 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Bayesian Neural Networks Make Confident Predictions?
Jan 20, 2025



Bayesian inference promises a framework for principled uncertainty quantification of neural network predictions. Barriers to adoption include the difficulty of fully characterizing posterior distributions on network parameters and the interpretability of posterior predictive distributions. We demonstrate that under a discretized prior for the inner layer weights, we can exactly characterize the posterior predictive distribution as a Gaussian mixture. This setting allows us to define equivalence classes of network parameter values which produce the same likelihood (training error) and to relate the elements of these classes to the network's scaling regime -- defined via ratios of the training sample size, the size of each layer, and the number of final layer parameters. Of particular interest are distinct parameter realizations that map to low training error and yet correspond to distinct modes in the posterior predictive distribution. We identify settings that exhibit such predictive multimodality, and thus provide insight into the accuracy of unimodal posterior approximations. We also characterize the capacity of a model to "learn from data" by evaluating contraction of the posterior predictive in different scaling regimes.
Multitask methods for predicting molecular properties from heterogeneous data
Jan 31, 2024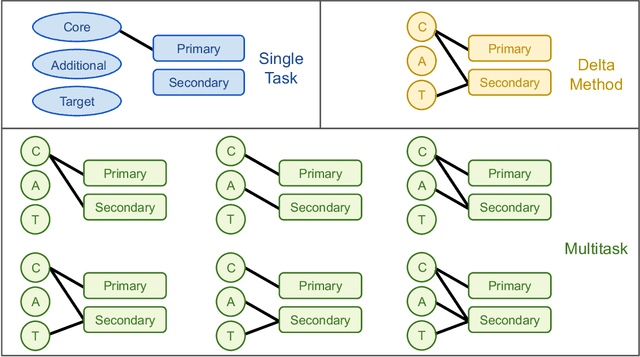
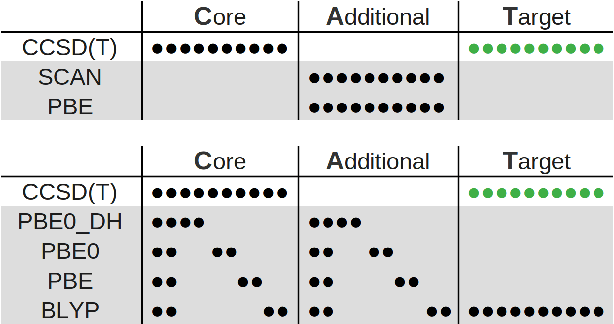
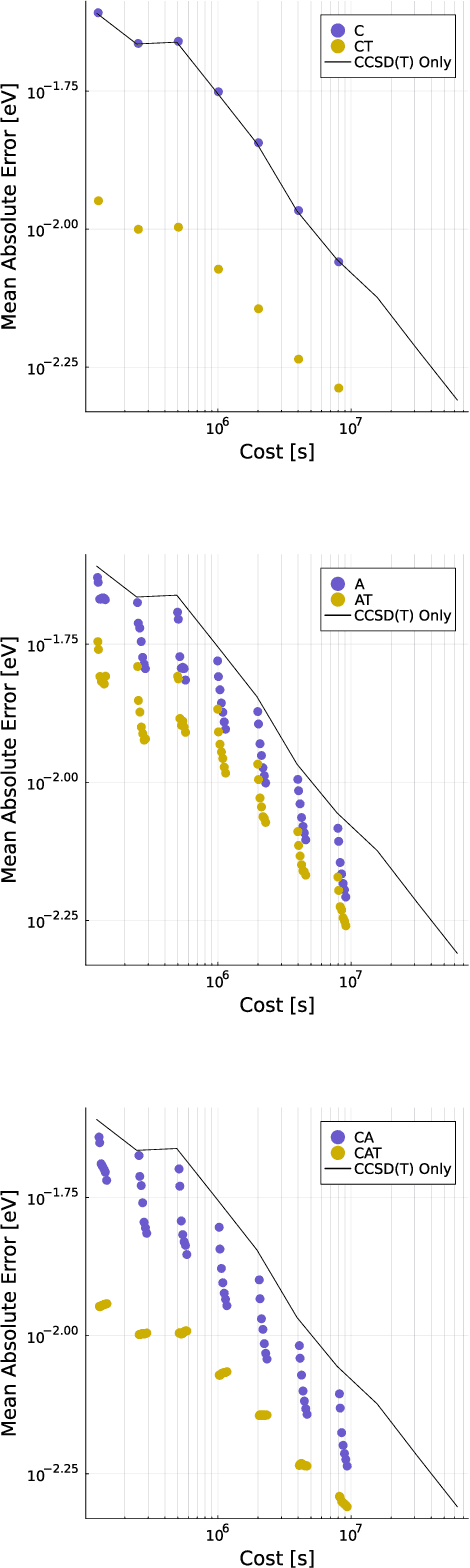
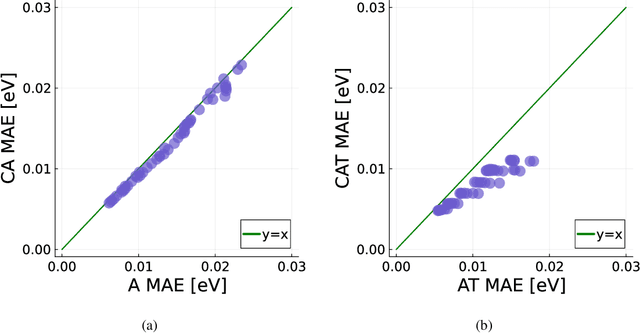
Data generation remains a bottleneck in training surrogate models to predict molecular properties. We demonstrate that multitask Gaussian process regression overcomes this limitation by leveraging both expensive and cheap data sources. In particular, we consider training sets constructed from coupled-cluster (CC) and density function theory (DFT) data. We report that multitask surrogates can predict at CC level accuracy with a reduction to data generation cost by over an order of magnitude. Of note, our approach allows the training set to include DFT data generated by a heterogeneous mix of exchange-correlation functionals without imposing any artificial hierarchy on functional accuracy. More generally, the multitask framework can accommodate a wider range of training set structures -- including full disparity between the different levels of fidelity -- than existing kernel approaches based on $\Delta$-learning, though we show that the accuracy of the two approaches can be similar. Consequently, multitask regression can be a tool for reducing data generation costs even further by opportunistically exploiting existing data sources.