 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human-Level AI Tales to AI Leveling Human Scales
Feb 21, 2026Comparing AI models to "human level" is often misleading when benchmark scores are incommensurate or human baselines are drawn from a narrow population. To address this, we propose a framework that calibrates items against the 'world population' and report performance on a common, human-anchored scale. Concretely, we build on a set of multi-level scales for different capabilities where each level should represent a probability of success of the whole world population on a logarithmic scale with a base $B$. We calibrate each scale for each capability (reasoning, comprehension, knowledge, volume, etc.) by compiling publicly released human test data spanning education and reasoning benchmarks (PISA, TIMSS, ICAR, UKBioBank, and ReliabilityBench). The base $B$ is estimated by extrapolating between samples with two demographic profiles using LLMs, with the hypothesis that they condense rich information about human populations. We evaluate the quality of different mappings using group slicing and post-stratification. The new techniques allow for the recalibration and standardization of scales relative to the whole-world population.
Multi-fidelity Reinforcement Learning Control for Complex Dynamical Systems
Apr 08, 2025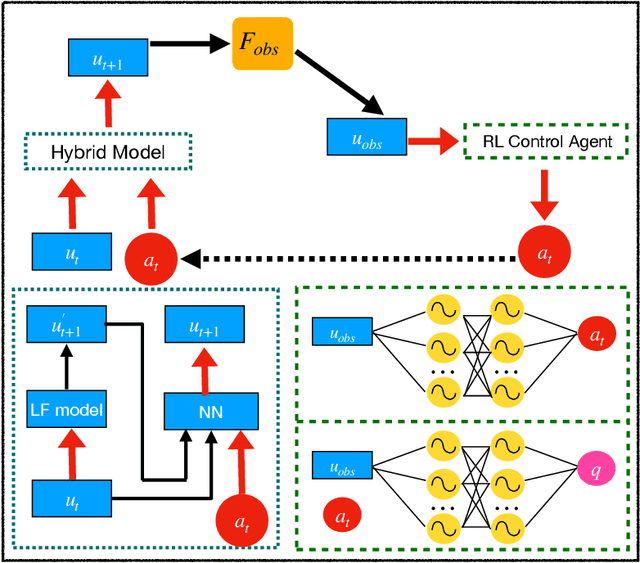
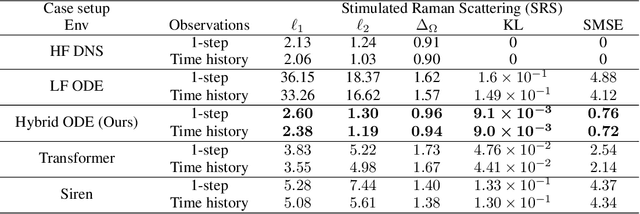
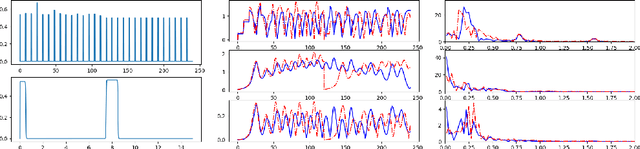
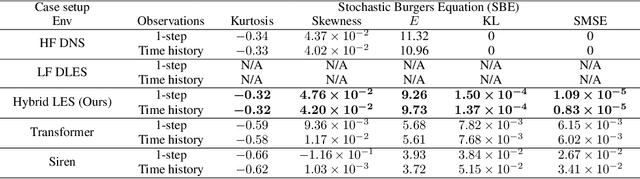
Controlling instabilities in complex dynamical systems is challenging in scientific and engineering applications. Deep reinforcement learning (DRL) has seen promising results for applications in different scientific applications. The many-query nature of control tasks requires multiple interactions with real environments of the underlying physics. However, it is usually sparse to collect from the experiments or expensive to simulate for complex dynamics. Alternatively, controlling surrogate modeling could mitigate the computational cost issue. However, a fast and accurate learning-based model by offline training makes it very hard to get accurate pointwise dynamics when the dynamics are chaotic. To bridge this gap, the current work proposes a multi-fidelity reinforcement learning (MFRL) framework that leverages differentiable hybrid models for control tasks, where a physics-based hybrid model is corrected by limited high-fidelity data. We also proposed a spectrum-based reward function for RL learning. The effect of the proposed framework is demonstrated on two complex dynamics in physics. The statistics of the MFRL control result match that computed from many-query evaluations of the high-fidelity environments and outperform other SOTA baselines.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
Large Language Models show both individual and collective creativity comparable to humans
Dec 04, 2024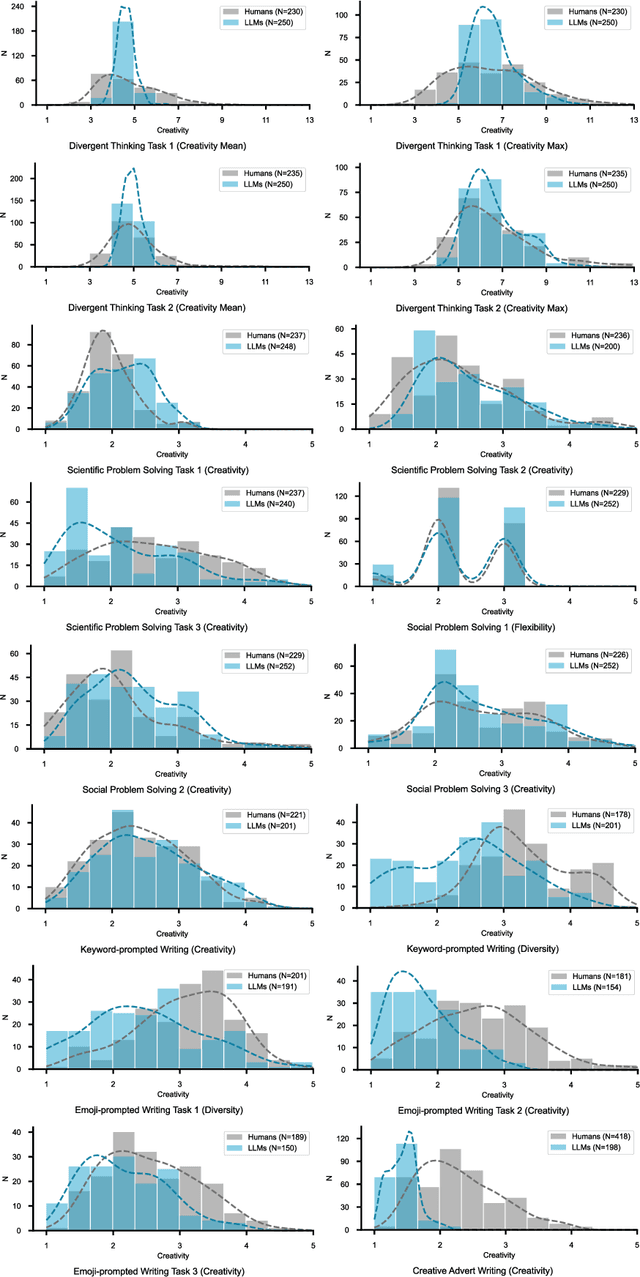
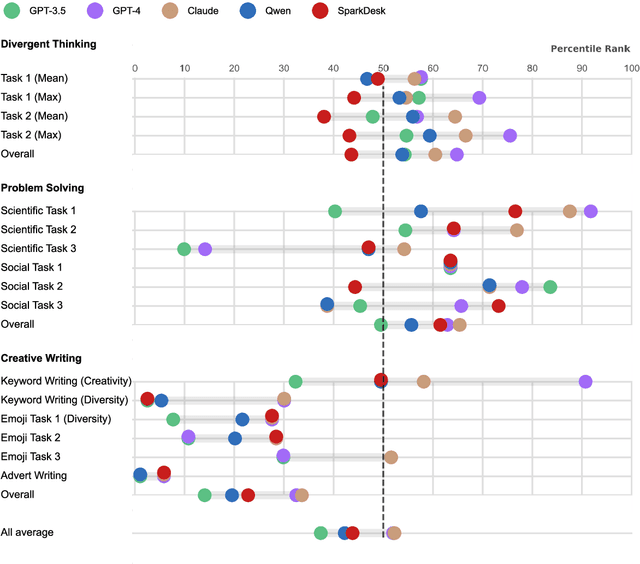
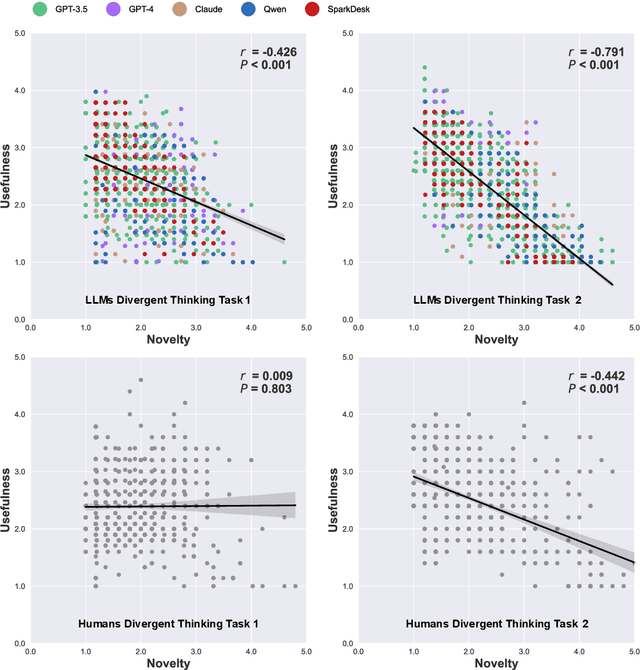
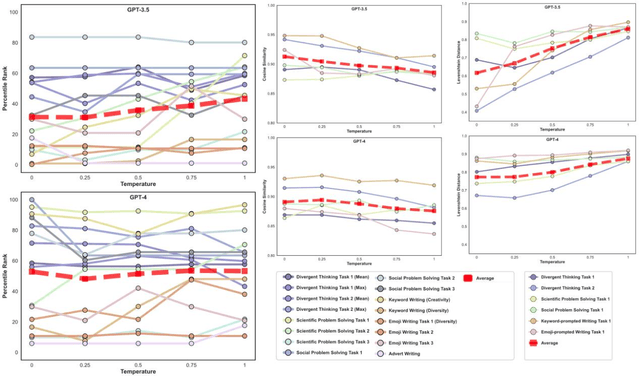
Artificial intelligence has, so far, largely automated routine tasks, but what does it mean for the future of work if Large Language Models (LLMs) show creativity comparable to humans? To measure the creativity of LLMs holistically, the current study uses 13 creative tasks spanning three domains. We benchmark the LLMs against individual humans, and also take a novel approach by comparing them to the collective creativity of groups of humans. We find that the best LLMs (Claude and GPT-4) rank in the 52nd percentile against humans, and overall LLMs excel in divergent thinking and problem solving but lag in creative writing. When questioned 10 times, an LLM's collective creativity is equivalent to 8-10 humans. When more responses are requested, two additional responses of LLMs equal one extra human. Ultimately, LLMs, when optimally applied, may compete with a small group of humans in the future of work.
Bayesian Conditional Diffusion Models for Versatile Spatiotemporal Turbulence Generation
Nov 14, 2023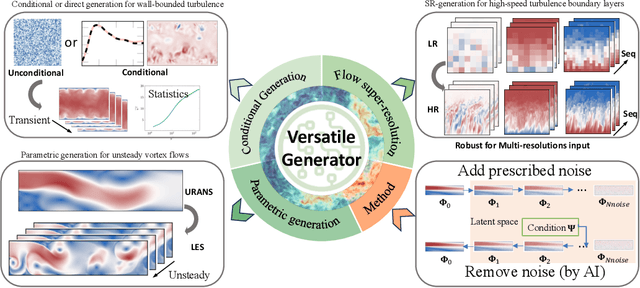


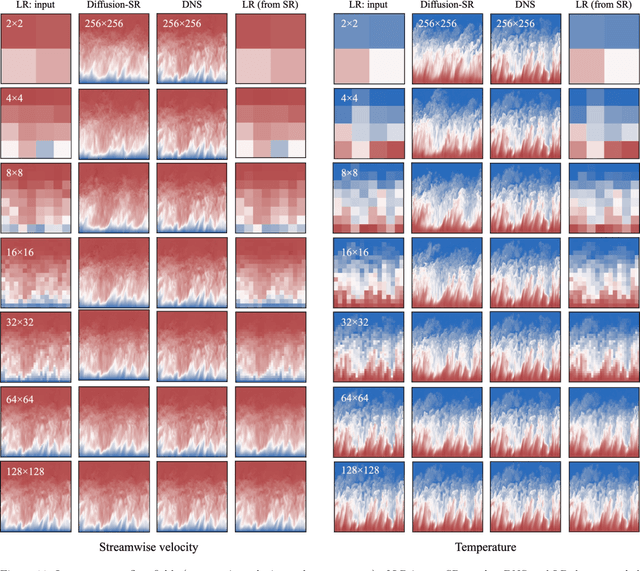
Turbulent flows have historically presented formidable challenges to predictive computational modeling. Traditional numerical simulations often require vast computational resources, making them infeasible for numerous engineering applications. As an alternative, deep learning-based surrogate models have emerged, offering data-drive solutions. However, these are typically constructed within deterministic settings, leading to shortfall in capturing the innate chaotic and stochastic behaviors of turbulent dynamics. We introduce a novel generative framework grounded in probabilistic diffusion models for versatile generation of spatiotemporal turbulence. Our method unifies both unconditional and conditional sampling strategies within a Bayesian framework, which can accommodate diverse conditioning scenarios, including those with a direct differentiable link between specified conditions and generated unsteady flow outcomes, and scenarios lacking such explicit correlations. A notable feature of our approach is the method proposed for long-span flow sequence generation, which is based on autoregressive gradient-based conditional sampling, eliminating the need for cumbersome retraining processes. We showcase the versatile turbulence generation capability of our framework through a suite of numerical experiments, including: 1) the synthesis of LES simulated instantaneous flow sequences from URANS inputs; 2) holistic generation of inhomogeneous, anisotropic wall-bounded turbulence, whether from given initial conditions, prescribed turbulence statistics, or entirely from scratch; 3) super-resolved generation of high-speed turbulent boundary layer flows from low-resolution data across a range of input resolutions. Collectively, our numerical experiments highlight the merit and transformative potential of the proposed methods, making a significant advance in the field of turbulence generation.
Evaluating General-Purpose AI with Psychometrics
Oct 25, 2023Artificial intelligence (AI) has witnessed an evolution from task-specific to general-purpose systems that trend toward human versatility. As AI systems begin to play pivotal roles in society, it is important to ensure that they are adequately evaluated. Current AI benchmarks typically assess performance on collections of specific tasks. This has drawbacks when used for assessing general-purpose AI systems. First, it is difficult to predict whether AI systems could complete a new task it has never seen or that did not previously exist. Second, these benchmarks often focus on overall performance metrics, potentially overlooking the finer details crucial for making informed decisions. Lastly, there are growing concerns about the reliability of existing benchmarks and questions about what is being measured. To solve these challenges, this paper suggests that psychometrics, the science of psychological measurement, should be placed at the core of evaluating general-purpose AI. Psychometrics provides a rigorous methodology for identifying and measuring the latent constructs that underlie performance across multiple tasks. We discuss its merits, warn against potential pitfalls, and propose a framework for putting it into practice. Finally, we explore future opportunities to integrate psychometrics with AI.
Personality Traits in Large Language Models
Jul 01, 2023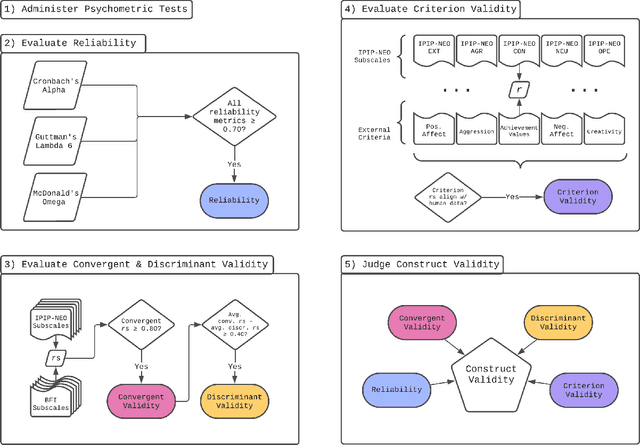

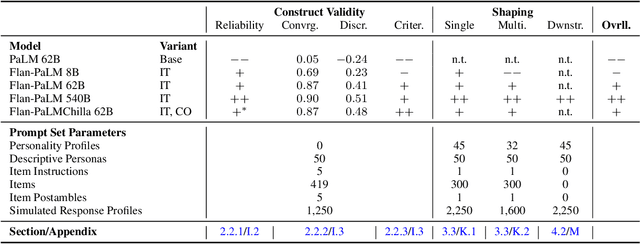
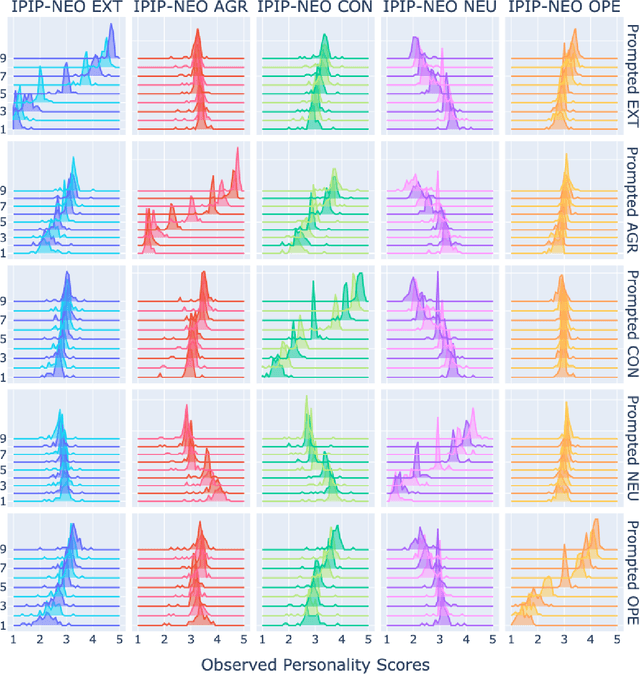
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.
Bayesian Spline Learning for Equation Discovery of Nonlinear Dynamics with Quantified Uncertainty
Oct 14, 2022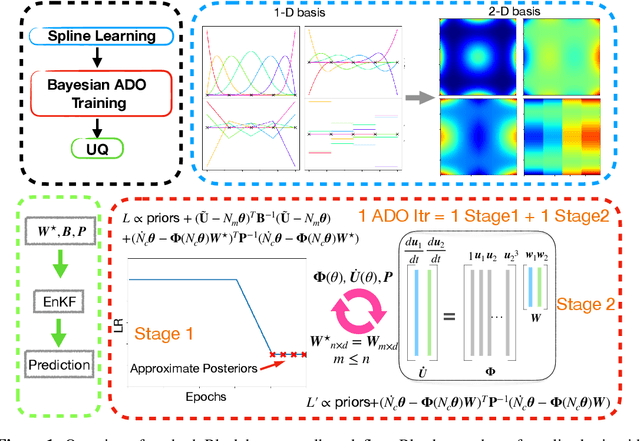
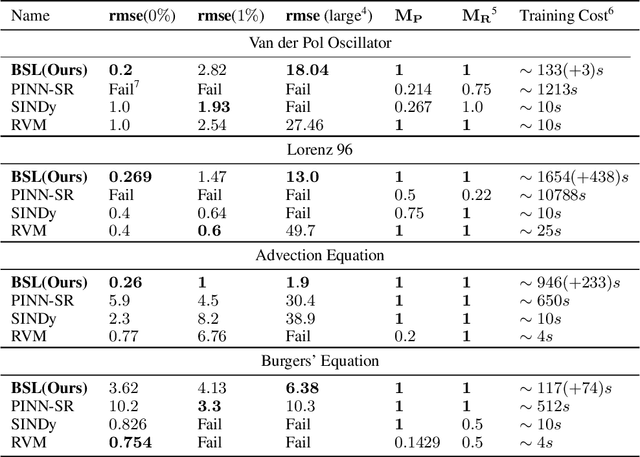
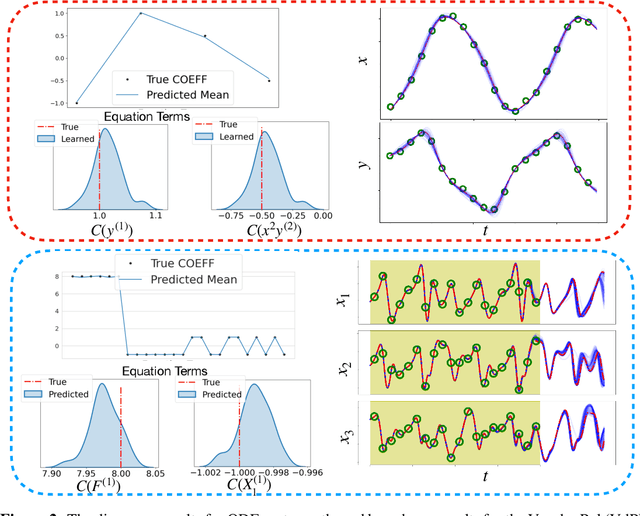
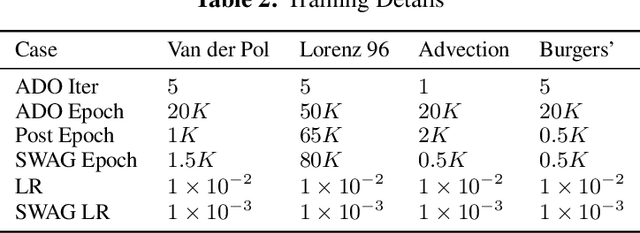
Nonlinear dynamics are ubiquitous in science and engineering applications, but the physics of most complex systems is far from being fully understood. Discovering interpretable governing equations from measurement data can help us understand and predict the behavior of complex dynamic systems. Although extensive work has recently been done in this field, robustly distilling explicit model forms from very sparse data with considerable noise remains intractable. Moreover, quantifying and propagating the uncertainty of the identified system from noisy data is challenging, and relevant literature is still limited. To bridge this gap, we develop a novel Bayesian spline learning framework to identify parsimonious governing equations of nonlinear (spatio)temporal dynamics from sparse, noisy data with quantified uncertainty. The proposed method utilizes spline basis to handle the data scarcity and measurement noise, upon which a group of derivatives can be accurately computed to form a library of candidate model terms. The equation residuals are used to inform the spline learning in a Bayesian manner, where approximate Bayesian uncertainty calibration techniques are employed to approximate posterior distributions of the trainable parameters. To promote the sparsity, an iterative sequential-threshold Bayesian learning approach is developed, using the alternative direction optimization strategy to systematically approximate L0 sparsity constraints. The proposed algorithm is evaluated on multiple nonlinear dynamical systems governed by canonical ordinary and partial differential equations, and the merit/superiority of the proposed method is demonstrated by comparison with state-of-the-art methods.
An advanced spatio-temporal convolutional recurrent neural network for storm surge predictions
Apr 18, 2022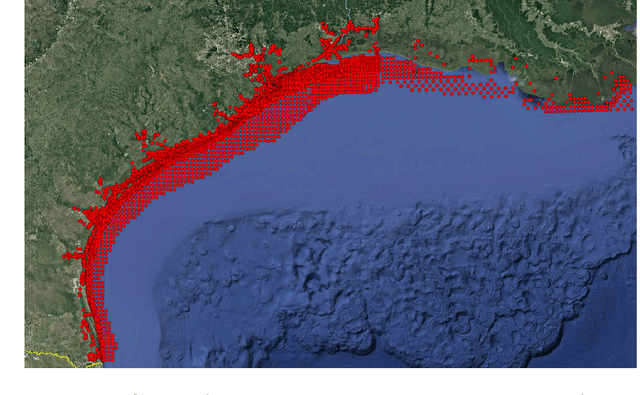
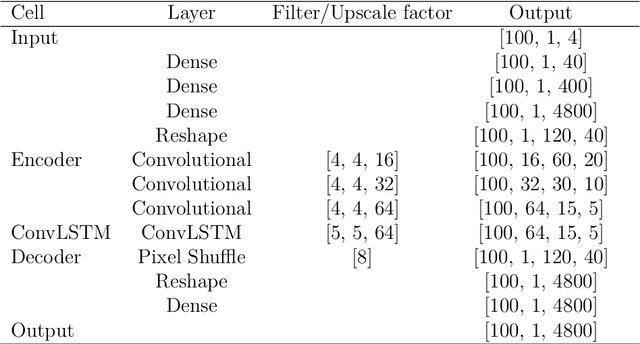
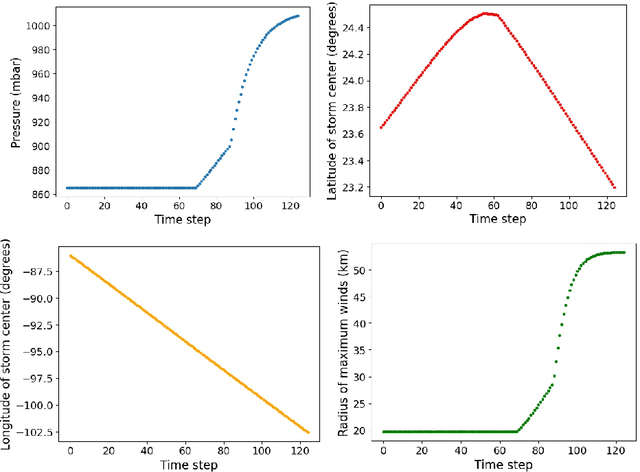

In this research paper, we study the capability of artificial neural network models to emulate storm surge based on the storm track/size/intensity history, leveraging a database of synthetic storm simulations. Traditionally, Computational Fluid Dynamics solvers are employed to numerically solve the storm surge governing equations that are Partial Differential Equations and are generally very costly to simulate. This study presents a neural network model that can predict storm surge, informed by a database of synthetic storm simulations. This model can serve as a fast and affordable emulator for the very expensive CFD solvers. The neural network model is trained with the storm track parameters used to drive the CFD solvers, and the output of the model is the time-series evolution of the predicted storm surge across multiple nodes within the spatial domain of interest. Once the model is trained, it can be deployed for further predictions based on new storm track inputs. The developed neural network model is a time-series model, a Long short-term memory, a variation of Recurrent Neural Network, which is enriched with Convolutional Neural Networks. The convolutional neural network is employed to capture the correlation of data spatially. Therefore, the temporal and spatial correlations of data are captured by the combination of the mentioned models, the ConvLSTM model. As the problem is a sequence to sequence time-series problem, an encoder-decoder ConvLSTM model is designed. Some other techniques in the process of model training are also employed to enrich the model performance. The results show the proposed convolutional recurrent neural network outperforms the Gaussian Process implementation for the examined synthetic storm database.