 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditAR: Unified Conditional Generation with Autoregressive Models
Jan 08, 2025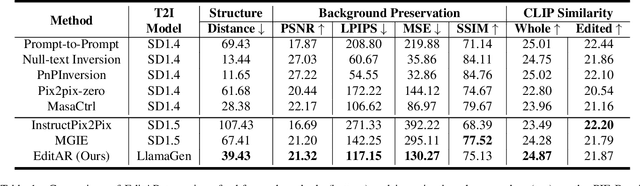
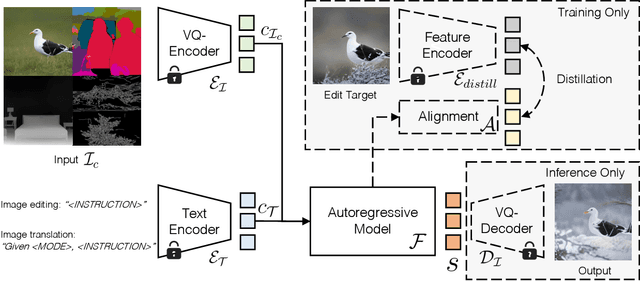
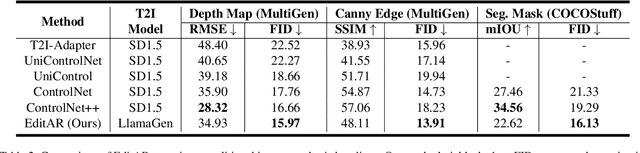

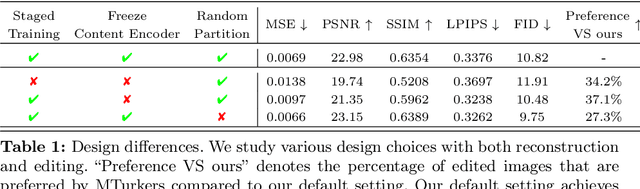
Recent progress in controllable image generation and editing is largely driven by diffusion-based methods. Although diffusion models perform exceptionally well in specific tasks with tailored designs, establishing a unified model is still challenging. In contrast, autoregressive models inherently feature a unified tokenized representation, which simplifies the creation of a single foundational model for various tasks. In this work, we propose EditAR, a single unified autoregressive framework for a variety of conditional image generation tasks, e.g., image editing, depth-to-image, edge-to-image, segmentation-to-image. The model takes both images and instructions as inputs, and predicts the edited images tokens in a vanilla next-token paradigm. To enhance the text-to-image alignment, we further propose to distill the knowledge from foundation models into the autoregressive modeling process. We evaluate its effectiveness across diverse tasks on established benchmarks, showing competitive performance to various state-of-the-art task-specific methods. Project page: https://jitengmu.github.io/EditAR/
IntroStyle: Training-Free Introspective Style Attribution using Diffusion Features
Dec 19, 2024



Text-to-image (T2I) models have gained widespread adoption among content creators and the general public. However, this has sparked significant concerns regarding data privacy and copyright infringement among artists. Consequently, there is an increasing demand for T2I models to incorporate mechanisms that prevent the generation of specific artistic styles, thereby safeguarding intellectual property rights. Existing methods for style extraction typically necessitate the collection of custom datasets and the training of specialized models. This, however, is resource-intensive, time-consuming, and often impractical for real-time applications. Moreover, it may not adequately address the dynamic nature of artistic styles and the rapidly evolving landscape of digital art. We present a novel, training-free framework to solve the style attribution problem, using the features produced by a diffusion model alone, without any external modules or retraining. This is denoted as introspective style attribution (IntroStyle) and demonstrates superior performance to state-of-the-art models for style retrieval. We also introduce a synthetic dataset of Style Hacks (SHacks) to isolate artistic style and evaluate fine-grained style attribution performance.
Editable Image Elements for Controllable Synthesis
Apr 24, 2024
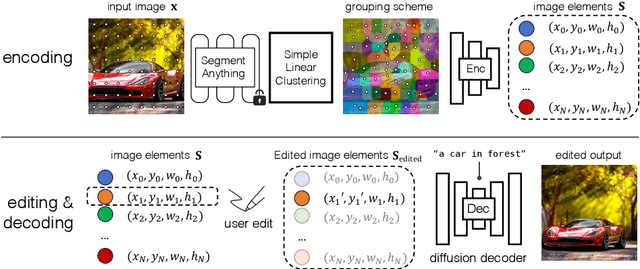
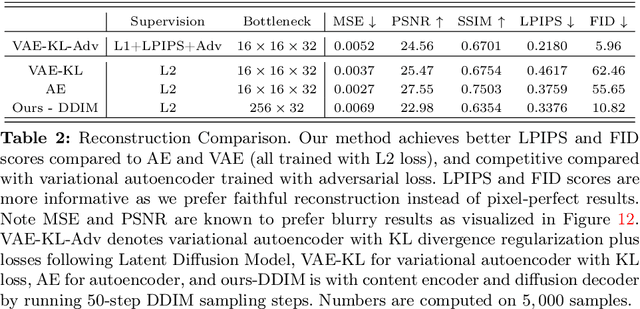
Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing. In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into "image elements" that can faithfully reconstruct an input image. These elements can be intuitively edited by a user, and are decoded by a diffusion model into realistic images. We show the effectiveness of our representation on various image editing tasks, such as object resizing, rearrangement, dragging, de-occlusion, removal, variation, and image composition. Project page: https://jitengmu.github.io/Editable_Image_Elements/
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024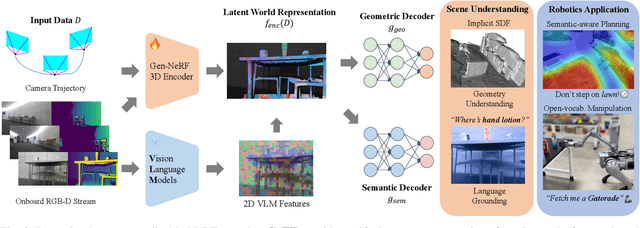


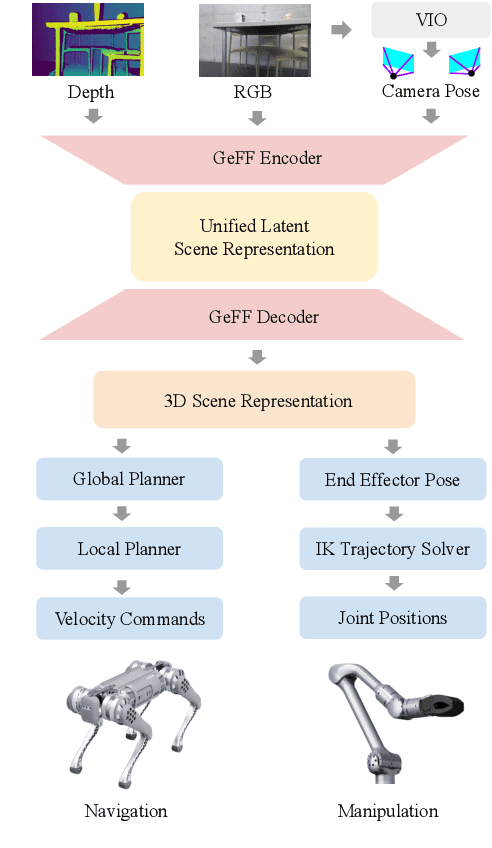
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Learning Part Segmentation from Synthetic Animals
Nov 30, 2023



Semantic part segmentation provides an intricate and interpretable understanding of an object, thereby benefiting numerous downstream tasks. However, the need for exhaustive annotations impedes its usage across diverse object types. This paper focuses on learning part segmentation from synthetic animals, leveraging the Skinned Multi-Animal Linear (SMAL) models to scale up existing synthetic data generated by computer-aided design (CAD) animal models. Compared to CAD models, SMAL models generate data with a wider range of poses observed in real-world scenarios. As a result, our first contribution is to construct a synthetic animal dataset of tigers and horses with more pose diversity, termed Synthetic Animal Parts (SAP). We then benchmark Syn-to-Real animal part segmentation from SAP to PartImageNet, namely SynRealPart, with existing semantic segmentation domain adaptation methods and further improve them as our second contribution. Concretely, we examine three Syn-to-Real adaptation methods but observe relative performance drop due to the innate difference between the two tasks. To address this, we propose a simple yet effective method called Class-Balanced Fourier Data Mixing (CB-FDM). Fourier Data Mixing aligns the spectral amplitudes of synthetic images with real images, thereby making the mixed images have more similar frequency content to real images. We further use Class-Balanced Pseudo-Label Re-Weighting to alleviate the imbalanced class distribution. We demonstrate the efficacy of CB-FDM on SynRealPart over previous methods with significant performance improvements. Remarkably, our third contribution is to reveal that the learned parts from synthetic tiger and horse are transferable across all quadrupeds in PartImageNet, further underscoring the utility and potential applications of animal part segmentation.
ActorsNeRF: Animatable Few-shot Human Rendering with Generalizable NeRFs
Apr 27, 2023



While NeRF-based human representations have shown impressive novel view synthesis results, most methods still rely on a large number of images / views for training. In this work, we propose a novel animatable NeRF called ActorsNeRF. It is first pre-trained on diverse human subjects, and then adapted with few-shot monocular video frames for a new actor with unseen poses. Building on previous generalizable NeRFs with parameter sharing using a ConvNet encoder, ActorsNeRF further adopts two human priors to capture the large human appearance, shape, and pose variations. Specifically, in the encoded feature space, we will first align different human subjects in a category-level canonical space, and then align the same human from different frames in an instance-level canonical space for rendering. We quantitatively and qualitatively demonstrate that ActorsNeRF significantly outperforms the existing state-of-the-art on few-shot generalization to new people and poses on multiple datasets. Project Page: https://jitengmu.github.io/ActorsNeRF/
CoordGAN: Self-Supervised Dense Correspondences Emerge from GANs
Mar 30, 2022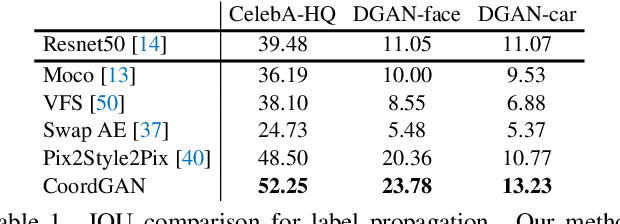
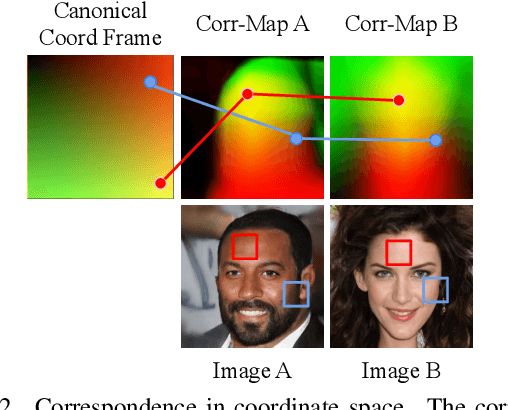
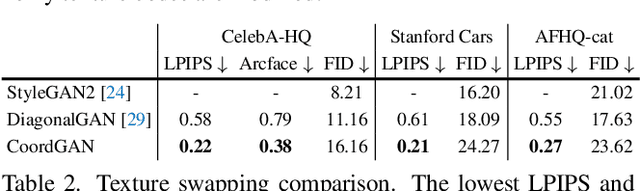
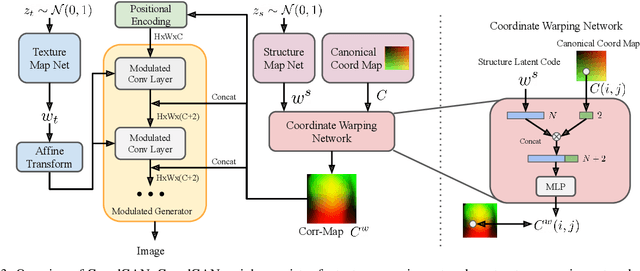
Recent advances show that Generative Adversarial Networks (GANs) can synthesize images with smooth variations along semantically meaningful latent directions, such as pose, expression, layout, etc. While this indicates that GANs implicitly learn pixel-level correspondences across images, few studies explored how to extract them explicitly. In this work, we introduce Coordinate GAN (CoordGAN), a structure-texture disentangled GAN that learns a dense correspondence map for each generated image. We represent the correspondence maps of different images as warped coordinate frames transformed from a canonical coordinate frame, i.e., the correspondence map, which describes the structure (e.g., the shape of a face), is controlled via a transformation. Hence, finding correspondences boils down to locating the same coordinate in different correspondence maps. In CoordGAN, we sample a transformation to represent the structure of a synthesized instance, while an independent texture branch is responsible for rendering appearance details orthogonal to the structure. Our approach can also extract dense correspondence maps for real images by adding an encoder on top of the generator. We quantitatively demonstrate the quality of the learned dense correspondences through segmentation mask transfer on multiple datasets. We also show that the proposed generator achieves better structure and texture disentanglement compared to existing approaches. Project page: https://jitengmu.github.io/CoordGAN/
A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation
Apr 15, 2021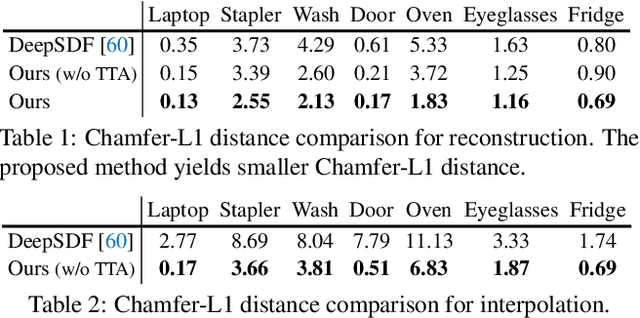
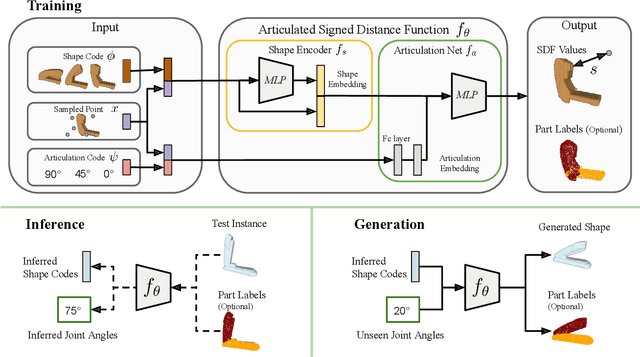
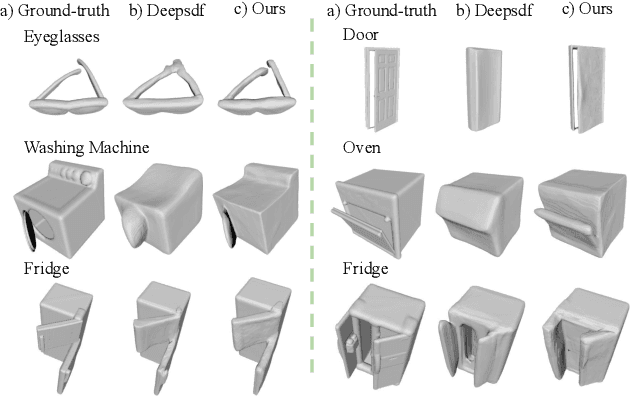

Recent work has made significant progress on using implicit functions, as a continuous representation for 3D rigid object shape reconstruction. However, much less effort has been devoted to modeling general articulated objects. Compared to rigid objects, articulated objects have higher degrees of freedom, which makes it hard to generalize to unseen shapes. To deal with the large shape variance, we introduce Articulated Signed Distance Functions (A-SDF) to represent articulated shapes with a disentangled latent space, where we have separate codes for encoding shape and articulation. We assume no prior knowledge on part geometry, articulation status, joint type, joint axis, and joint location. With this disentangled continuous representation, we demonstrate that we can control the articulation input and animate unseen instances with unseen joint angles. Furthermore, we propose a Test-Time Adaptation inference algorithm to adjust our model during inference. We demonstrate our model generalize well to out-of-distribution and unseen data, e.g., partial point clouds and real-world depth images.
CGPart: A Part Segmentation Dataset Based on 3D Computer Graphics Models
Mar 25, 2021
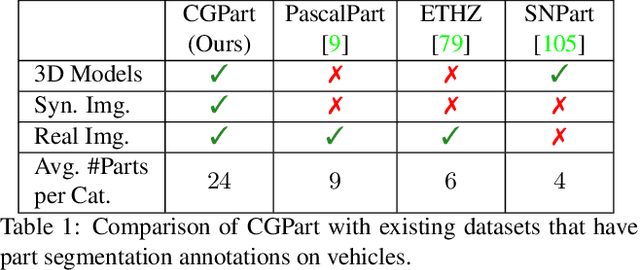
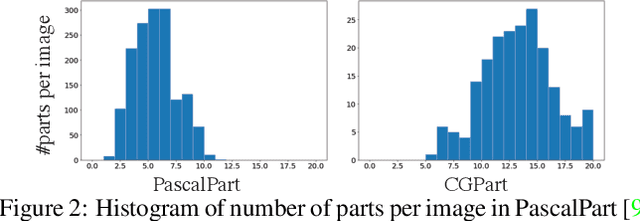
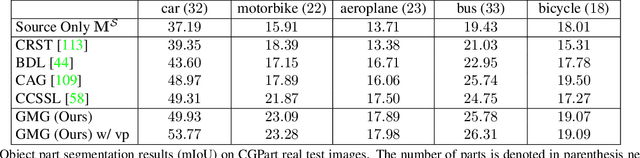
Part segmentations provide a rich and detailed part-level description of objects, but their annotation requires an enormous amount of work. In this paper, we introduce CGPart, a comprehensive part segmentation dataset that provides detailed annotations on 3D CAD models, synthetic images, and real test images. CGPart includes $21$ 3D CAD models covering $5$ vehicle categories, each with detailed per-mesh part labeling. The average number of parts per category is $24$, which is larger than any existing datasets for part segmentation on vehicle objects. By varying the rendering parameters, we make $168,000$ synthetic images from these CAD models, each with automatically generated part segmentation ground-truth. We also annotate part segmentations on $200$ real images for evaluation purposes. To illustrate the value of CGPart, we apply it to image part segmentation through unsupervised domain adaptation (UDA). We evaluate several baseline methods by adapting top-performing UDA algorithms from related tasks to part segmentation. Moreover, we introduce a new method called Geometric-Matching Guided domain adaptation (GMG), which leverages the spatial object structure to guide the knowledge transfer from the synthetic to the real images. Experimental results demonstrate the advantage of our new algorithm and reveal insights for future improvement. We will release our data and code.
Learning from Synthetic Animals
Dec 17, 2019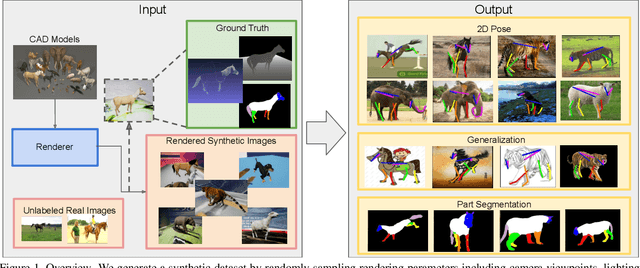
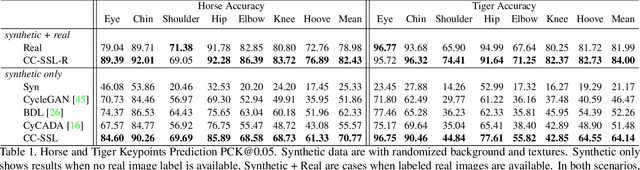
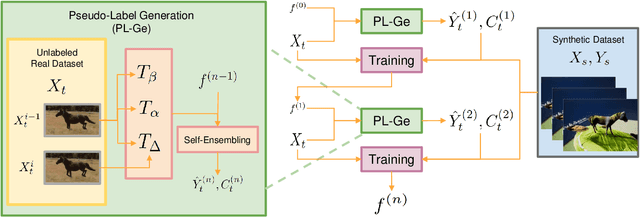

Despite great success in human parsing, progress for parsing other deformable articulated objects, like animals, is still limited by the lack of labeled data. In this paper, we use synthetic images and ground truth generated from CAD animal models to address this challenge. To bridge the gap between real and synthetic images, we propose a novel consistency-constrained semi-supervised learning method (CC-SSL). Our method leverages both spatial and temporal consistencies, to bootstrap weak models trained on synthetic data with unlabeled real images. We demonstrate the effectiveness of our method on highly deformable animals, such as horses and tigers. Without using any real image label, our method allows for accurate keypoints prediction on real images. Moreover, we quantitatively show that models using synthetic data achieve better generalization performance than models trained on real images across different domains in the Visual Domain Adaptation Challenge dataset. Our synthetic dataset contains 10+ animals with diverse poses and rich ground truth, which enables us to use the multi-task learning strategy to further boost models' performance.