 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
Jan 28, 2026Text-driven multi-human motion generation with complex interactions remains a challenging problem. Despite progress in performance, existing offline methods that generate fixed-length motions with a fixed number of agents, are inherently limited in handling long or variable text, and varying agent counts. These limitations naturally encourage autoregressive formulations, which predict future motions step by step conditioned on all past trajectories and current text guidance. In this work, we introduce HINT, the first autoregressive framework for multi-human motion generation with Hierarchical INTeraction modeling in diffusion. First, HINT leverages a disentangled motion representation within a canonicalized latent space, decoupling local motion semantics from inter-person interactions. This design facilitates direct adaptation to varying numbers of human participants without requiring additional refinement. Second, HINT adopts a sliding-window strategy for efficient online generation, and aggregates local within-window and global cross-window conditions to capture past human history, inter-person dependencies, and align with text guidance. This strategy not only enables fine-grained interaction modeling within each window but also preserves long-horizon coherence across all the long sequence. Extensive experiments on public benchmarks demonstrate that HINT matches the performance of strong offline models and surpasses autoregressive baselines. Notably, on InterHuman, HINT achieves an FID of 3.100, significantly improving over the previous state-of-the-art score of 5.154.
4D3R: Motion-Aware Neural Reconstruction and Rendering of Dynamic Scenes from Monocular Videos
Nov 07, 2025Novel view synthesis from monocular videos of dynamic scenes with unknown camera poses remains a fundamental challenge in computer vision and graphics. While recent advances in 3D representations such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown promising results for static scenes, they struggle with dynamic content and typically rely on pre-computed camera poses. We present 4D3R, a pose-free dynamic neural rendering framework that decouples static and dynamic components through a two-stage approach. Our method first leverages 3D foundational models for initial pose and geometry estimation, followed by motion-aware refinement. 4D3R introduces two key technical innovations: (1) a motion-aware bundle adjustment (MA-BA) module that combines transformer-based learned priors with SAM2 for robust dynamic object segmentation, enabling more accurate camera pose refinement; and (2) an efficient Motion-Aware Gaussian Splatting (MA-GS) representation that uses control points with a deformation field MLP and linear blend skinning to model dynamic motion, significantly reducing computational cost while maintaining high-quality reconstruction. Extensive experiments on real-world dynamic datasets demonstrate that our approach achieves up to 1.8dB PSNR improvement over state-of-the-art methods, particularly in challenging scenarios with large dynamic objects, while reducing computational requirements by 5x compared to previous dynamic scene representations.
* 17 pages, 5 figures
Large Language Model-Driven Closed-Loop UAV Operation with Semantic Observations
Jul 03, 2025Recent advances in large Language Models (LLMs) have revolutionized mobile robots, including unmanned aerial vehicles (UAVs), enabling their intelligent operation within Internet of Things (IoT) ecosystems. However, LLMs still face challenges from logical reasoning and complex decision-making, leading to concerns about the reliability of LLM-driven UAV operations in IoT applications. In this paper, we propose a LLM-driven closed-loop control framework that enables reliable UAV operations powered by effective feedback and refinement using two LLM modules, i.e., a Code Generator and an Evaluator. Our framework transforms numerical state observations from UAV operations into natural language trajectory descriptions to enhance the evaluator LLM's understanding of UAV dynamics for precise feedback generation. Our framework also enables a simulation-based refinement process, and hence eliminates the risks to physical UAVs caused by incorrect code execution during the refinement. Extensive experiments on UAV control tasks with different complexities are conducted. The experimental results show that our framework can achieve reliable UAV operations using LLMs, which significantly outperforms baseline approaches in terms of success rate and completeness with the increase of task complexity.
4D Gaussian Splatting SLAM
Mar 20, 2025Simultaneously localizing camera poses and constructing Gaussian radiance fields in dynamic scenes establish a crucial bridge between 2D images and the 4D real world. Instead of removing dynamic objects as distractors and reconstructing only static environments, this paper proposes an efficient architecture that incrementally tracks camera poses and establishes the 4D Gaussian radiance fields in unknown scenarios by using a sequence of RGB-D images. First, by generating motion masks, we obtain static and dynamic priors for each pixel. To eliminate the influence of static scenes and improve the efficiency on learning the motion of dynamic objects, we classify the Gaussian primitives into static and dynamic Gaussian sets, while the sparse control points along with an MLP is utilized to model the transformation fields of the dynamic Gaussians. To more accurately learn the motion of dynamic Gaussians, a novel 2D optical flow map reconstruction algorithm is designed to render optical flows of dynamic objects between neighbor images, which are further used to supervise the 4D Gaussian radiance fields along with traditional photometric and geometric constraints. In experiments, qualitative and quantitative evaluation results show that the proposed method achieves robust tracking and high-quality view synthesis performance in real-world environments.
MVGSR: Multi-View Consistency Gaussian Splatting for Robust Surface Reconstruction
Mar 11, 2025



3D Gaussian Splatting (3DGS) has gained significant attention for its high-quality rendering capabilities, ultra-fast training, and inference speeds. However, when we apply 3DGS to surface reconstruction tasks, especially in environments with dynamic objects and distractors, the method suffers from floating artifacts and color errors due to inconsistency from different viewpoints. To address this challenge, we propose Multi-View Consistency Gaussian Splatting for the domain of Robust Surface Reconstruction (\textbf{MVGSR}), which takes advantage of lightweight Gaussian models and a {heuristics-guided distractor masking} strategy for robust surface reconstruction in non-static environments. Compared to existing methods that rely on MLPs for distractor segmentation strategies, our approach separates distractors from static scene elements by comparing multi-view feature consistency, allowing us to obtain precise distractor masks early in training. Furthermore, we introduce a pruning measure based on multi-view contributions to reset transmittance, effectively reducing floating artifacts. Finally, a multi-view consistency loss is applied to achieve high-quality performance in surface reconstruction tasks. Experimental results demonstrate that MVGSR achieves competitive geometric accuracy and rendering fidelity compared to the state-of-the-art surface reconstruction algorithms. More information is available on our project page (\href{https://mvgsr.github.io}{this url})
GSCE: A Prompt Framework with Enhanced Reasoning for Reliable LLM-driven Drone Control
Feb 18, 2025



The integration of Large Language Models (LLMs) into robotic control, including drones, has the potential to revolutionize autonomous systems. Research studies have demonstrated that LLMs can be leveraged to support robotic operations. However, when facing tasks with complex reasoning, concerns and challenges are raised about the reliability of solutions produced by LLMs. In this paper, we propose a prompt framework with enhanced reasoning to enable reliable LLM-driven control for drones. Our framework consists of novel technical components designed using Guidelines, Skill APIs, Constraints, and Examples, namely GSCE. GSCE is featured by its reliable and constraint-compliant code generation. We performed thorough experiments using GSCE for the control of drones with a wide level of task complexities. Our experiment results demonstrate that GSCE can significantly improve task success rates and completeness compared to baseline approaches, highlighting its potential for reliable LLM-driven autonomous drone systems.
Street Gaussians without 3D Object Tracker
Dec 07, 2024



Realistic scene reconstruction in driving scenarios poses significant challenges due to fast-moving objects. Most existing methods rely on labor-intensive manual labeling of object poses to reconstruct dynamic objects in canonical space and move them based on these poses during rendering. While some approaches attempt to use 3D object trackers to replace manual annotations, the limited generalization of 3D trackers -- caused by the scarcity of large-scale 3D datasets -- results in inferior reconstructions in real-world settings. In contrast, 2D foundation models demonstrate strong generalization capabilities. To eliminate the reliance on 3D trackers and enhance robustness across diverse environments, we propose a stable object tracking module by leveraging associations from 2D deep trackers within a 3D object fusion strategy. We address inevitable tracking errors by further introducing a motion learning strategy in an implicit feature space that autonomously corrects trajectory errors and recovers missed detections. Experimental results on Waymo-NOTR datasets show we achieve state-of-the-art performance. Our code will be made publicly available.
Learnable Infinite Taylor Gaussian for Dynamic View Rendering
Dec 05, 2024



Capturing the temporal evolution of Gaussian properties such as position, rotation, and scale is a challenging task due to the vast number of time-varying parameters and the limited photometric data available, which generally results in convergence issues, making it difficult to find an optimal solution. While feeding all inputs into an end-to-end neural network can effectively model complex temporal dynamics, this approach lacks explicit supervision and struggles to generate high-quality transformation fields. On the other hand, using time-conditioned polynomial functions to model Gaussian trajectories and orientations provides a more explicit and interpretable solution, but requires significant handcrafted effort and lacks generalizability across diverse scenes. To overcome these limitations, this paper introduces a novel approach based on a learnable infinite Taylor Formula to model the temporal evolution of Gaussians. This method offers both the flexibility of an implicit network-based approach and the interpretability of explicit polynomial functions, allowing for more robust and generalizable modeling of Gaussian dynamics across various dynamic scenes. Extensive experiments on dynamic novel view rendering tasks are conducted on public datasets, demonstrating that the proposed method achieves state-of-the-art performance in this domain. More information is available on our project page(https://ellisonking.github.io/TaylorGaussian).
Large Language Models show both individual and collective creativity comparable to humans
Dec 04, 2024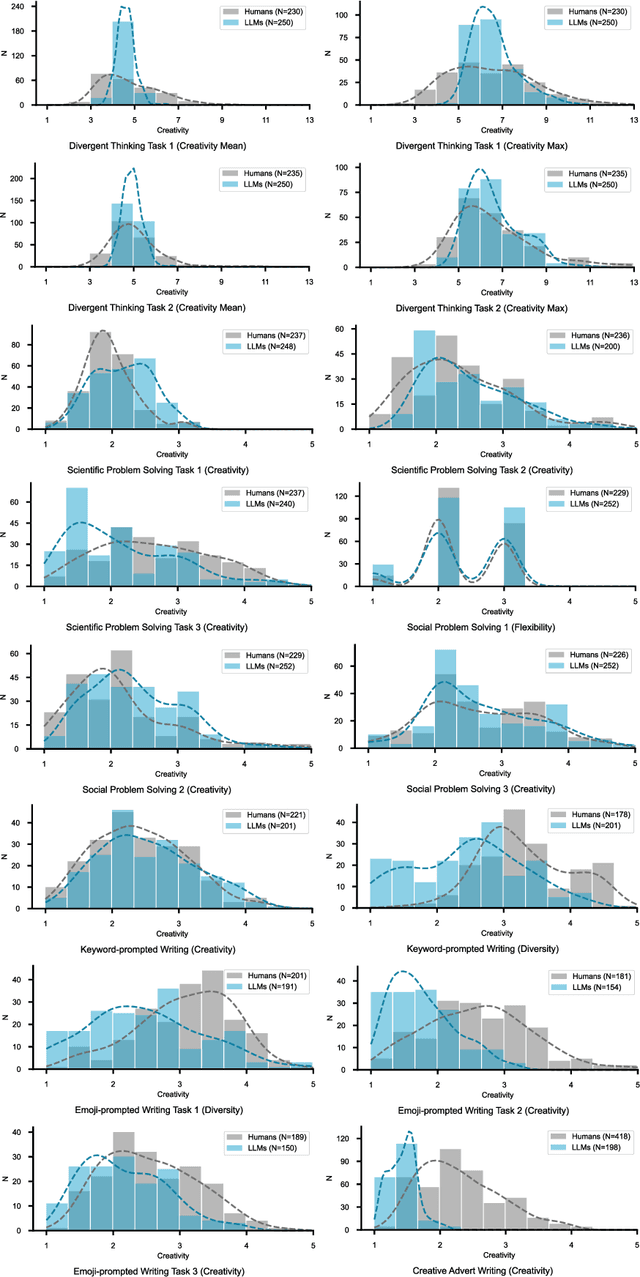
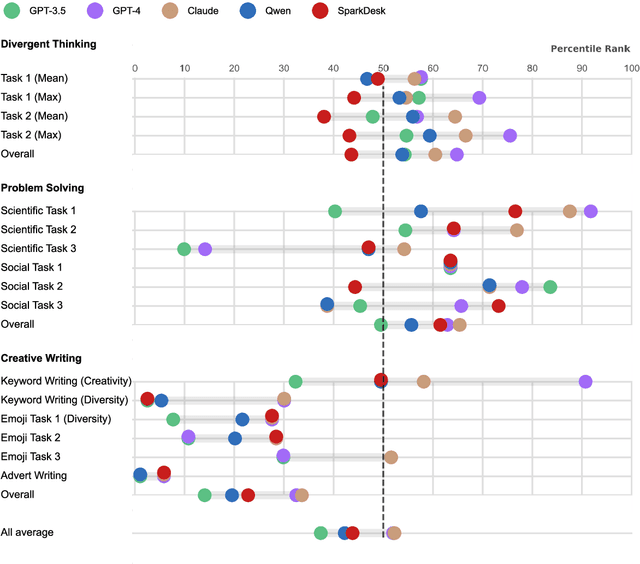
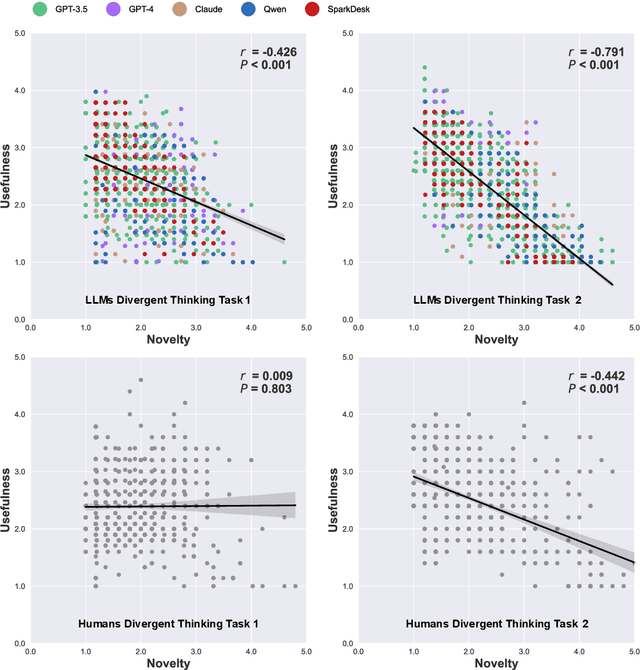
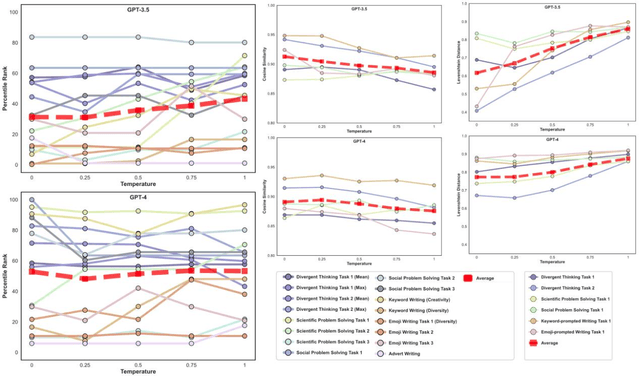
Artificial intelligence has, so far, largely automated routine tasks, but what does it mean for the future of work if Large Language Models (LLMs) show creativity comparable to humans? To measure the creativity of LLMs holistically, the current study uses 13 creative tasks spanning three domains. We benchmark the LLMs against individual humans, and also take a novel approach by comparing them to the collective creativity of groups of humans. We find that the best LLMs (Claude and GPT-4) rank in the 52nd percentile against humans, and overall LLMs excel in divergent thinking and problem solving but lag in creative writing. When questioned 10 times, an LLM's collective creativity is equivalent to 8-10 humans. When more responses are requested, two additional responses of LLMs equal one extra human. Ultimately, LLMs, when optimally applied, may compete with a small group of humans in the future of work.
SmileSplat: Generalizable Gaussian Splats for Unconstrained Sparse Images
Nov 27, 2024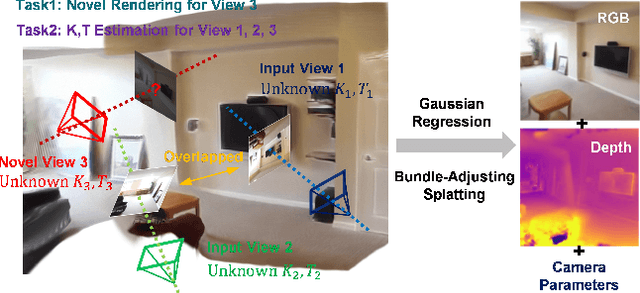
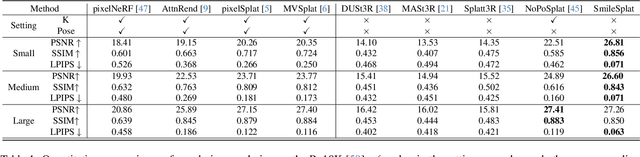
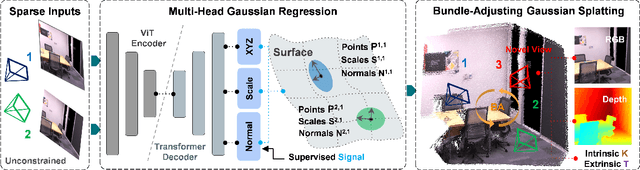
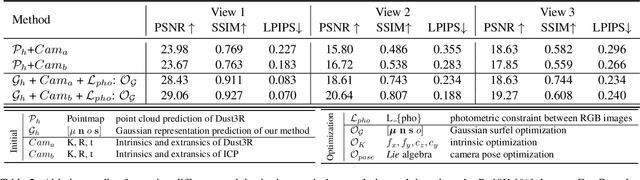
Sparse Multi-view Images can be Learned to predict explicit radiance fields via Generalizable Gaussian Splatting approaches, which can achieve wider application prospects in real-life when ground-truth camera parameters are not required as inputs. In this paper, a novel generalizable Gaussian Splatting method, SmileSplat, is proposed to reconstruct pixel-aligned Gaussian surfels for diverse scenarios only requiring unconstrained sparse multi-view images. First, Gaussian surfels are predicted based on the multi-head Gaussian regression decoder, which can are represented with less degree-of-freedom but have better multi-view consistency. Furthermore, the normal vectors of Gaussian surfel are enhanced based on high-quality of normal priors. Second, the Gaussians and camera parameters (both extrinsic and intrinsic) are optimized to obtain high-quality Gaussian radiance fields for novel view synthesis tasks based on the proposed Bundle-Adjusting Gaussian Splatting module. Extensive experiments on novel view rendering and depth map prediction tasks are conducted on public datasets, demonstrating that the proposed method achieves state-of-the-art performance in various 3D vision tasks. More information can be found on our project page (https://yanyan-li.github.io/project/gs/smilesplat)