 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Crossing Action Recognition and Trajectory Prediction with 3D Human Keypoints
Jun 01, 2023



Accurate understanding and prediction of human behaviors are critical prerequisites for autonomous vehicles, especially in highly dynamic and interactive scenarios such as intersections in dense urban areas. In this work, we aim at identifying crossing pedestrians and predicting their future trajectories. To achieve these goals, we not only need the context information of road geometry and other traffic participants but also need fine-grained information of the human pose, motion and activity, which can be inferred from human keypoints. In this paper, we propose a novel multi-task learning framework for pedestrian crossing action recognition and trajectory prediction, which utilizes 3D human keypoints extracted from raw sensor data to capture rich information on human pose and activity. Moreover, we propose to apply two auxiliary tasks and contrastive learning to enable auxiliary supervisions to improve the learned keypoints representation, which further enhances the performance of major tasks. We validate our approach on a large-scale in-house dataset, as well as a public benchmark dataset, and show that our approach achieves state-of-the-art performance on a wide range of evaluation metrics. The effectiveness of each model component is validated in a detailed ablation study.
Fill-in-the-blank as a Challenging Video Understanding Evaluation Framework
Apr 09, 2021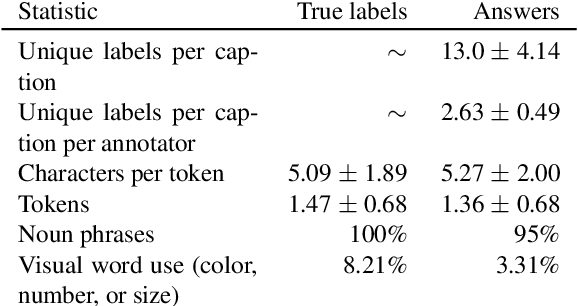
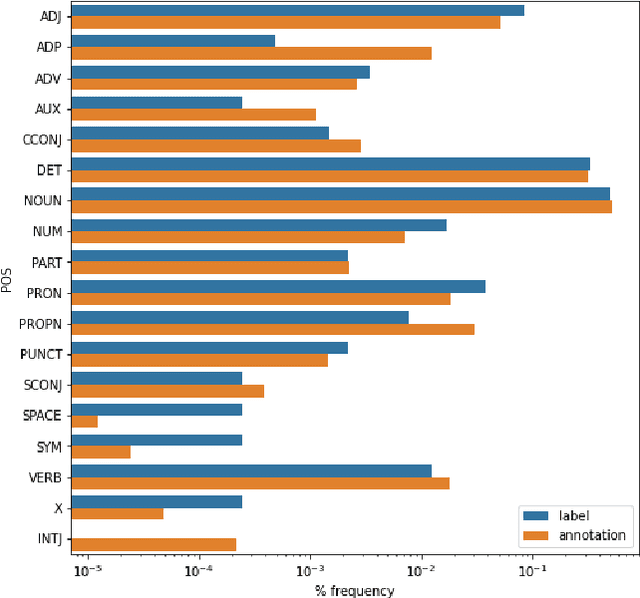
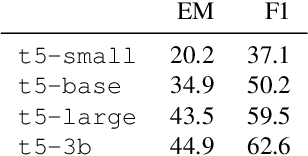
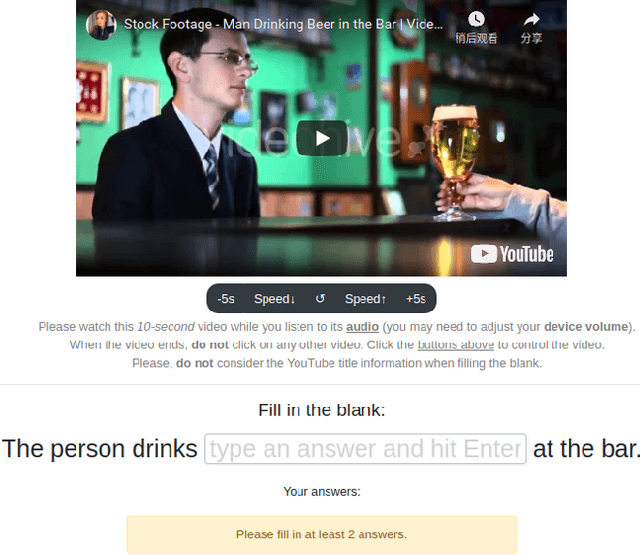
Work to date on language-informed video understanding has primarily addressed two tasks: (1) video question answering using multiple-choice questions, where models perform relatively well because they exploit the fact that candidate answers are readily available; and (2) video captioning, which relies on an open-ended evaluation framework that is often inaccurate because system answers may be perceived as incorrect if they differ in form from the ground truth. In this paper, we propose fill-in-the-blanks as a video understanding evaluation framework that addresses these previous evaluation drawbacks, and more closely reflects real-life settings where no multiple choices are given. The task tests a system understanding of a video by requiring the model to predict a masked noun phrase in the caption of the video, given the video and the surrounding text. We introduce a novel dataset consisting of 28,000 videos and fill-in-the-blank tests. We show that both a multimodal model and a strong language model have a large gap with human performance, thus suggesting that the task is more challenging than current video understanding benchmarks.
Flint Water Crisis: Data-Driven Risk Assessment Via Residential Water Testing
Sep 30, 2016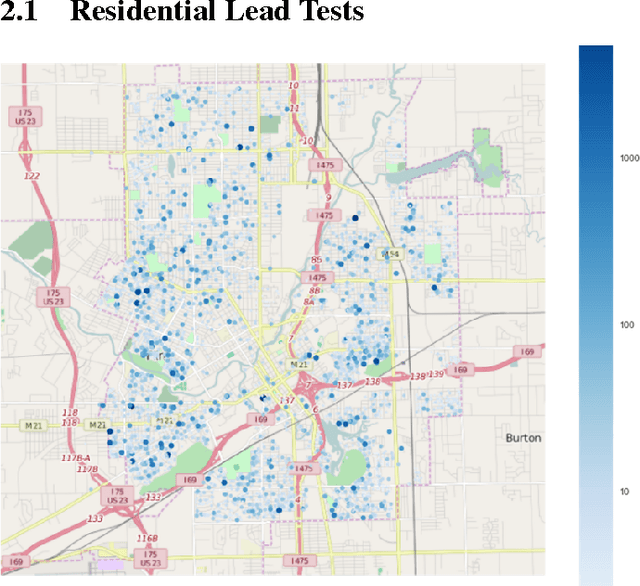

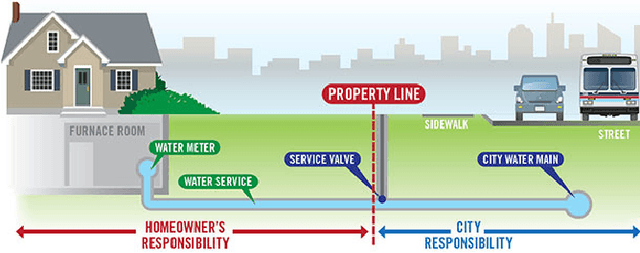
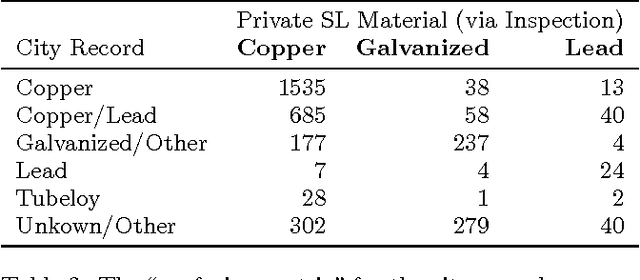
Recovery from the Flint Water Crisis has been hindered by uncertainty in both the water testing process and the causes of contamination. In this work, we develop an ensemble of predictive models to assess the risk of lead contamination in individual homes and neighborhoods. To train these models, we utilize a wide range of data sources, including voluntary residential water tests, historical records, and city infrastructure data. Additionally, we use our models to identify the most prominent factors that contribute to a high risk of lead contamination. In this analysis, we find that lead service lines are not the only factor that is predictive of the risk of lead contamination of water. These results could be used to guide the long-term recovery efforts in Flint, minimize the immediate damages, and improve resource-allocation decisions for similar water infrastructure crises.
Data Science in Service of Performing Arts: Applying Machine Learning to Predicting Audience Preferences
Sep 30, 2016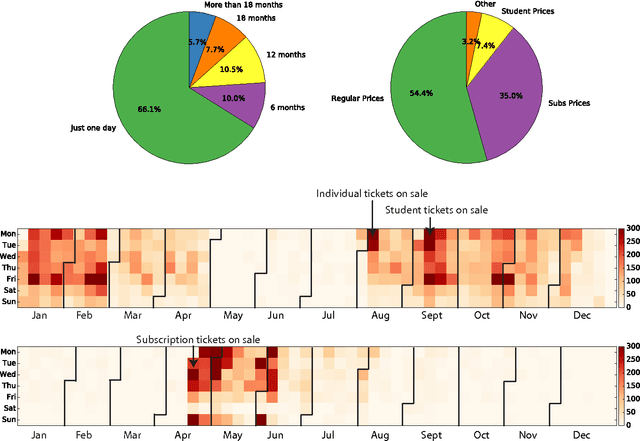
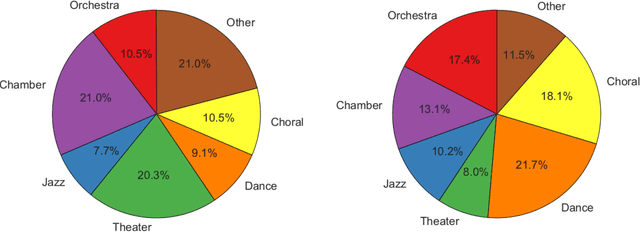
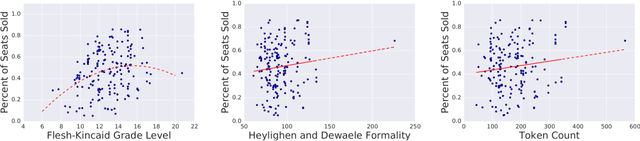
Performing arts organizations aim to enrich their communities through the arts. To do this, they strive to match their performance offerings to the taste of those communities. Success relies on understanding audience preference and predicting their behavior. Similar to most e-commerce or digital entertainment firms, arts presenters need to recommend the right performance to the right customer at the right time. As part of the Michigan Data Science Team (MDST), we partnered with the University Musical Society (UMS), a non-profit performing arts presenter housed in the University of Michigan, Ann Arbor. We are providing UMS with analysis and business intelligence, utilizing historical individual-level sales data. We built a recommendation system based on collaborative filtering, gaining insights into the artistic preferences of customers, along with the similarities between performances. To better understand audience behavior, we used statistical methods from customer-base analysis. We characterized customer heterogeneity via segmentation, and we modeled customer cohorts to understand and predict ticket purchasing patterns. Finally, we combined statistical modeling with natural language processing (NLP) to explore the impact of wording in program descriptions. These ongoing efforts provide a platform to launch targeted marketing campaigns, helping UMS carry out its mission by allocating its resources more efficiently. Celebrating its 138th season, UMS is a 2014 recipient of the National Medal of Arts, and it continues to enrich communities by connecting world-renowned artists with diverse audiences, especially students in their formative years. We aim to contribute to that mission through data science and customer analytics.