 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoost Like a (Var)Pro: Trust-Region Gradient Boosting via Variable Projection
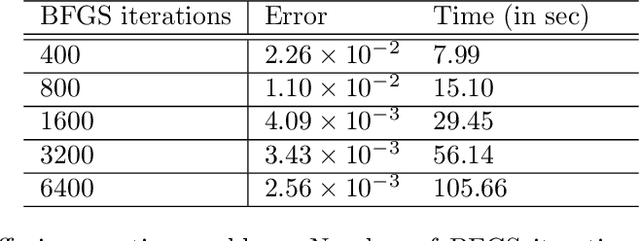
Mar 24, 2026Gradient boosting, a method of building additive ensembles from weak learners, has established itself as a practical and theoretically-motivated approach to approximate functions, especially using decision tree weak learners. Comparable methods for smooth parametric learners, such as neural networks, remain less developed in both training methodology and theory. To this end, we introduce \texttt{VPBoost} ({\bf V}ariable {\bf P}rojection {\bf Boost}ing), a gradient boosting algorithm for separable smooth approximators, i.e., models with a smooth nonlinear featurizer followed by a final linear mapping. \texttt{VPBoost} fuses variable projection, a training paradigm for separable models that enforces optimality of the linear weights, with a second-order weak learning strategy. The combination of second-order boosting, separable models, and variable projection give rise to a closed-form solution for the optimal linear weights and a natural interpretation of \VPBoost as a functional trust-region method. We thereby leverage trust-region theory to prove \VPBoost converges to a stationary point under mild geometric conditions and, under stronger assumptions, achieves a superlinear convergence rate. Comprehensive numerical experiments on synthetic data, image recognition, and scientific machine learning benchmarks demonstrate that \VPBoost learns an ensemble with improved evaluation metrics in comparison to gradient-descent-based boosting and attains competitive performance relative to an industry-standard decision tree boosting algorithm.
On the Convergence of Jacobian-Free Backpropagation for Optimal Control Problems with Implicit Hamiltonians
Jan 31, 2026Optimal feedback control with implicit Hamiltonians poses a fundamental challenge for learning-based value function methods due to the absence of closed-form optimal control laws. Recent work~\cite{gelphman2025end} introduced an implicit deep learning approach using Jacobian-Free Backpropagation (JFB) to address this setting, but only established sample-wise descent guarantees. In this paper, we establish convergence guarantees for JFB in the stochastic minibatch setting, showing that the resulting updates converge to stationary points of the expected optimal control objective. We further demonstrate scalability on substantially higher-dimensional problems, including multi-agent optimal consumption and swarm-based quadrotor and bicycle control. Together, our results provide both theoretical justification and empirical evidence for using JFB in high-dimensional optimal control with implicit Hamiltonians.
Learning Control Policies of Hodgkin-Huxley Neuronal Dynamics
Nov 13, 2023



We present a neural network approach for closed-loop deep brain stimulation (DBS). We cast the problem of finding an optimal neurostimulation strategy as a control problem. In this setting, control policies aim to optimize therapeutic outcomes by tailoring the parameters of a DBS system, typically via electrical stimulation, in real time based on the patient's ongoing neuronal activity. We approximate the value function offline using a neural network to enable generating controls (stimuli) in real time via the feedback form. The neuronal activity is characterized by a nonlinear, stiff system of differential equations as dictated by the Hodgkin-Huxley model. Our training process leverages the relationship between Pontryagin's maximum principle and Hamilton-Jacobi-Bellman equations to update the value function estimates simultaneously. Our numerical experiments illustrate the accuracy of our approach for out-of-distribution samples and the robustness to moderate shocks and disturbances in the system.
Efficient Neural Network Approaches for Conditional Optimal Transport with Applications in Bayesian Inference
Oct 25, 2023We present two neural network approaches that approximate the solutions of static and dynamic conditional optimal transport (COT) problems, respectively. Both approaches enable sampling and density estimation of conditional probability distributions, which are core tasks in Bayesian inference. Our methods represent the target conditional distributions as transformations of a tractable reference distribution and, therefore, fall into the framework of measure transport. COT maps are a canonical choice within this framework, with desirable properties such as uniqueness and monotonicity. However, the associated COT problems are computationally challenging, even in moderate dimensions. To improve the scalability, our numerical algorithms leverage neural networks to parameterize COT maps. Our methods exploit the structure of the static and dynamic formulations of the COT problem. PCP-Map models conditional transport maps as the gradient of a partially input convex neural network (PICNN) and uses a novel numerical implementation to increase computational efficiency compared to state-of-the-art alternatives. COT-Flow models conditional transports via the flow of a regularized neural ODE; it is slower to train but offers faster sampling. We demonstrate their effectiveness and efficiency by comparing them with state-of-the-art approaches using benchmark datasets and Bayesian inverse problems.
Novel DNNs for Stiff ODEs with Applications to Chemically Reacting Flows
Apr 01, 2021



Chemically reacting flows are common in engineering, such as hypersonic flow, combustion, explosions, manufacturing processes and environmental assessments. For combustion, the number of reactions can be significant (over 100) and due to the very large CPU requirements of chemical reactions (over 99%) a large number of flow and combustion problems are presently beyond the capabilities of even the largest supercomputers. Motivated by this, novel Deep Neural Networks (DNNs) are introduced to approximate stiff ODEs. Two approaches are compared, i.e., either learn the solution or the derivative of the solution to these ODEs. These DNNs are applied to multiple species and reactions common in chemically reacting flows. Experimental results show that it is helpful to account for the physical properties of species while designing DNNs. The proposed approach is shown to generalize well.
Novel Deep neural networks for solving Bayesian statistical inverse
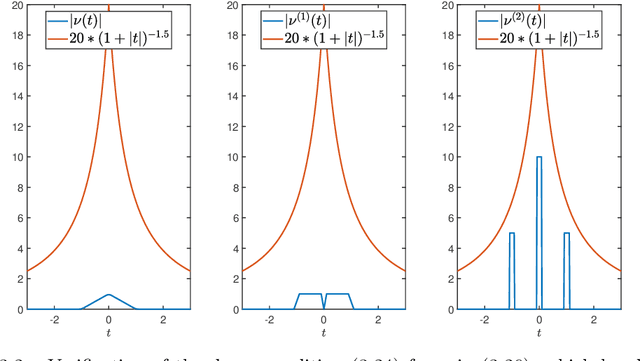
Feb 08, 2021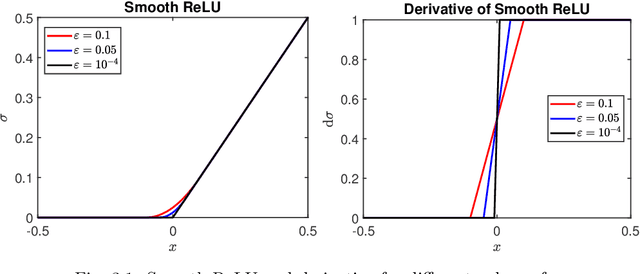
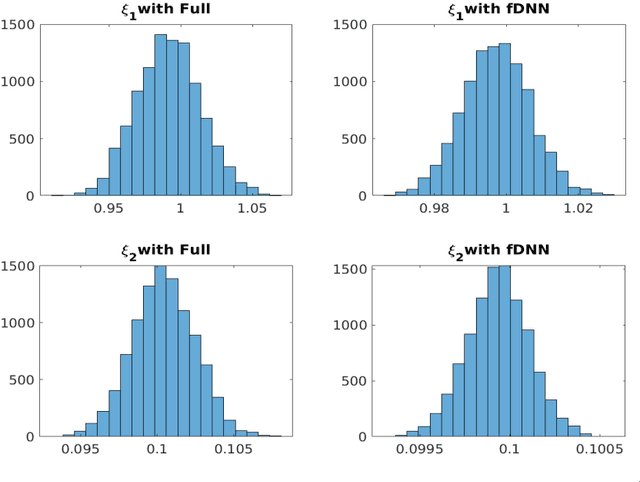
We consider the simulation of Bayesian statistical inverse problems governed by large-scale linear and nonlinear partial differential equations (PDEs). Markov chain Monte Carlo (MCMC) algorithms are standard techniques to solve such problems. However, MCMC techniques are computationally challenging as they require several thousands of forward PDE solves. The goal of this paper is to introduce a fractional deep neural network based approach for the forward solves within an MCMC routine. Moreover, we discuss some approximation error estimates and illustrate the efficiency of our approach via several numerical examples.
Fractional Deep Neural Network via Constrained Optimization
Apr 01, 2020


This paper introduces a novel algorithmic framework for a deep neural network (DNN), which in a mathematically rigorous manner, allows us to incorporate history (or memory) into the network -- it ensures all layers are connected to one another. This DNN, called Fractional-DNN, can be viewed as a time-discretization of a fractional in time nonlinear ordinary differential equation (ODE). The learning problem then is a minimization problem subject to that fractional ODE as constraints. We emphasize that an analogy between the existing DNN and ODEs, with standard time derivative, is well-known by now. The focus of our work is the Fractional-DNN. Using the Lagrangian approach, we provide a derivation of the backward propagation and the design equations. We test our network on several datasets for classification problems. Fractional-DNN offers various advantages over the existing DNN. The key benefits are a significant improvement to the vanishing gradient issue due to the memory effect, and better handling of nonsmooth data due to the network's ability to approximate non-smooth functions.