 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Problem Generation for Reasoning via Quality-Diversity Algorithms
Jun 06, 2025Large language model (LLM) driven synthetic data generation has emerged as a powerful method for improving model reasoning capabilities. However, most methods either distill large state-of-the-art models into small students or use natural ground-truth problem statements to guarantee problem statement quality. This limits the scalability of these approaches to more complex and diverse problem domains. To address this, we present SPARQ: Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms, a novel approach for generating high-quality and diverse synthetic math problem and solution pairs using only a single model by measuring a problem's solve-rate: a proxy for problem difficulty. Starting from a seed dataset of 7.5K samples, we generate over 20 million new problem-solution pairs. We show that filtering the generated data by difficulty and then fine-tuning the same model on the resulting data improves relative model performance by up to 24\%. Additionally, we conduct ablations studying the impact of synthetic data quantity, quality and diversity on model generalization. We find that higher quality, as measured by problem difficulty, facilitates better in-distribution performance. Further, while generating diverse synthetic data does not as strongly benefit in-distribution performance, filtering for more diverse data facilitates more robust OOD generalization. We also confirm the existence of model and data scaling laws for synthetically generated problems, which positively benefit downstream model generalization.
Can Transformers Reason Logically? A Study in SAT Solving
Oct 09, 2024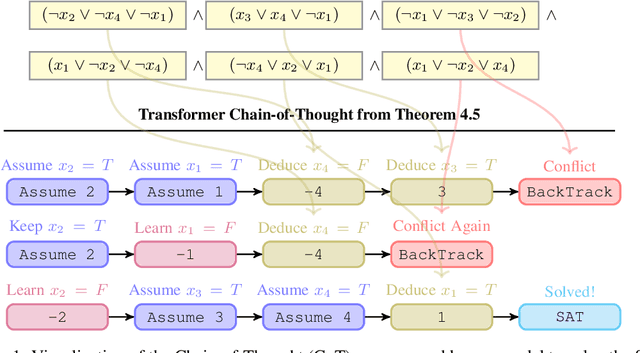
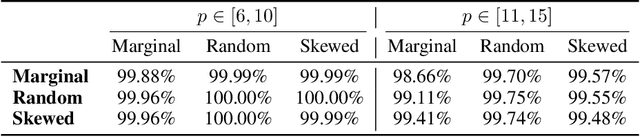
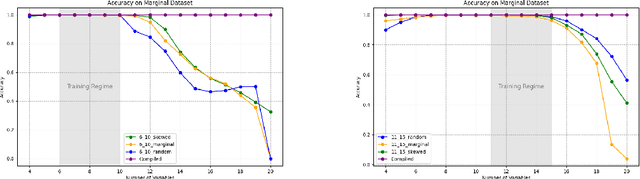
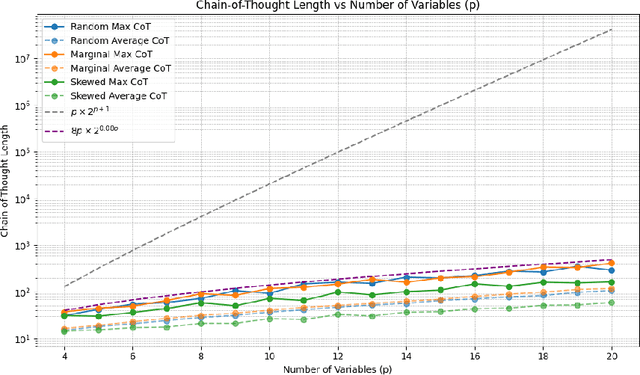
We theoretically and empirically study the logical reasoning capabilities of LLMs in the context of the Boolean satisfiability (SAT) problem. First, we construct a decoder-only Transformer that can solve SAT using backtracking and deduction via Chain-of-Thought (CoT). We prove its correctness by showing trace equivalence to the well-known DPLL SAT-solving algorithm. Second, to support the implementation of this abstract construction, we design a compiler $\texttt{PARAT}$ that takes as input a procedural specification and outputs a transformer model implementing this specification. Third, rather than $\textit{programming}$ a transformer to reason, we evaluate empirically whether it can be $\textit{trained}$ to do so by learning directly from algorithmic traces ("reasoning paths") of the DPLL algorithm.
Extragradient Type Methods for Riemannian Variational Inequality Problems
Sep 25, 2023

Riemannian convex optimization and minimax optimization have recently drawn considerable attention. Their appeal lies in their capacity to adeptly manage the non-convexity of the objective function as well as constraints inherent in the feasible set in the Euclidean sense. In this work, we delve into monotone Riemannian Variational Inequality Problems (RVIPs), which encompass both Riemannian convex optimization and minimax optimization as particular cases. In the context of Euclidean space, it is established that the last-iterates of both the extragradient (EG) and past extragradient (PEG) methods converge to the solution of monotone variational inequality problems at a rate of $O\left(\frac{1}{\sqrt{T}}\right)$ (Cai et al., 2022). However, analogous behavior on Riemannian manifolds remains an open question. To bridge this gap, we introduce the Riemannian extragradient (REG) and Riemannian past extragradient (RPEG) methods. We demonstrate that both exhibit $O\left(\frac{1}{\sqrt{T}}\right)$ last-iterate convergence. Additionally, we show that the average-iterate convergence of both REG and RPEG is $O\left(\frac{1}{{T}}\right)$, aligning with observations in the Euclidean case (Mokhtari et al., 2020). These results are enabled by judiciously addressing the holonomy effect so that additional complications in Riemannian cases can be reduced and the Euclidean proof inspired by the performance estimation problem (PEP) technique or the sum-of-squares (SOS) technique can be applied again.
On the Robustness of Epoch-Greedy in Multi-Agent Contextual Bandit Mechanisms
Jul 15, 2023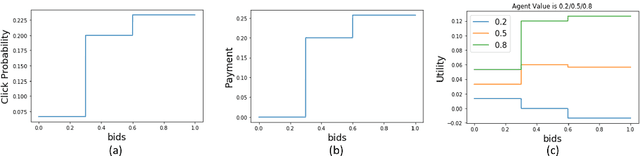
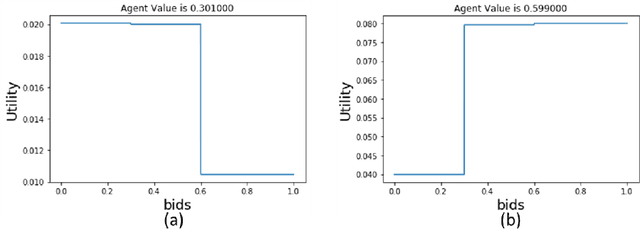
Efficient learning in multi-armed bandit mechanisms such as pay-per-click (PPC) auctions typically involves three challenges: 1) inducing truthful bidding behavior (incentives), 2) using personalization in the users (context), and 3) circumventing manipulations in click patterns (corruptions). Each of these challenges has been studied orthogonally in the literature; incentives have been addressed by a line of work on truthful multi-armed bandit mechanisms, context has been extensively tackled by contextual bandit algorithms, while corruptions have been discussed via a recent line of work on bandits with adversarial corruptions. Since these challenges co-exist, it is important to understand the robustness of each of these approaches in addressing the other challenges, provide algorithms that can handle all simultaneously, and highlight inherent limitations in this combination. In this work, we show that the most prominent contextual bandit algorithm, $\epsilon$-greedy can be extended to handle the challenges introduced by strategic arms in the contextual multi-arm bandit mechanism setting. We further show that $\epsilon$-greedy is inherently robust to adversarial data corruption attacks and achieves performance that degrades linearly with the amount of corruption.
Randomized Quantization is All You Need for Differential Privacy in Federated Learning
Jun 20, 2023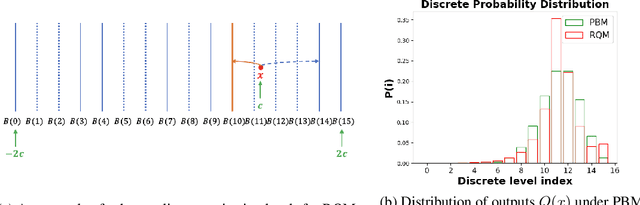


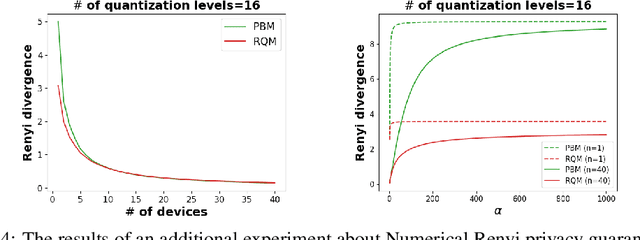
Federated learning (FL) is a common and practical framework for learning a machine model in a decentralized fashion. A primary motivation behind this decentralized approach is data privacy, ensuring that the learner never sees the data of each local source itself. Federated learning then comes with two majors challenges: one is handling potentially complex model updates between a server and a large number of data sources; the other is that de-centralization may, in fact, be insufficient for privacy, as the local updates themselves can reveal information about the sources' data. To address these issues, we consider an approach to federated learning that combines quantization and differential privacy. Absent privacy, Federated Learning often relies on quantization to reduce communication complexity. We build upon this approach and develop a new algorithm called the \textbf{R}andomized \textbf{Q}uantization \textbf{M}echanism (RQM), which obtains privacy through a two-levels of randomization. More precisely, we randomly sub-sample feasible quantization levels, then employ a randomized rounding procedure using these sub-sampled discrete levels. We are able to establish that our results preserve ``Renyi differential privacy'' (Renyi DP). We empirically study the performance of our algorithm and demonstrate that compared to previous work it yields improved privacy-accuracy trade-offs for DP federated learning. To the best of our knowledge, this is the first study that solely relies on randomized quantization without incorporating explicit discrete noise to achieve Renyi DP guarantees in Federated Learning systems.
On Riemannian Projection-free Online Learning
May 30, 2023
The projection operation is a critical component in a wide range of optimization algorithms, such as online gradient descent (OGD), for enforcing constraints and achieving optimal regret bounds. However, it suffers from computational complexity limitations in high-dimensional settings or when dealing with ill-conditioned constraint sets. Projection-free algorithms address this issue by replacing the projection oracle with more efficient optimization subroutines. But to date, these methods have been developed primarily in the Euclidean setting, and while there has been growing interest in optimization on Riemannian manifolds, there has been essentially no work in trying to utilize projection-free tools here. An apparent issue is that non-trivial affine functions are generally non-convex in such domains. In this paper, we present methods for obtaining sub-linear regret guarantees in online geodesically convex optimization on curved spaces for two scenarios: when we have access to (a) a separation oracle or (b) a linear optimization oracle. For geodesically convex losses, and when a separation oracle is available, our algorithms achieve $O(T^{1/2}\:)$ and $O(T^{3/4}\;)$ adaptive regret guarantees in the full information setting and the bandit setting, respectively. When a linear optimization oracle is available, we obtain regret rates of $O(T^{3/4}\;)$ for geodesically convex losses and $O(T^{2/3}\; log T )$ for strongly geodesically convex losses
Faster Margin Maximization Rates for Generic Optimization Methods
May 27, 2023

First-order optimization methods tend to inherently favor certain solutions over others when minimizing a given training objective with multiple local optima. This phenomenon, known as implicit bias, plays a critical role in understanding the generalization capabilities of optimization algorithms. Recent research has revealed that gradient-descent-based methods exhibit an implicit bias for the $\ell_2$-maximal margin classifier in the context of separable binary classification. In contrast, generic optimization methods, such as mirror descent and steepest descent, have been shown to converge to maximal margin classifiers defined by alternative geometries. However, while gradient-descent-based algorithms demonstrate fast implicit bias rates, the implicit bias rates of generic optimization methods have been relatively slow. To address this limitation, in this paper, we present a series of state-of-the-art implicit bias rates for mirror descent and steepest descent algorithms. Our primary technique involves transforming a generic optimization algorithm into an online learning dynamic that solves a regularized bilinear game, providing a unified framework for analyzing the implicit bias of various optimization methods. The accelerated rates are derived leveraging the regret bounds of online learning algorithms within this game framework.
A Mechanism for Sample-Efficient In-Context Learning for Sparse Retrieval Tasks
May 26, 2023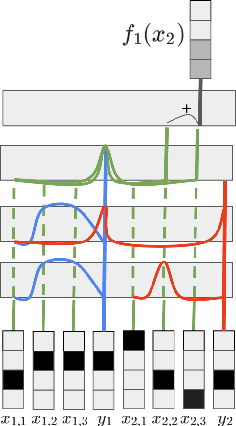



We study the phenomenon of \textit{in-context learning} (ICL) exhibited by large language models, where they can adapt to a new learning task, given a handful of labeled examples, without any explicit parameter optimization. Our goal is to explain how a pre-trained transformer model is able to perform ICL under reasonable assumptions on the pre-training process and the downstream tasks. We posit a mechanism whereby a transformer can achieve the following: (a) receive an i.i.d. sequence of examples which have been converted into a prompt using potentially-ambiguous delimiters, (b) correctly segment the prompt into examples and labels, (c) infer from the data a \textit{sparse linear regressor} hypothesis, and finally (d) apply this hypothesis on the given test example and return a predicted label. We establish that this entire procedure is implementable using the transformer mechanism, and we give sample complexity guarantees for this learning framework. Our empirical findings validate the challenge of segmentation, and we show a correspondence between our posited mechanisms and observed attention maps for step (c).
Minimizing Dynamic Regret on Geodesic Metric Spaces
Feb 17, 2023
In this paper, we consider the sequential decision problem where the goal is to minimize the general dynamic regret on a complete Riemannian manifold. The task of offline optimization on such a domain, also known as a geodesic metric space, has recently received significant attention. The online setting has received significantly less attention, and it has remained an open question whether the body of results that hold in the Euclidean setting can be transplanted into the land of Riemannian manifolds where new challenges (e.g., curvature) come into play. In this paper, we show how to get optimistic regret bound on manifolds with non-positive curvature whenever improper learning is allowed and propose an array of adaptive no-regret algorithms. To the best of our knowledge, this is the first work that considers general dynamic regret and develops "optimistic" online learning algorithms which can be employed on geodesic metric spaces.
On Accelerated Perceptrons and Beyond
Oct 17, 2022The classical Perceptron algorithm of Rosenblatt can be used to find a linear threshold function to correctly classify $n$ linearly separable data points, assuming the classes are separated by some margin $\gamma > 0$. A foundational result is that Perceptron converges after $\Omega(1/\gamma^{2})$ iterations. There have been several recent works that managed to improve this rate by a quadratic factor, to $\Omega(\sqrt{\log n}/\gamma)$, with more sophisticated algorithms. In this paper, we unify these existing results under one framework by showing that they can all be described through the lens of solving min-max problems using modern acceleration techniques, mainly through optimistic online learning. We then show that the proposed framework also lead to improved results for a series of problems beyond the standard Perceptron setting. Specifically, a) For the margin maximization problem, we improve the state-of-the-art result from $O(\log t/t^2)$ to $O(1/t^2)$, where $t$ is the number of iterations; b) We provide the first result on identifying the implicit bias property of the classical Nesterov's accelerated gradient descent (NAG) algorithm, and show NAG can maximize the margin with an $O(1/t^2)$ rate; c) For the classical $p$-norm Perceptron problem, we provide an algorithm with $\Omega(\sqrt{(p-1)\log n}/\gamma)$ convergence rate, while existing algorithms suffer the $\Omega({(p-1)}/\gamma^2)$ convergence rate.