerical experiments illustrate the accuracy of our approach for out-of-distribution samples and the robustness to moderate shocks and disturbances in the system.
Efficient Neural Network Approaches for Conditional Optimal Transport with Applications in Bayesian Inference
Oct 25, 2023We present two neural network approaches that approximate the solutions of static and dynamic conditional optimal transport (COT) problems, respectively. Both approaches enable sampling and density estimation of conditional probability distributions, which are core tasks in Bayesian inference. Our methods represent the target conditional distributions as transformations of a tractable reference distribution and, therefore, fall into the framework of measure transport. COT maps are a canonical choice within this framework, with desirable properties such as uniqueness and monotonicity. However, the associated COT problems are computationally challenging, even in moderate dimensions. To improve the scalability, our numerical algorithms leverage neural networks to parameterize COT maps. Our methods exploit the structure of the static and dynamic formulations of the COT problem. PCP-Map models conditional transport maps as the gradient of a partially input convex neural network (PICNN) and uses a novel numerical implementation to increase computational efficiency compared to state-of-the-art alternatives. COT-Flow models conditional transports via the flow of a regularized neural ODE; it is slower to train but offers faster sampling. We demonstrate their effectiveness and efficiency by comparing them with state-of-the-art approaches using benchmark datasets and Bayesian inverse problems.
Alternating Minimization for Regression with Tropical Rational Functions
May 31, 2023
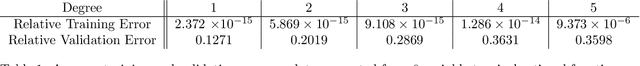
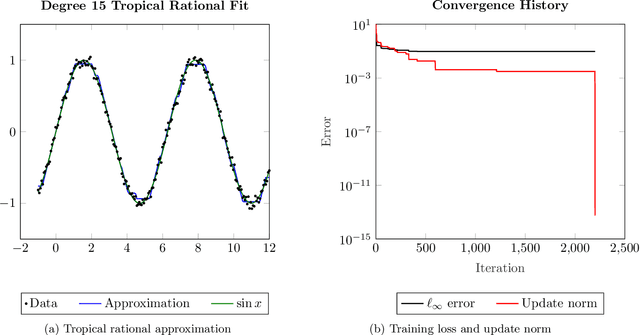
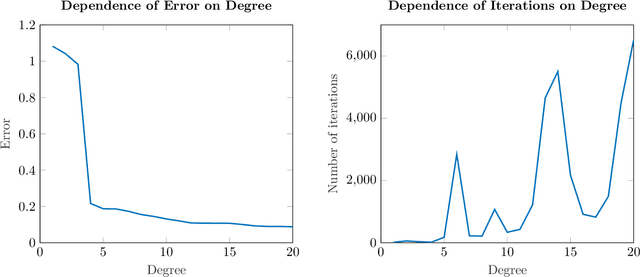
We propose an alternating minimization heuristic for regression over the space of tropical rational functions with fixed exponents. The method alternates between fitting the numerator and denominator terms via tropical polynomial regression, which is known to admit a closed form solution. We demonstrate the behavior of the alternating minimization method experimentally. Experiments demonstrate that the heuristic provides a reasonable approximation of the input data. Our work is motivated by applications to ReLU neural networks, a popular class of network architectures in the machine learning community which are closely related to tropical rational functions.
Multilevel Diffusion: Infinite Dimensional Score-Based Diffusion Models for Image Generation
Mar 08, 2023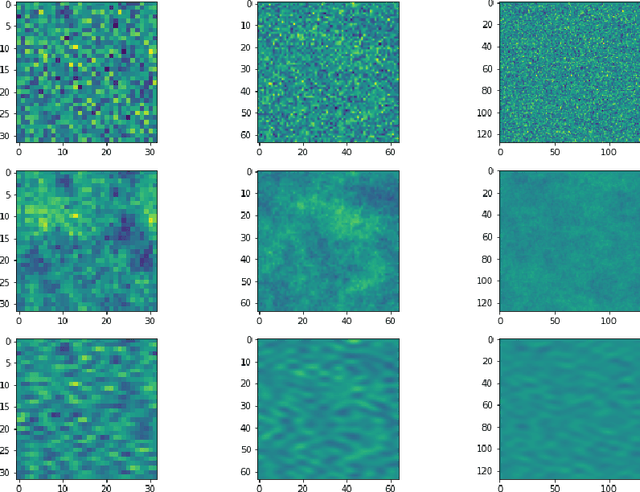



Score-based diffusion models (SBDM) have recently emerged as state-of-the-art approaches for image generation. Existing SBDMs are typically formulated in a finite-dimensional setting, where images are considered as tensors of a finite size. This papers develops SBDMs in the infinite-dimensional setting, that is, we model the training data as functions supported on a rectangular domain. Besides the quest for generating images at ever higher resolution our primary motivation is to create a well-posed infinite-dimensional learning problem so that we can discretize it consistently on multiple resolution levels. We thereby hope to obtain diffusion models that generalize across different resolution levels and improve the efficiency of the training process. We demonstrate how to overcome two shortcomings of current SBDM approaches in the infinite-dimensional setting. First, we modify the forward process to ensure that the latent distribution is well-defined in the infinite-dimensional setting using the notion of trace class operators. Second, we illustrate that approximating the score function with an operator network, in our case Fourier neural operators (FNOs), is beneficial for multilevel training. After deriving the forward and reverse process in the infinite-dimensional setting, we show their well-posedness, derive adequate discretizations, and investigate the role of the latent distributions. We provide first promising numerical results on two datasets, MNIST and material structures. In particular, we show that multilevel training is feasible within this framework.
$ω$GNNs: Deep Graph Neural Networks Enhanced by Multiple Propagation Operators
Oct 31, 2022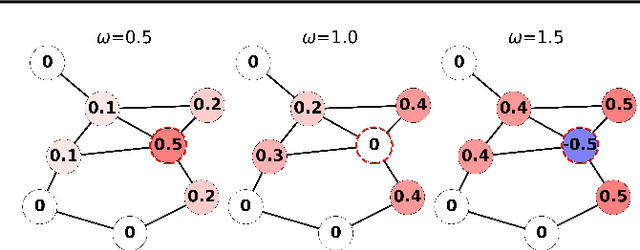

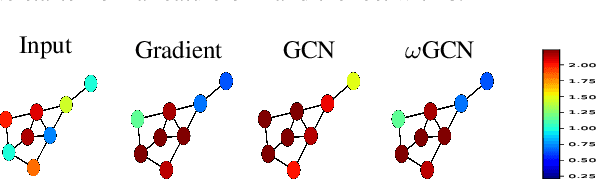
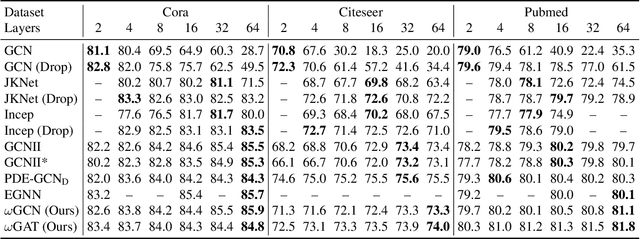
Graph Neural Networks (GNNs) are limited in their propagation operators. These operators often contain non-negative elements only and are shared across channels and layers, limiting the expressiveness of GNNs. Moreover, some GNNs suffer from over-smoothing, limiting their depth. On the other hand, Convolutional Neural Networks (CNNs) can learn diverse propagation filters, and phenomena like over-smoothing are typically not apparent in CNNs. In this paper, we bridge this gap by incorporating trainable channel-wise weighting factors $\omega$ to learn and mix multiple smoothing and sharpening propagation operators at each layer. Our generic method is called $\omega$GNN, and we study two variants: $\omega$GCN and $\omega$GAT. For $\omega$GCN, we theoretically analyse its behaviour and the impact of $\omega$ on the obtained node features. Our experiments confirm these findings, demonstrating and explaining how both variants do not over-smooth. Additionally, we experiment with 15 real-world datasets on node- and graph-classification tasks, where our $\omega$GCN and $\omega$GAT perform better or on par with state-of-the-art methods.
Multivariate Quantile Function Forecaster
Feb 23, 2022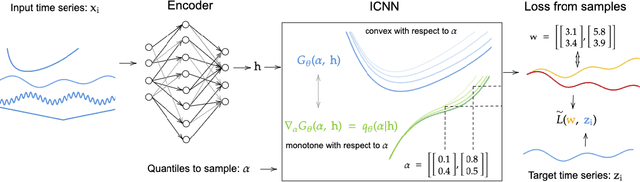
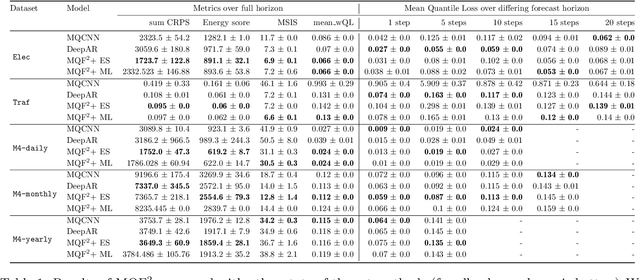
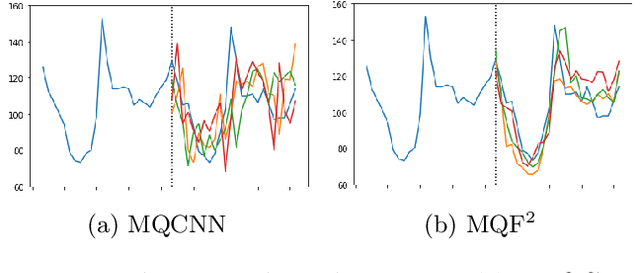
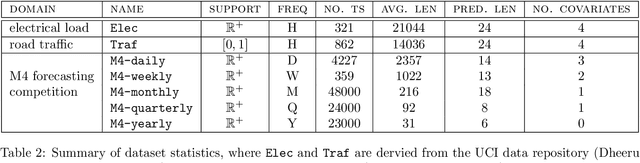
We propose Multivariate Quantile Function Forecaster (MQF$^2$), a global probabilistic forecasting method constructed using a multivariate quantile function and investigate its application to multi-horizon forecasting. Prior approaches are either autoregressive, implicitly capturing the dependency structure across time but exhibiting error accumulation with increasing forecast horizons, or multi-horizon sequence-to-sequence models, which do not exhibit error accumulation, but also do typically not model the dependency structure across time steps. MQF$^2$ combines the benefits of both approaches, by directly making predictions in the form of a multivariate quantile function, defined as the gradient of a convex function which we parametrize using input-convex neural networks. By design, the quantile function is monotone with respect to the input quantile levels and hence avoids quantile crossing. We provide two options to train MQF$^2$: with energy score or with maximum likelihood. Experimental results on real-world and synthetic datasets show that our model has comparable performance with state-of-the-art methods in terms of single time step metrics while capturing the time dependency structure.