 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMS-IO-Bench and AMS-IO-Agent: Benchmarking and Structured Reasoning for Analog and Mixed-Signal Integrated Circuit Input/Output Design
Dec 25, 2025In this paper, we propose AMS-IO-Agent, a domain-specialized LLM-based agent for structure-aware input/output (I/O) subsystem generation in analog and mixed-signal (AMS) integrated circuits (ICs). The central contribution of this work is a framework that connects natural language design intent with industrial-level AMS IC design deliverables. AMS-IO-Agent integrates two key capabilities: (1) a structured domain knowledge base that captures reusable constraints and design conventions; (2) design intent structuring, which converts ambiguous user intent into verifiable logic steps using JSON and Python as intermediate formats. We further introduce AMS-IO-Bench, a benchmark for wirebond-packaged AMS I/O ring automation. On this benchmark, AMS-IO-Agent achieves over 70\% DRC+LVS pass rate and reduces design turnaround time from hours to minutes, outperforming the baseline LLM. Furthermore, an agent-generated I/O ring was fabricated and validated in a 28 nm CMOS tape-out, demonstrating the practical effectiveness of the approach in real AMS IC design flows. To our knowledge, this is the first reported human-agent collaborative AMS IC design in which an LLM-based agent completes a nontrivial subtask with outputs directly used in silicon.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
De-Diffusion Makes Text a Strong Cross-Modal Interface
Nov 01, 2023



We demonstrate text as a strong cross-modal interface. Rather than relying on deep embeddings to connect image and language as the interface representation, our approach represents an image as text, from which we enjoy the interpretability and flexibility inherent to natural language. We employ an autoencoder that uses a pre-trained text-to-image diffusion model for decoding. The encoder is trained to transform an input image into text, which is then fed into the fixed text-to-image diffusion decoder to reconstruct the original input -- a process we term De-Diffusion. Experiments validate both the precision and comprehensiveness of De-Diffusion text representing images, such that it can be readily ingested by off-the-shelf text-to-image tools and LLMs for diverse multi-modal tasks. For example, a single De-Diffusion model can generalize to provide transferable prompts for different text-to-image tools, and also achieves a new state of the art on open-ended vision-language tasks by simply prompting large language models with few-shot examples.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023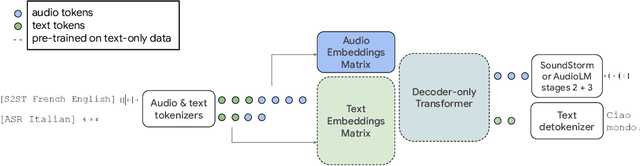



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Pedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023



Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
Noise2Music: Text-conditioned Music Generation with Diffusion Models
Feb 08, 2023

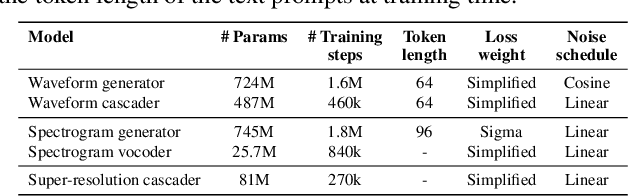
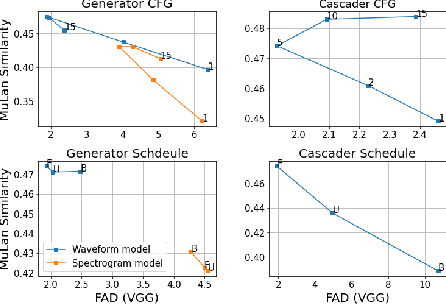
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
CGPart: A Part Segmentation Dataset Based on 3D Computer Graphics Models
Mar 25, 2021
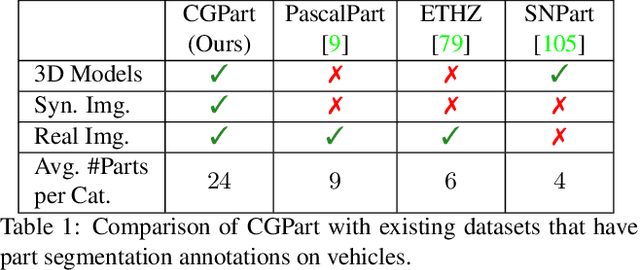
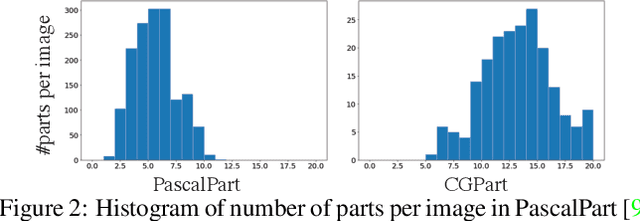
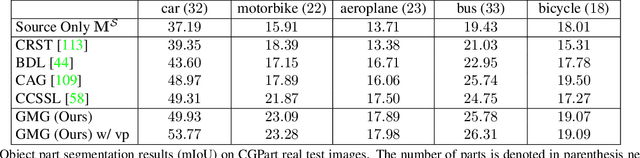
Part segmentations provide a rich and detailed part-level description of objects, but their annotation requires an enormous amount of work. In this paper, we introduce CGPart, a comprehensive part segmentation dataset that provides detailed annotations on 3D CAD models, synthetic images, and real test images. CGPart includes $21$ 3D CAD models covering $5$ vehicle categories, each with detailed per-mesh part labeling. The average number of parts per category is $24$, which is larger than any existing datasets for part segmentation on vehicle objects. By varying the rendering parameters, we make $168,000$ synthetic images from these CAD models, each with automatically generated part segmentation ground-truth. We also annotate part segmentations on $200$ real images for evaluation purposes. To illustrate the value of CGPart, we apply it to image part segmentation through unsupervised domain adaptation (UDA). We evaluate several baseline methods by adapting top-performing UDA algorithms from related tasks to part segmentation. Moreover, we introduce a new method called Geometric-Matching Guided domain adaptation (GMG), which leverages the spatial object structure to guide the knowledge transfer from the synthetic to the real images. Experimental results demonstrate the advantage of our new algorithm and reveal insights for future improvement. We will release our data and code.
Unsupervised Part Discovery via Feature Alignment
Dec 01, 2020

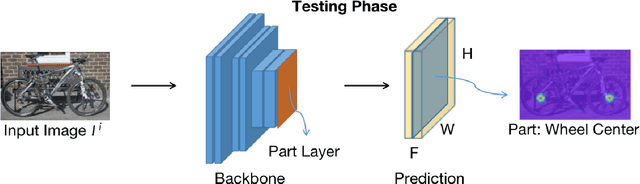

Understanding objects in terms of their individual parts is important, because it enables a precise understanding of the objects' geometrical structure, and enhances object recognition when the object is seen in a novel pose or under partial occlusion. However, the manual annotation of parts in large scale datasets is time consuming and expensive. In this paper, we aim at discovering object parts in an unsupervised manner, i.e., without ground-truth part or keypoint annotations. Our approach builds on the intuition that objects of the same class in a similar pose should have their parts aligned at similar spatial locations. We exploit the property that neural network features are largely invariant to nuisance variables and the main remaining source of variations between images of the same object category is the object pose. Specifically, given a training image, we find a set of similar images that show instances of the same object category in the same pose, through an affine alignment of their corresponding feature maps. The average of the aligned feature maps serves as pseudo ground-truth annotation for a supervised training of the deep network backbone. During inference, part detection is simple and fast, without any extra modules or overheads other than a feed-forward neural network. Our experiments on several datasets from different domains verify the effectiveness of the proposed method. For example, we achieve 37.8 mAP on VehiclePart, which is at least 4.2 better than previous methods.
STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction
May 08, 2020

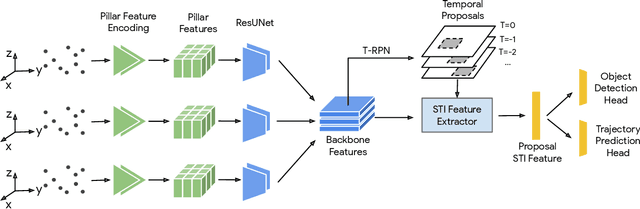
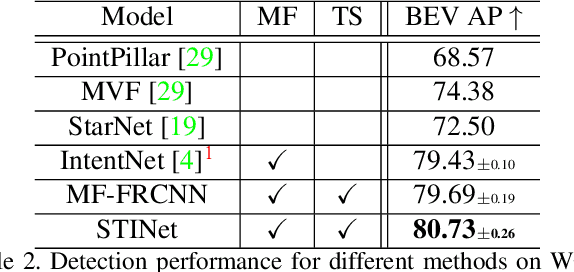
Detecting pedestrians and predicting future trajectories for them are critical tasks for numerous applications, such as autonomous driving. Previous methods either treat the detection and prediction as separate tasks or simply add a trajectory regression head on top of a detector. In this work, we present a novel end-to-end two-stage network: Spatio-Temporal-Interactive Network (STINet). In addition to 3D geometry modeling of pedestrians, we model the temporal information for each of the pedestrians. To do so, our method predicts both current and past locations in the first stage, so that each pedestrian can be linked across frames and the comprehensive spatio-temporal information can be captured in the second stage. Also, we model the interaction among objects with an interaction graph, to gather the information among the neighboring objects. Comprehensive experiments on the Lyft Dataset and the recently released large-scale Waymo Open Dataset for both object detection and future trajectory prediction validate the effectiveness of the proposed method. For the Waymo Open Dataset, we achieve a bird-eyes-view (BEV) detection AP of 80.73 and trajectory prediction average displacement error (ADE) of 33.67cm for pedestrians, which establish the state-of-the-art for both tasks.