 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Path Samplers via Sequential Monte Carlo
Jan 29, 2026We develop a diffusion-based sampler for target distributions known up to a normalising constant. To this end, we rely on the well-known diffusion path that smoothly interpolates between a (simple) base distribution and the target distribution, widely used in diffusion models. Our approach is based on a practical implementation of diffusion-annealed Langevin Monte Carlo, which approximates the diffusion path with convergence guarantees. We tackle the score estimation problem by developing an efficient sequential Monte Carlo sampler that evolves auxiliary variables from conditional distributions along the path, which provides principled score estimates for time-varying distributions. We further develop novel control variate schedules that minimise the variance of these score estimates. Finally, we provide theoretical guarantees and empirically demonstrate the effectiveness of our method on several synthetic and real-world datasets.
Sampling by averaging: A multiscale approach to score estimation
Aug 20, 2025We introduce a novel framework for efficient sampling from complex, unnormalised target distributions by exploiting multiscale dynamics. Traditional score-based sampling methods either rely on learned approximations of the score function or involve computationally expensive nested Markov chain Monte Carlo (MCMC) loops. In contrast, the proposed approach leverages stochastic averaging within a slow-fast system of stochastic differential equations (SDEs) to estimate intermediate scores along a diffusion path without training or inner-loop MCMC. Two algorithms are developed under this framework: MultALMC, which uses multiscale annealed Langevin dynamics, and MultCDiff, based on multiscale controlled diffusions for the reverse-time Ornstein-Uhlenbeck process. Both overdamped and underdamped variants are considered, with theoretical guarantees of convergence to the desired diffusion path. The framework is extended to handle heavy-tailed target distributions using Student's t-based noise models and tailored fast-process dynamics. Empirical results across synthetic and real-world benchmarks, including multimodal and high-dimensional distributions, demonstrate that the proposed methods are competitive with existing samplers in terms of accuracy and efficiency, without the need for learned models.
Localized Diffusion Models for High Dimensional Distributions Generation
May 07, 2025Diffusion models are the state-of-the-art tools for various generative tasks. However, estimating high-dimensional score functions makes them potentially suffer from the curse of dimensionality (CoD). This underscores the importance of better understanding and exploiting low-dimensional structure in the target distribution. In this work, we consider locality structure, which describes sparse dependencies between model components. Under locality structure, the score function is effectively low-dimensional, so that it can be estimated by a localized neural network with significantly reduced sample complexity. This motivates the localized diffusion model, where a localized score matching loss is used to train the score function within a localized hypothesis space. We prove that such localization enables diffusion models to circumvent CoD, at the price of additional localization error. Under realistic sample size scaling, we show both theoretically and numerically that a moderate localization radius can balance the statistical and localization error, leading to a better overall performance. The localized structure also facilitates parallel training of diffusion models, making it potentially more efficient for large-scale applications.
Ensemble Kalman filter for uncertainty in human language comprehension
May 05, 2025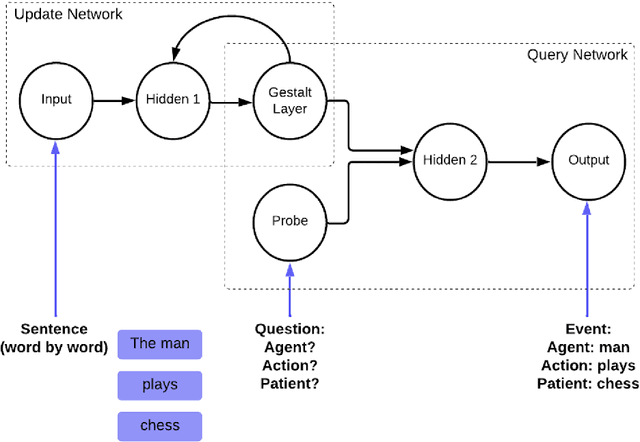



Artificial neural networks (ANNs) are widely used in modeling sentence processing but often exhibit deterministic behavior, contrasting with human sentence comprehension, which manages uncertainty during ambiguous or unexpected inputs. This is exemplified by reversal anomalies-sentences with unexpected role reversals that challenge syntax and semantics-highlighting the limitations of traditional ANN models, such as the Sentence Gestalt (SG) Model. To address these limitations, we propose a Bayesian framework for sentence comprehension, applying an extension of the ensemble Kalman filter (EnKF) for Bayesian inference to quantify uncertainty. By framing language comprehension as a Bayesian inverse problem, this approach enhances the SG model's ability to reflect human sentence processing with respect to the representation of uncertainty. Numerical experiments and comparisons with maximum likelihood estimation (MLE) demonstrate that Bayesian methods improve uncertainty representation, enabling the model to better approximate human cognitive processing when dealing with linguistic ambiguities.
Ensemble Kalman-Bucy filtering for nonlinear model predictive control
Mar 16, 2025


We consider the problem of optimal control for partially observed dynamical systems. Despite its prevalence in practical applications, there are still very few algorithms available, which take uncertainties in the current state estimates and future observations into account. In other words, most current approaches separate state estimation from the optimal control problem. In this paper, we extend the popular ensemble Kalman filter to receding horizon optimal control problems in the spirit of nonlinear model predictive control. We provide an interacting particle approximation to the forward-backward stochastic differential equations arising from Pontryagin's maximum principle with the forward stochastic differential equation provided by the time-continuous ensemble Kalman-Bucy filter equations. The receding horizon control laws are approximated as linear and are continuously updated as in nonlinear model predictive control. We illustrate the performance of the proposed methodology for an inverted pendulum example.
Localized Schrödinger Bridge Sampler
Sep 12, 2024



We consider the generative problem of sampling from an unknown distribution for which only a sufficiently large number of training samples are available. In this paper, we build on previous work combining Schr\"odinger bridges and Langevin dynamics. A key bottleneck of this approach is the exponential dependence of the required training samples on the dimension, $d$, of the ambient state space. We propose a localization strategy which exploits conditional independence of conditional expectation values. Localization thus replaces a single high-dimensional Schr\"odinger bridge problem by $d$ low-dimensional Schr\"odinger bridge problems over the available training samples. As for the original approach, the localized sampler is stable and geometric ergodic. The sampler also naturally extends to conditional sampling and to Bayesian inference. We demonstrate the performance of our proposed scheme through experiments on a Gaussian problem with increasing dimensions and on a stochastic subgrid-scale parametrization conditional sampling problem.
Efficient, Multimodal, and Derivative-Free Bayesian Inference With Fisher-Rao Gradient Flows
Jun 25, 2024



In this paper, we study efficient approximate sampling for probability distributions known up to normalization constants. We specifically focus on a problem class arising in Bayesian inference for large-scale inverse problems in science and engineering applications. The computational challenges we address with the proposed methodology are: (i) the need for repeated evaluations of expensive forward models; (ii) the potential existence of multiple modes; and (iii) the fact that gradient of, or adjoint solver for, the forward model might not be feasible. While existing Bayesian inference methods meet some of these challenges individually, we propose a framework that tackles all three systematically. Our approach builds upon the Fisher-Rao gradient flow in probability space, yielding a dynamical system for probability densities that converges towards the target distribution at a uniform exponential rate. This rapid convergence is advantageous for the computational burden outlined in (i). We apply Gaussian mixture approximations with operator splitting techniques to simulate the flow numerically; the resulting approximation can capture multiple modes thus addressing (ii). Furthermore, we employ the Kalman methodology to facilitate a derivative-free update of these Gaussian components and their respective weights, addressing the issue in (iii). The proposed methodology results in an efficient derivative-free sampler flexible enough to handle multi-modal distributions: Gaussian Mixture Kalman Inversion (GMKI). The effectiveness of GMKI is demonstrated both theoretically and numerically in several experiments with multimodal target distributions, including proof-of-concept and two-dimensional examples, as well as a large-scale application: recovering the Navier-Stokes initial condition from solution data at positive times.
Stable generative modeling using diffusion maps
Jan 09, 2024We consider the problem of sampling from an unknown distribution for which only a sufficiently large number of training samples are available. Such settings have recently drawn considerable interest in the context of generative modelling. In this paper, we propose a generative model combining diffusion maps and Langevin dynamics. Diffusion maps are used to approximate the drift term from the available training samples, which is then implemented in a discrete-time Langevin sampler to generate new samples. By setting the kernel bandwidth to match the time step size used in the unadjusted Langevin algorithm, our method effectively circumvents any stability issues typically associated with time-stepping stiff stochastic differential equations. More precisely, we introduce a novel split-step scheme, ensuring that the generated samples remain within the convex hull of the training samples. Our framework can be naturally extended to generate conditional samples. We demonstrate the performance of our proposed scheme through experiments on synthetic datasets with increasing dimensions and on a stochastic subgrid-scale parametrization conditional sampling problem.
Sampling via Gradient Flows in the Space of Probability Measures
Oct 05, 2023Sampling a target probability distribution with an unknown normalization constant is a fundamental challenge in computational science and engineering. Recent work shows that algorithms derived by considering gradient flows in the space of probability measures open up new avenues for algorithm development. This paper makes three contributions to this sampling approach by scrutinizing the design components of such gradient flows. Any instantiation of a gradient flow for sampling needs an energy functional and a metric to determine the flow, as well as numerical approximations of the flow to derive algorithms. Our first contribution is to show that the Kullback-Leibler divergence, as an energy functional, has the unique property (among all f-divergences) that gradient flows resulting from it do not depend on the normalization constant of the target distribution. Our second contribution is to study the choice of metric from the perspective of invariance. The Fisher-Rao metric is known as the unique choice (up to scaling) that is diffeomorphism invariant. As a computationally tractable alternative, we introduce a relaxed, affine invariance property for the metrics and gradient flows. In particular, we construct various affine invariant Wasserstein and Stein gradient flows. Affine invariant gradient flows are shown to behave more favorably than their non-affine-invariant counterparts when sampling highly anisotropic distributions, in theory and by using particle methods. Our third contribution is to study, and develop efficient algorithms based on Gaussian approximations of the gradient flows; this leads to an alternative to particle methods. We establish connections between various Gaussian approximate gradient flows, discuss their relation to gradient methods arising from parametric variational inference, and study their convergence properties both theoretically and numerically.
Affine Invariant Ensemble Transform Methods to Improve Predictive Uncertainty in ReLU Networks
Sep 09, 2023We consider the problem of performing Bayesian inference for logistic regression using appropriate extensions of the ensemble Kalman filter. Two interacting particle systems are proposed that sample from an approximate posterior and prove quantitative convergence rates of these interacting particle systems to their mean-field limit as the number of particles tends to infinity. Furthermore, we apply these techniques and examine their effectiveness as methods of Bayesian approximation for quantifying predictive uncertainty in ReLU networks.