 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask methods for predicting molecular properties from heterogeneous data
Paper and Code
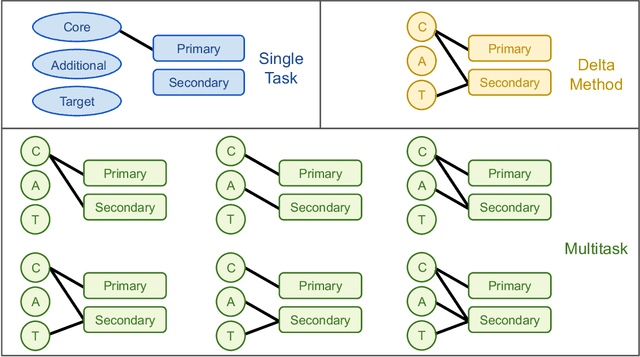
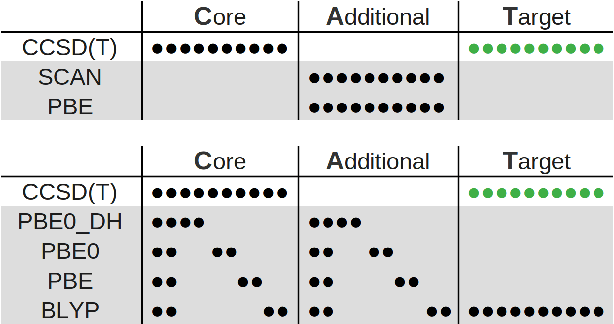
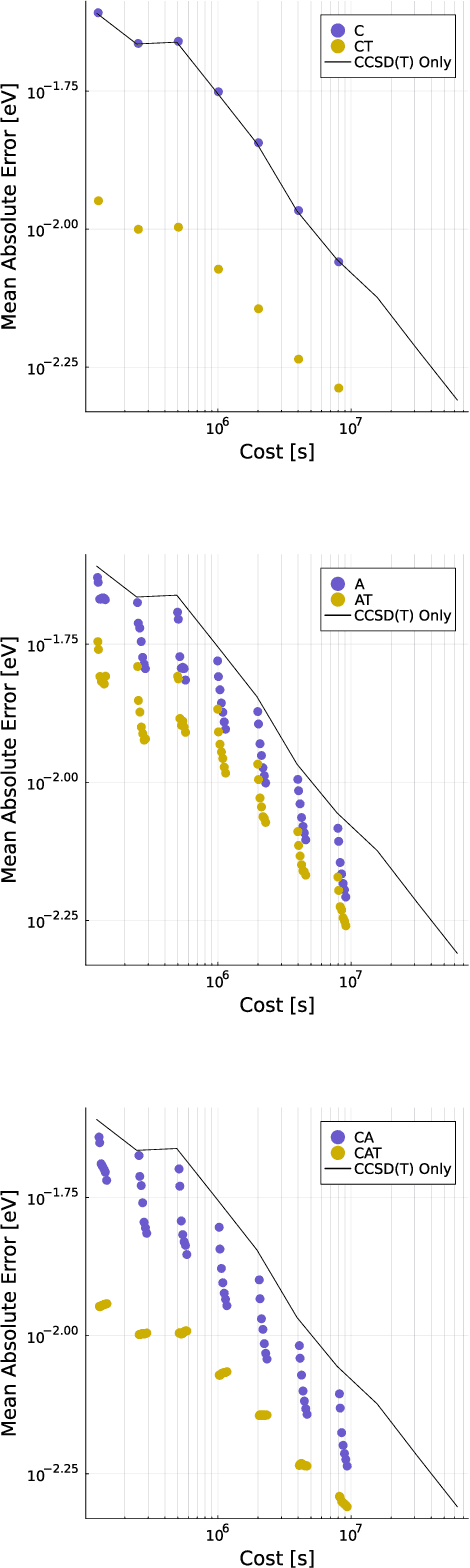
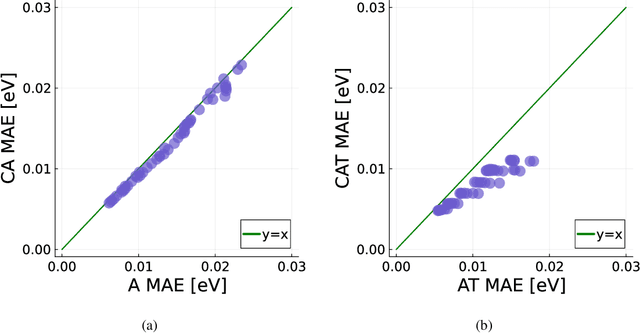
Data generation remains a bottleneck in training surrogate models to predict molecular properties. We demonstrate that multitask Gaussian process regression overcomes this limitation by leveraging both expensive and cheap data sources. In particular, we consider training sets constructed from coupled-cluster (CC) and density function theory (DFT) data. We report that multitask surrogates can predict at CC level accuracy with a reduction to data generation cost by over an order of magnitude. Of note, our approach allows the training set to include DFT data generated by a heterogeneous mix of exchange-correlation functionals without imposing any artificial hierarchy on functional accuracy. More generally, the multitask framework can accommodate a wider range of training set structures -- including full disparity between the different levels of fidelity -- than existing kernel approaches based on $\Delta$-learning, though we show that the accuracy of the two approaches can be similar. Consequently, multitask regression can be a tool for reducing data generation costs even further by opportunistically exploiting existing data sources.