 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Exponential Integration for Stable Gaussian Mixture Black-Box Variational Inference
Jan 21, 2026Black-box variational inference (BBVI) with Gaussian mixture families offers a flexible approach for approximating complex posterior distributions without requiring gradients of the target density. However, standard numerical optimization methods often suffer from instability and inefficiency. We develop a stable and efficient framework that combines three key components: (1) affine-invariant preconditioning via natural gradient formulations, (2) an exponential integrator that unconditionally preserves the positive definiteness of covariance matrices, and (3) adaptive time stepping to ensure stability and to accommodate distinct warm-up and convergence phases. The proposed approach has natural connections to manifold optimization and mirror descent. For Gaussian posteriors, we prove exponential convergence in the noise-free setting and almost-sure convergence under Monte Carlo estimation, rigorously justifying the necessity of adaptive time stepping. Numerical experiments on multimodal distributions, Neal's multiscale funnel, and a PDE-based Bayesian inverse problem for Darcy flow demonstrate the effectiveness of the proposed method.
Improving Monte Carlo Tree Search for Symbolic Regression
Sep 19, 2025Symbolic regression aims to discover concise, interpretable mathematical expressions that satisfy desired objectives, such as fitting data, posing a highly combinatorial optimization problem. While genetic programming has been the dominant approach, recent efforts have explored reinforcement learning methods for improving search efficiency. Monte Carlo Tree Search (MCTS), with its ability to balance exploration and exploitation through guided search, has emerged as a promising technique for symbolic expression discovery. However, its traditional bandit strategies and sequential symbol construction often limit performance. In this work, we propose an improved MCTS framework for symbolic regression that addresses these limitations through two key innovations: (1) an extreme bandit allocation strategy tailored for identifying globally optimal expressions, with finite-time performance guarantees under polynomial reward decay assumptions; and (2) evolution-inspired state-jumping actions such as mutation and crossover, which enable non-local transitions to promising regions of the search space. These state-jumping actions also reshape the reward landscape during the search process, improving both robustness and efficiency. We conduct a thorough numerical study to the impact of these improvements and benchmark our approach against existing symbolic regression methods on a variety of datasets, including both ground-truth and black-box datasets. Our approach achieves competitive performance with state-of-the-art libraries in terms of recovery rate, attains favorable positions on the Pareto frontier of accuracy versus model complexity. Code is available at https://github.com/PKU-CMEGroup/MCTS-4-SR.
Fast Convergence for High-Order ODE Solvers in Diffusion Probabilistic Models
Jun 16, 2025Diffusion probabilistic models generate samples by learning to reverse a noise-injection process that transforms data into noise. Reformulating this reverse process as a deterministic probability flow ordinary differential equation (ODE) enables efficient sampling using high-order solvers, often requiring only $\mathcal{O}(10)$ steps. Since the score function is typically approximated by a neural network, analyzing the interaction between its regularity, approximation error, and numerical integration error is key to understanding the overall sampling accuracy. In this work, we continue our analysis of the convergence properties of the deterministic sampling methods derived from probability flow ODEs [25], focusing on $p$-th order (exponential) Runge-Kutta schemes for any integer $p \geq 1$. Under the assumption that the first and second derivatives of the approximate score function are bounded, we develop $p$-th order (exponential) Runge-Kutta schemes and demonstrate that the total variation distance between the target distribution and the generated data distribution can be bounded above by \begin{align*} O\bigl(d^{\frac{7}{4}}\varepsilon_{\text{score}}^{\frac{1}{2}} +d(dH_{\max})^p\bigr), \end{align*} where $\varepsilon^2_{\text{score}}$ denotes the $L^2$ error in the score function approximation, $d$ is the data dimension and $H_{\max}$ represents the maximum step size used in the solver. We numerically verify the regularity assumption on benchmark datasets, confirming that the first and second derivatives of the approximate score function remain bounded in practice. Our theoretical guarantees hold for general forward processes with arbitrary variance schedules.
Stable Derivative Free Gaussian Mixture Variational Inference for Bayesian Inverse Problems
Jan 08, 2025



This paper is concerned with the approximation of probability distributions known up to normalization constants, with a focus on Bayesian inference for large-scale inverse problems in scientific computing. In this context, key challenges include costly repeated evaluations of forward models, multimodality, and inaccessible gradients for the forward model. To address them, we develop a variational inference framework that combines Fisher-Rao natural gradient with specialized quadrature rules to enable derivative free updates of Gaussian mixture variational families. The resulting method, termed Derivative Free Gaussian Mixture Variational Inference (DF-GMVI), guarantees covariance positivity and affine invariance, offering a stable and efficient framework for approximating complex posterior distributions. The effectiveness of DF-GMVI is demonstrated through numerical experiments on challenging scenarios, including distributions with multiple modes, infinitely many modes, and curved modes in spaces with up to hundreds of dimensions. The method's practicality is further demonstrated in a large-scale application, where it successfully recovers the initial conditions of the Navier-Stokes equations from solution data at positive times.
Fisher-Rao Gradient Flow: Geodesic Convexity and Functional Inequalities
Jul 22, 2024The dynamics of probability density functions has been extensively studied in science and engineering to understand physical phenomena and facilitate algorithmic design. Of particular interest are dynamics that can be formulated as gradient flows of energy functionals under the Wasserstein metric. The development of functional inequalities, such as the log-Sobolev inequality, plays a pivotal role in analyzing the convergence of these dynamics. The goal of this paper is to parallel the success of techniques using functional inequalities, for dynamics that are gradient flows under the Fisher-Rao metric, with various $f$-divergences as energy functionals. Such dynamics take the form of a nonlocal differential equation, for which existing analysis critically relies on using the explicit solution formula in special cases. We provide a comprehensive study on functional inequalities and the relevant geodesic convexity for Fisher-Rao gradient flows under minimal assumptions. A notable feature of the obtained functional inequalities is that they do not depend on the log-concavity or log-Sobolev constants of the target distribution. Consequently, the convergence rate of the dynamics (assuming well-posed) is uniform across general target distributions, making them potentially desirable dynamics for posterior sampling applications in Bayesian inference.
Efficient, Multimodal, and Derivative-Free Bayesian Inference With Fisher-Rao Gradient Flows
Jun 25, 2024



In this paper, we study efficient approximate sampling for probability distributions known up to normalization constants. We specifically focus on a problem class arising in Bayesian inference for large-scale inverse problems in science and engineering applications. The computational challenges we address with the proposed methodology are: (i) the need for repeated evaluations of expensive forward models; (ii) the potential existence of multiple modes; and (iii) the fact that gradient of, or adjoint solver for, the forward model might not be feasible. While existing Bayesian inference methods meet some of these challenges individually, we propose a framework that tackles all three systematically. Our approach builds upon the Fisher-Rao gradient flow in probability space, yielding a dynamical system for probability densities that converges towards the target distribution at a uniform exponential rate. This rapid convergence is advantageous for the computational burden outlined in (i). We apply Gaussian mixture approximations with operator splitting techniques to simulate the flow numerically; the resulting approximation can capture multiple modes thus addressing (ii). Furthermore, we employ the Kalman methodology to facilitate a derivative-free update of these Gaussian components and their respective weights, addressing the issue in (iii). The proposed methodology results in an efficient derivative-free sampler flexible enough to handle multi-modal distributions: Gaussian Mixture Kalman Inversion (GMKI). The effectiveness of GMKI is demonstrated both theoretically and numerically in several experiments with multimodal target distributions, including proof-of-concept and two-dimensional examples, as well as a large-scale application: recovering the Navier-Stokes initial condition from solution data at positive times.
Convergence Analysis of Probability Flow ODE for Score-based Generative Models
Apr 15, 2024Score-based generative models have emerged as a powerful approach for sampling high-dimensional probability distributions. Despite their effectiveness, their theoretical underpinnings remain relatively underdeveloped. In this work, we study the convergence properties of deterministic samplers based on probability flow ODEs from both theoretical and numerical perspectives. Assuming access to $L^2$-accurate estimates of the score function, we prove the total variation between the target and the generated data distributions can be bounded above by $\mathcal{O}(d\sqrt{\delta})$ in the continuous time level, where $d$ denotes the data dimension and $\delta$ represents the $L^2$-score matching error. For practical implementations using a $p$-th order Runge-Kutta integrator with step size $h$, we establish error bounds of $\mathcal{O}(d(\sqrt{\delta} + (dh)^p))$ at the discrete level. Finally, we present numerical studies on problems up to $128$ dimensions to verify our theory, which indicate a better score matching error and dimension dependence.
An operator learning perspective on parameter-to-observable maps
Feb 08, 2024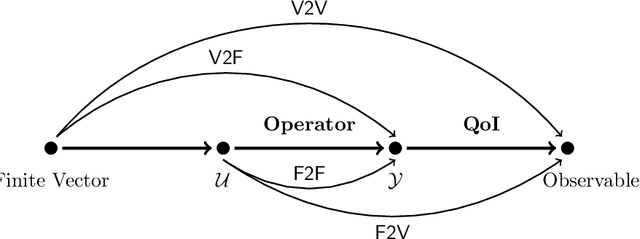

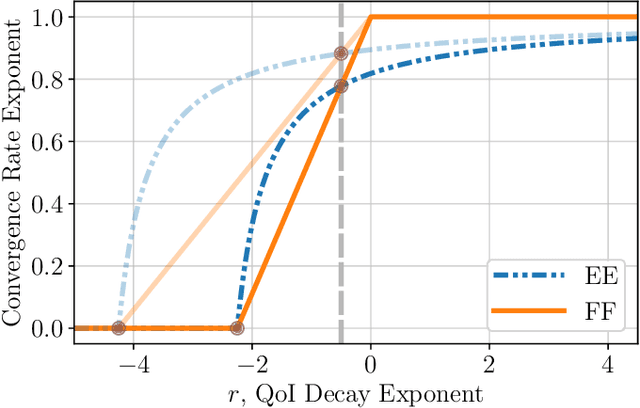
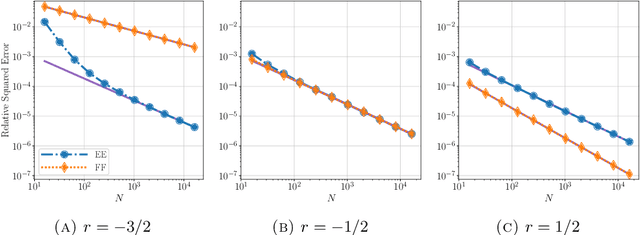
Computationally efficient surrogates for parametrized physical models play a crucial role in science and engineering. Operator learning provides data-driven surrogates that map between function spaces. However, instead of full-field measurements, often the available data are only finite-dimensional parametrizations of model inputs or finite observables of model outputs. Building off of Fourier Neural Operators, this paper introduces the Fourier Neural Mappings (FNMs) framework that is able to accommodate such finite-dimensional inputs and outputs. The paper develops universal approximation theorems for the method. Moreover, in many applications the underlying parameter-to-observable (PtO) map is defined implicitly through an infinite-dimensional operator, such as the solution operator of a partial differential equation. A natural question is whether it is more data-efficient to learn the PtO map end-to-end or first learn the solution operator and subsequently compute the observable from the full-field solution. A theoretical analysis of Bayesian nonparametric regression of linear functionals, which is of independent interest, suggests that the end-to-end approach can actually have worse sample complexity. Extending beyond the theory, numerical results for the FNM approximation of three nonlinear PtO maps demonstrate the benefits of the operator learning perspective that this paper adopts.
Sampling via Gradient Flows in the Space of Probability Measures
Oct 05, 2023Sampling a target probability distribution with an unknown normalization constant is a fundamental challenge in computational science and engineering. Recent work shows that algorithms derived by considering gradient flows in the space of probability measures open up new avenues for algorithm development. This paper makes three contributions to this sampling approach by scrutinizing the design components of such gradient flows. Any instantiation of a gradient flow for sampling needs an energy functional and a metric to determine the flow, as well as numerical approximations of the flow to derive algorithms. Our first contribution is to show that the Kullback-Leibler divergence, as an energy functional, has the unique property (among all f-divergences) that gradient flows resulting from it do not depend on the normalization constant of the target distribution. Our second contribution is to study the choice of metric from the perspective of invariance. The Fisher-Rao metric is known as the unique choice (up to scaling) that is diffeomorphism invariant. As a computationally tractable alternative, we introduce a relaxed, affine invariance property for the metrics and gradient flows. In particular, we construct various affine invariant Wasserstein and Stein gradient flows. Affine invariant gradient flows are shown to behave more favorably than their non-affine-invariant counterparts when sampling highly anisotropic distributions, in theory and by using particle methods. Our third contribution is to study, and develop efficient algorithms based on Gaussian approximations of the gradient flows; this leads to an alternative to particle methods. We establish connections between various Gaussian approximate gradient flows, discuss their relation to gradient methods arising from parametric variational inference, and study their convergence properties both theoretically and numerically.
Gradient Flows for Sampling: Mean-Field Models, Gaussian Approximations and Affine Invariance
Feb 27, 2023



Sampling a probability distribution with an unknown normalization constant is a fundamental problem in computational science and engineering. This task may be cast as an optimization problem over all probability measures, and an initial distribution can be evolved to the desired minimizer dynamically via gradient flows. Mean-field models, whose law is governed by the gradient flow in the space of probability measures, may also be identified; particle approximations of these mean-field models form the basis of algorithms. The gradient flow approach is also the basis of algorithms for variational inference, in which the optimization is performed over a parameterized family of probability distributions such as Gaussians, and the underlying gradient flow is restricted to the parameterized family. By choosing different energy functionals and metrics for the gradient flow, different algorithms with different convergence properties arise. In this paper, we concentrate on the Kullback-Leibler divergence after showing that, up to scaling, it has the unique property that the gradient flows resulting from this choice of energy do not depend on the normalization constant. For the metrics, we focus on variants of the Fisher-Rao, Wasserstein, and Stein metrics; we introduce the affine invariance property for gradient flows, and their corresponding mean-field models, determine whether a given metric leads to affine invariance, and modify it to make it affine invariant if it does not. We study the resulting gradient flows in both probability density space and Gaussian space. The flow in the Gaussian space may be understood as a Gaussian approximation of the flow. We demonstrate that the Gaussian approximation based on the metric and through moment closure coincide, establish connections between them, and study their long-time convergence properties showing the advantages of affine invariance.