 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStein Kernelized Molecular Dynamics for Active Learning of Interatomic Potentials
Jun 02, 2026Machine learning interatomic potentials (MLIPs) enable efficient and accurate atomistic simulations but depend critically on the quality and diversity of the training data. We introduce Stein kernelized molecular dynamics (SKMD), an enhanced sampling method that uses interacting particle dynamics to acquire informative training configurations for the active learning and fine-tuning of MLIPs. SKMD corresponds to a stochastic variant of Stein variational gradient descent that is adapted for molecular dynamics by incorporating asynchronous particle updates and a kernel of global atomic descriptors, which provides a symmetry-aware measure of configurational similarity. Unlike other enhanced samplers used in molecular dynamics, SKMD preserves the Boltzmann distribution as the asymptotic distribution of the dynamics. This property enforces a balance between the exploration of diverse configurations and attraction toward high-probability regions of the energy landscape. We further propose an approach to efficient online data acquisition using an adaptive stopping criterion that selects non-redundant training data over the course of simulation. We demonstrate SKMD for the active learning of a neural network model of the Müller-Brown potential and the fine-tuning of a MACE interatomic potential for alanine dipeptide. Compared to active learning baselines, our method achieves higher model accuracy in fewer training iterations with the same number of acquired training samples.
Data Curation for Machine Learning Interatomic Potentials by Determinantal Point Processes
Mar 23, 2026The development of machine learning interatomic potentials faces a critical computational bottleneck with the generation and labeling of useful training datasets. We present a novel application of determinantal point processes (DPPs) to the task of selecting informative subsets of atomic configurations to label with reference energies and forces from costly quantum mechanical methods. Through experiments with hafnium oxide data, we show that DPPs are competitive with existing approaches to constructing compact but diverse training sets by utilizing kernels of molecular descriptors, leading to improved accuracy and robustness in machine learning representations of molecular systems. Our work identifies promising directions to employ DPPs for unsupervised training data curation with heterogeneous or multimodal data, or in online active learning schemes for iterative data augmentation during molecular dynamics simulation.
* Original publication at https://openreview.net/forum?id=PKGP7tg65A
Goal-oriented learning of stochastic dynamical systems using error bounds on path-space observables
Mar 20, 2026The governing equations of stochastic dynamical systems often become cost-prohibitive for numerical simulation at large scales. Surrogate models of the governing equations, learned from data of the high-fidelity system, are routinely used to predict key observables with greater efficiency. However, standard choices of loss function for learning the surrogate model fail to provide error guarantees in path-dependent observables, such as reaction rates of molecular dynamical systems. This paper introduces an error bound for path-space observables and employs it as a novel variational loss for the goal-oriented learning of a stochastic dynamical system. We show the error bound holds for a broad class of observables, including mean first hitting times on unbounded time domains. We derive an analytical gradient of the goal-oriented loss function by leveraging the formula for Frechet derivatives of expected path functionals, which remains tractable for implementation in stochastic gradient descent schemes. We demonstrate that surrogate models of overdamped Langevin systems developed via goal-oriented learning achieve improved accuracy in predicting the statistics of a first hitting time observable and robustness to distributional shift in the data.
Conformal Prediction for Generative Models via Adaptive Cluster-Based Density Estimation
Jan 29, 2026Conditional generative models map input variables to complex, high-dimensional distributions, enabling realistic sample generation in a diverse set of domains. A critical challenge with these models is the absence of calibrated uncertainty, which undermines trust in individual outputs for high-stakes applications. To address this issue, we propose a systematic conformal prediction approach tailored to conditional generative models, leveraging density estimation on model-generated samples. We introduce a novel method called CP4Gen, which utilizes clustering-based density estimation to construct prediction sets that are less sensitive to outliers, more interpretable, and of lower structural complexity than existing methods. Extensive experiments on synthetic datasets and real-world applications, including climate emulation tasks, demonstrate that CP4Gen consistently achieves superior performance in terms of prediction set volume and structural simplicity. Our approach offers practitioners a powerful tool for uncertainty estimation associated with conditional generative models, particularly in scenarios demanding rigorous and interpretable prediction sets.
Generative Modeling through Spectral Analysis of Koopman Operator
Dec 21, 2025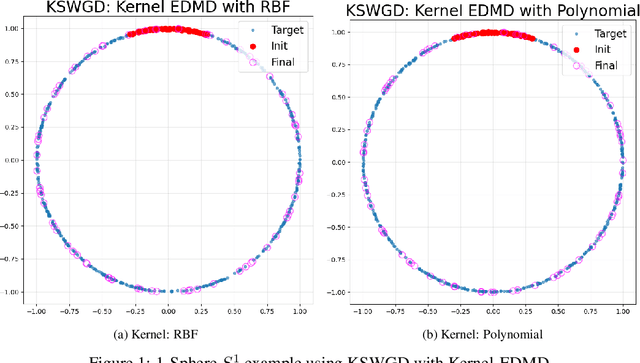
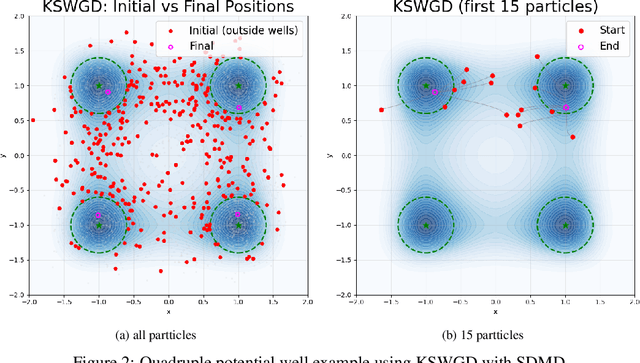

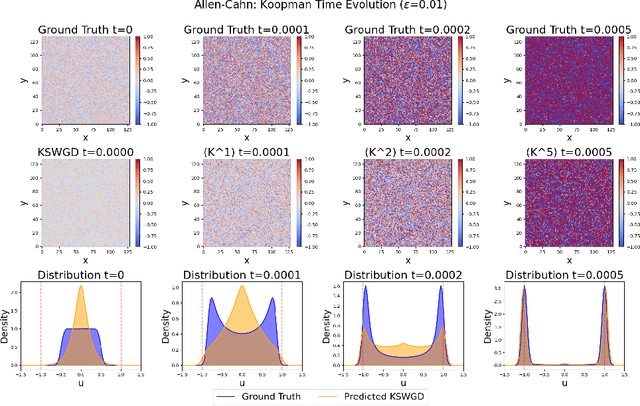
We propose Koopman Spectral Wasserstein Gradient Descent (KSWGD), a generative modeling framework that combines operator-theoretic spectral analysis with optimal transport. The novel insight is that the spectral structure required for accelerated Wasserstein gradient descent can be directly estimated from trajectory data via Koopman operator approximation which can eliminate the need for explicit knowledge of the target potential or neural network training. We provide rigorous convergence analysis and establish connection to Feynman-Kac theory that clarifies the method's probabilistic foundation. Experiments across diverse settings, including compact manifold sampling, metastable multi-well systems, image generation, and high dimensional stochastic partial differential equation, demonstrate that KSWGD consistently achieves faster convergence than other existing methods while maintaining high sample quality.
Learning Paths for Dynamic Measure Transport: A Control Perspective
Nov 05, 2025



We bring a control perspective to the problem of identifying paths of measures for sampling via dynamic measure transport (DMT). We highlight the fact that commonly used paths may be poor choices for DMT and connect existing methods for learning alternate paths to mean-field games. Based on these connections we pose a flexible family of optimization problems for identifying tilted paths of measures for DMT and advocate for the use of objective terms which encourage smoothness of the corresponding velocities. We present a numerical algorithm for solving these problems based on recent Gaussian process methods for solution of partial differential equations and demonstrate the ability of our method to recover more efficient and smooth transport models compared to those which use an untilted reference path.
Canonical Bayesian Linear System Identification
Jul 15, 2025



Standard Bayesian approaches for linear time-invariant (LTI) system identification are hindered by parameter non-identifiability; the resulting complex, multi-modal posteriors make inference inefficient and impractical. We solve this problem by embedding canonical forms of LTI systems within the Bayesian framework. We rigorously establish that inference in these minimal parameterizations fully captures all invariant system dynamics (e.g., transfer functions, eigenvalues, predictive distributions of system outputs) while resolving identifiability. This approach unlocks the use of meaningful, structure-aware priors (e.g., enforcing stability via eigenvalues) and ensures conditions for a Bernstein--von Mises theorem -- a link between Bayesian and frequentist large-sample asymptotics that is broken in standard forms. Extensive simulations with modern MCMC methods highlight advantages over standard parameterizations: canonical forms achieve higher computational efficiency, generate interpretable and well-behaved posteriors, and provide robust uncertainty estimates, particularly from limited data.
Localized Diffusion Models for High Dimensional Distributions Generation
May 07, 2025Diffusion models are the state-of-the-art tools for various generative tasks. However, estimating high-dimensional score functions makes them potentially suffer from the curse of dimensionality (CoD). This underscores the importance of better understanding and exploiting low-dimensional structure in the target distribution. In this work, we consider locality structure, which describes sparse dependencies between model components. Under locality structure, the score function is effectively low-dimensional, so that it can be estimated by a localized neural network with significantly reduced sample complexity. This motivates the localized diffusion model, where a localized score matching loss is used to train the score function within a localized hypothesis space. We prove that such localization enables diffusion models to circumvent CoD, at the price of additional localization error. Under realistic sample size scaling, we show both theoretically and numerically that a moderate localization radius can balance the statistical and localization error, leading to a better overall performance. The localized structure also facilitates parallel training of diffusion models, making it potentially more efficient for large-scale applications.
Optimal Scheduling of Dynamic Transport
Apr 19, 2025Flow-based methods for sampling and generative modeling use continuous-time dynamical systems to represent a {transport map} that pushes forward a source measure to a target measure. The introduction of a time axis provides considerable design freedom, and a central question is how to exploit this freedom. Though many popular methods seek straight line (i.e., zero acceleration) trajectories, we show here that a specific class of ``curved'' trajectories can significantly improve approximation and learning. In particular, we consider the unit-time interpolation of any given transport map $T$ and seek the schedule $\tau: [0,1] \to [0,1]$ that minimizes the spatial Lipschitz constant of the corresponding velocity field over all times $t \in [0,1]$. This quantity is crucial as it allows for control of the approximation error when the velocity field is learned from data. We show that, for a broad class of source/target measures and transport maps $T$, the \emph{optimal schedule} can be computed in closed form, and that the resulting optimal Lipschitz constant is \emph{exponentially smaller} than that induced by an identity schedule (corresponding to, for instance, the Wasserstein geodesic). Our proof technique relies on the calculus of variations and $\Gamma$-convergence, allowing us to approximate the aforementioned degenerate objective by a family of smooth, tractable problems.
A friendly introduction to triangular transport
Mar 27, 2025



Decision making under uncertainty is a cross-cutting challenge in science and engineering. Most approaches to this challenge employ probabilistic representations of uncertainty. In complicated systems accessible only via data or black-box models, however, these representations are rarely known. We discuss how to characterize and manipulate such representations using triangular transport maps, which approximate any complex probability distribution as a transformation of a simple, well-understood distribution. The particular structure of triangular transport guarantees many desirable mathematical and computational properties that translate well into solving practical problems. Triangular maps are actively used for density estimation, (conditional) generative modelling, Bayesian inference, data assimilation, optimal experimental design, and related tasks. While there is ample literature on the development and theory of triangular transport methods, this manuscript provides a detailed introduction for scientists interested in employing measure transport without assuming a formal mathematical background. We build intuition for the key foundations of triangular transport, discuss many aspects of its practical implementation, and outline the frontiers of this field.