 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D3R: Motion-Aware Neural Reconstruction and Rendering of Dynamic Scenes from Monocular Videos
Nov 07, 2025Novel view synthesis from monocular videos of dynamic scenes with unknown camera poses remains a fundamental challenge in computer vision and graphics. While recent advances in 3D representations such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown promising results for static scenes, they struggle with dynamic content and typically rely on pre-computed camera poses. We present 4D3R, a pose-free dynamic neural rendering framework that decouples static and dynamic components through a two-stage approach. Our method first leverages 3D foundational models for initial pose and geometry estimation, followed by motion-aware refinement. 4D3R introduces two key technical innovations: (1) a motion-aware bundle adjustment (MA-BA) module that combines transformer-based learned priors with SAM2 for robust dynamic object segmentation, enabling more accurate camera pose refinement; and (2) an efficient Motion-Aware Gaussian Splatting (MA-GS) representation that uses control points with a deformation field MLP and linear blend skinning to model dynamic motion, significantly reducing computational cost while maintaining high-quality reconstruction. Extensive experiments on real-world dynamic datasets demonstrate that our approach achieves up to 1.8dB PSNR improvement over state-of-the-art methods, particularly in challenging scenarios with large dynamic objects, while reducing computational requirements by 5x compared to previous dynamic scene representations.
* 17 pages, 5 figures
MVGSR: Multi-View Consistency Gaussian Splatting for Robust Surface Reconstruction
Mar 11, 2025



3D Gaussian Splatting (3DGS) has gained significant attention for its high-quality rendering capabilities, ultra-fast training, and inference speeds. However, when we apply 3DGS to surface reconstruction tasks, especially in environments with dynamic objects and distractors, the method suffers from floating artifacts and color errors due to inconsistency from different viewpoints. To address this challenge, we propose Multi-View Consistency Gaussian Splatting for the domain of Robust Surface Reconstruction (\textbf{MVGSR}), which takes advantage of lightweight Gaussian models and a {heuristics-guided distractor masking} strategy for robust surface reconstruction in non-static environments. Compared to existing methods that rely on MLPs for distractor segmentation strategies, our approach separates distractors from static scene elements by comparing multi-view feature consistency, allowing us to obtain precise distractor masks early in training. Furthermore, we introduce a pruning measure based on multi-view contributions to reset transmittance, effectively reducing floating artifacts. Finally, a multi-view consistency loss is applied to achieve high-quality performance in surface reconstruction tasks. Experimental results demonstrate that MVGSR achieves competitive geometric accuracy and rendering fidelity compared to the state-of-the-art surface reconstruction algorithms. More information is available on our project page (\href{https://mvgsr.github.io}{this url})
TreeSBA: Tree-Transformer for Self-Supervised Sequential Brick Assembly
Jul 22, 2024



Inferring step-wise actions to assemble 3D objects with primitive bricks from images is a challenging task due to complex constraints and the vast number of possible combinations. Recent studies have demonstrated promising results on sequential LEGO brick assembly through the utilization of LEGO-Graph modeling to predict sequential actions. However, existing approaches are class-specific and require significant computational and 3D annotation resources. In this work, we first propose a computationally efficient breadth-first search (BFS) LEGO-Tree structure to model the sequential assembly actions by considering connections between consecutive layers. Based on the LEGO-Tree structure, we then design a class-agnostic tree-transformer framework to predict the sequential assembly actions from the input multi-view images. A major challenge of the sequential brick assembly task is that the step-wise action labels are costly and tedious to obtain in practice. We mitigate this problem by leveraging synthetic-to-real transfer learning. Specifically, our model is first pre-trained on synthetic data with full supervision from the available action labels. We then circumvent the requirement for action labels in the real data by proposing an action-to-silhouette projection that replaces action labels with input image silhouettes for self-supervision. Without any annotation on the real data, our model outperforms existing methods with 3D supervision by 7.8% and 11.3% in mIoU on the MNIST and ModelNet Construction datasets, respectively.
URS-NeRF: Unordered Rolling Shutter Bundle Adjustment for Neural Radiance Fields
Mar 25, 2024



We propose a novel rolling shutter bundle adjustment method for neural radiance fields (NeRF), which utilizes the unordered rolling shutter (RS) images to obtain the implicit 3D representation. Existing NeRF methods suffer from low-quality images and inaccurate initial camera poses due to the RS effect in the image, whereas, the previous method that incorporates the RS into NeRF requires strict sequential data input, limiting its widespread applicability. In constant, our method recovers the physical formation of RS images by estimating camera poses and velocities, thereby removing the input constraints on sequential data. Moreover, we adopt a coarse-to-fine training strategy, in which the RS epipolar constraints of the pairwise frames in the scene graph are used to detect the camera poses that fall into local minima. The poses detected as outliers are corrected by the interpolation method with neighboring poses. The experimental results validate the effectiveness of our method over state-of-the-art works and demonstrate that the reconstruction of 3D representations is not constrained by the requirement of video sequence input.
GNeSF: Generalizable Neural Semantic Fields
Oct 26, 2023



3D scene segmentation based on neural implicit representation has emerged recently with the advantage of training only on 2D supervision. However, existing approaches still requires expensive per-scene optimization that prohibits generalization to novel scenes during inference. To circumvent this problem, we introduce a generalizable 3D segmentation framework based on implicit representation. Specifically, our framework takes in multi-view image features and semantic maps as the inputs instead of only spatial information to avoid overfitting to scene-specific geometric and semantic information. We propose a novel soft voting mechanism to aggregate the 2D semantic information from different views for each 3D point. In addition to the image features, view difference information is also encoded in our framework to predict the voting scores. Intuitively, this allows the semantic information from nearby views to contribute more compared to distant ones. Furthermore, a visibility module is also designed to detect and filter out detrimental information from occluded views. Due to the generalizability of our proposed method, we can synthesize semantic maps or conduct 3D semantic segmentation for novel scenes with solely 2D semantic supervision. Experimental results show that our approach achieves comparable performance with scene-specific approaches. More importantly, our approach can even outperform existing strong supervision-based approaches with only 2D annotations. Our source code is available at: https://github.com/HLinChen/GNeSF.
Incremental Learning for Neural Radiance Field with Uncertainty-Filtered Knowledge Distillation
Dec 21, 2022
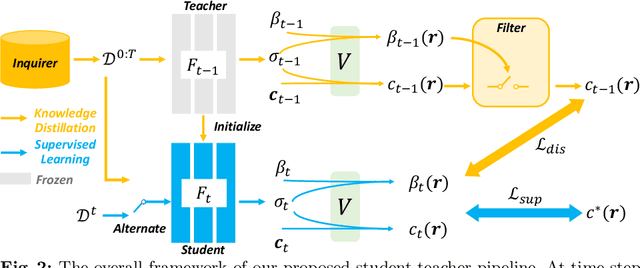
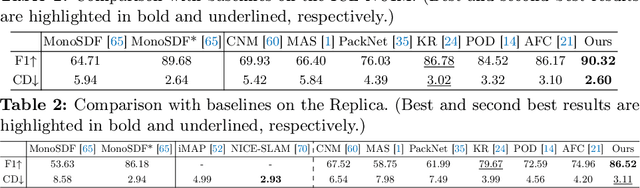
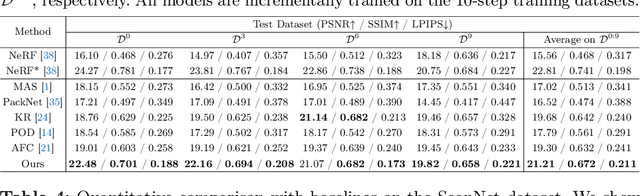
Recent neural radiance field (NeRF) representation has achieved great success in the tasks of novel view synthesis and 3D reconstruction. However, they suffer from the catastrophic forgetting problem when continuously learning from streaming data without revisiting the previous training data. This limitation prohibits the application of existing NeRF models to scenarios where images come in sequentially. In view of this, we explore the task of incremental learning for neural radiance field representation in this work. We first propose a student-teacher pipeline to mitigate the catastrophic forgetting problem. Specifically, we iterate the process of using the student as the teacher at the end of each incremental step and let the teacher guide the training of the student in the next step. In this way, the student network is able to learn new information from the streaming data and retain old knowledge from the teacher network simultaneously. Given that not all information from the teacher network is helpful since it is only trained with the old data, we further introduce a random inquirer and an uncertainty-based filter to filter useful information. We conduct experiments on the NeRF-synthetic360 and NeRF-real360 datasets, where our approach significantly outperforms the baselines by 7.3% and 25.2% in terms of PSNR. Furthermore, we also show that our approach can be applied to the large-scale camera facing-outwards dataset ScanNet, where we surpass the baseline by 60.0% in PSNR.
CGPart: A Part Segmentation Dataset Based on 3D Computer Graphics Models
Mar 25, 2021
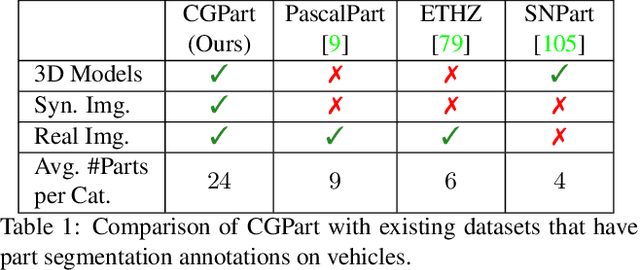
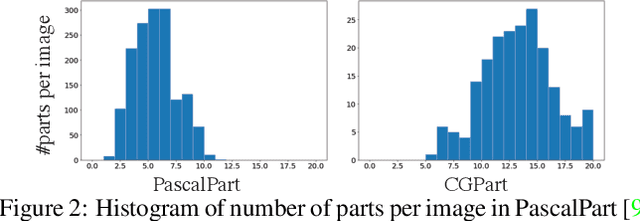
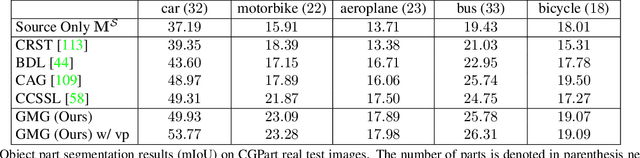
Part segmentations provide a rich and detailed part-level description of objects, but their annotation requires an enormous amount of work. In this paper, we introduce CGPart, a comprehensive part segmentation dataset that provides detailed annotations on 3D CAD models, synthetic images, and real test images. CGPart includes $21$ 3D CAD models covering $5$ vehicle categories, each with detailed per-mesh part labeling. The average number of parts per category is $24$, which is larger than any existing datasets for part segmentation on vehicle objects. By varying the rendering parameters, we make $168,000$ synthetic images from these CAD models, each with automatically generated part segmentation ground-truth. We also annotate part segmentations on $200$ real images for evaluation purposes. To illustrate the value of CGPart, we apply it to image part segmentation through unsupervised domain adaptation (UDA). We evaluate several baseline methods by adapting top-performing UDA algorithms from related tasks to part segmentation. Moreover, we introduce a new method called Geometric-Matching Guided domain adaptation (GMG), which leverages the spatial object structure to guide the knowledge transfer from the synthetic to the real images. Experimental results demonstrate the advantage of our new algorithm and reveal insights for future improvement. We will release our data and code.
Unsupervised Part Discovery via Feature Alignment
Dec 01, 2020

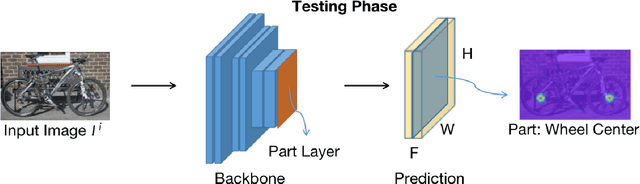

Understanding objects in terms of their individual parts is important, because it enables a precise understanding of the objects' geometrical structure, and enhances object recognition when the object is seen in a novel pose or under partial occlusion. However, the manual annotation of parts in large scale datasets is time consuming and expensive. In this paper, we aim at discovering object parts in an unsupervised manner, i.e., without ground-truth part or keypoint annotations. Our approach builds on the intuition that objects of the same class in a similar pose should have their parts aligned at similar spatial locations. We exploit the property that neural network features are largely invariant to nuisance variables and the main remaining source of variations between images of the same object category is the object pose. Specifically, given a training image, we find a set of similar images that show instances of the same object category in the same pose, through an affine alignment of their corresponding feature maps. The average of the aligned feature maps serves as pseudo ground-truth annotation for a supervised training of the deep network backbone. During inference, part detection is simple and fast, without any extra modules or overheads other than a feed-forward neural network. Our experiments on several datasets from different domains verify the effectiveness of the proposed method. For example, we achieve 37.8 mAP on VehiclePart, which is at least 4.2 better than previous methods.