 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Convex Optimization via Hamiltonian Dynamics with Deterministic Integration Time
Jun 15, 2026We develop Hamiltonian dynamics-based algorithms for smooth convex optimization that achieve accelerated rates of convergence. By exploiting contraction of averaged Hamiltonian flow trajectories rather than requiring contraction at trajectory endpoints, we show that Hamiltonian dynamics-based optimization methods admit deterministic and accelerated convergence guarantees, extending prior work that is limited to quadratic objectives or holds only in expectation. We analyze an idealized continuous-time algorithm and derive practical discrete-time implementations with optimal first-order complexity, thereby establishing Hamiltonian dynamics as a useful algorithmic primitive for deterministic accelerated convex optimization.
When and Why is Optimistic Multiplicative Weights Slow? The Geometry of Energy Dissipation
May 13, 2026This paper studies the convergence of the Optimistic Multiplicative Weights Update algorithm (OMWU) in two player zero-sum games. Recent works have identified instances on which the last-iterate of OMWU can converge arbitrarily slowly, but understanding when and why this slow convergence occurs has remained open. In this work, we develop a new analysis framework that gives sharp, quantitative explanations for this behavior. Our analysis is based on viewing the algorithm's dual iterates as an optimistic skew-gradient descent with respect to an energy function. We prove over the dual iterates that energy is dissipative, and by establishing tight bounds on the magnitude of dissipation, our analysis quantifies the geometric bottlenecks that arise when the corresponding primal iterates are close to the simplex boundary. This further translates into a new linear last-iterate convergence rate in KL divergence on games with a unique and interior Nash equilibrium. Compared to prior work, this new rate contains a much sharper dependence on game-specific constants, and we prove this dependence is optimal. Moreover, these geometric insights further translate into new separations on uniform convergence rates for OMWU. On the one hand, we prove constant lower bounds on the uniform best-iterate convergence rate in KL divergence and total variation distance from Nash. On the other hand, we establish for the $2\times 2$ setting a new ${\widetilde O}(T^{-1/2})$ best-iterate rate in duality gap, improving substantially over prior work. Together, this shows in general that uniform convergence rate guarantees do not transfer across different measures of distance to Nash.
The Geometry of Efficient Nonconvex Sampling
Mar 26, 2026We present an efficient algorithm for uniformly sampling from an arbitrary compact body $\mathcal{X} \subset \mathbb{R}^n$ from a warm start under isoperimetry and a natural volume growth condition. Our result provides a substantial common generalization of known results for convex bodies and star-shaped bodies. The complexity of the algorithm is polynomial in the dimension, the Poincaré constant of the uniform distribution on $\mathcal{X}$ and the volume growth constant of the set $\mathcal{X}$.
Tail-Sensitive KL and Rényi Convergence of Unadjusted Hamiltonian Monte Carlo via One-Shot Couplings
Jan 13, 2026Hamiltonian Monte Carlo (HMC) algorithms are among the most widely used sampling methods in high dimensional settings, yet their convergence properties are poorly understood in divergences that quantify relative density mismatch, such as Kullback-Leibler (KL) and Rényi divergences. These divergences naturally govern acceptance probabilities and warm-start requirements for Metropolis-adjusted Markov chains. In this work, we develop a framework for upgrading Wasserstein convergence guarantees for unadjusted Hamiltonian Monte Carlo (uHMC) to guarantees in tail-sensitive KL and Rényi divergences. Our approach is based on one-shot couplings, which we use to establish a regularization property of the uHMC transition kernel. This regularization allows Wasserstein-2 mixing-time and asymptotic bias bounds to be lifted to KL divergence, and analogous Orlicz-Wasserstein bounds to be lifted to Rényi divergence, paralleling earlier work of Bou-Rabee and Eberle (2023) that upgrade Wasserstein-1 bounds to total variation distance via kernel smoothing. As a consequence, our results provide quantitative control of relative density mismatch, clarify the role of discretization bias in strong divergences, and yield principled guarantees relevant both for unadjusted sampling and for generating warm starts for Metropolis-adjusted Markov chains.
Fast and Furious Symmetric Learning in Zero-Sum Games: Gradient Descent as Fictitious Play
Jun 16, 2025This paper investigates the sublinear regret guarantees of two non-no-regret algorithms in zero-sum games: Fictitious Play, and Online Gradient Descent with constant stepsizes. In general adversarial online learning settings, both algorithms may exhibit instability and linear regret due to no regularization (Fictitious Play) or small amounts of regularization (Gradient Descent). However, their ability to obtain tighter regret bounds in two-player zero-sum games is less understood. In this work, we obtain strong new regret guarantees for both algorithms on a class of symmetric zero-sum games that generalize the classic three-strategy Rock-Paper-Scissors to a weighted, n-dimensional regime. Under symmetric initializations of the players' strategies, we prove that Fictitious Play with any tiebreaking rule has $O(\sqrt{T})$ regret, establishing a new class of games for which Karlin's Fictitious Play conjecture holds. Moreover, by leveraging a connection between the geometry of the iterates of Fictitious Play and Gradient Descent in the dual space of payoff vectors, we prove that Gradient Descent, for almost all symmetric initializations, obtains a similar $O(\sqrt{T})$ regret bound when its stepsize is a sufficiently large constant. For Gradient Descent, this establishes the first "fast and furious" behavior (i.e., sublinear regret without time-vanishing stepsizes) for zero-sum games larger than 2x2.
Hamiltonian Descent Algorithms for Optimization: Accelerated Rates via Randomized Integration Time
May 18, 2025We study the Hamiltonian flow for optimization (HF-opt), which simulates the Hamiltonian dynamics for some integration time and resets the velocity to $0$ to decrease the objective function; this is the optimization analogue of the Hamiltonian Monte Carlo algorithm for sampling. For short integration time, HF-opt has the same convergence rates as gradient descent for minimizing strongly and weakly convex functions. We show that by randomizing the integration time in HF-opt, the resulting randomized Hamiltonian flow (RHF) achieves accelerated convergence rates in continuous time, similar to the rates for the accelerated gradient flow. We study a discrete-time implementation of RHF as the randomized Hamiltonian gradient descent (RHGD) algorithm. We prove that RHGD achieves the same accelerated convergence rates as Nesterov's accelerated gradient descent (AGD) for minimizing smooth strongly and weakly convex functions. We provide numerical experiments to demonstrate that RHGD is competitive with classical accelerated methods such as AGD across all settings and outperforms them in certain regimes.
Mixing Time of the Proximal Sampler in Relative Fisher Information via Strong Data Processing Inequality
Feb 08, 2025We study the mixing time guarantee for sampling in relative Fisher information via the Proximal Sampler algorithm, which is an approximate proximal discretization of the Langevin dynamics. We show that when the target probability distribution is strongly log-concave, the relative Fisher information converges exponentially fast along the Proximal Sampler; this matches the exponential convergence rate of the relative Fisher information along the continuous-time Langevin dynamics for strongly log-concave target. When combined with a standard implementation of the Proximal Sampler via rejection sampling, this exponential convergence rate provides a high-accuracy iteration complexity guarantee for the Proximal Sampler in relative Fisher information when the target distribution is strongly log-concave and log-smooth. Our proof proceeds by establishing a strong data processing inequality for relative Fisher information along the Gaussian channel under strong log-concavity, and a data processing inequality along the reverse Gaussian channel for a special distribution. The forward and reverse Gaussian channels compose to form the Proximal Sampler, and these data processing inequalities imply the exponential convergence rate of the relative Fisher information along the Proximal Sampler.
Convergence of the Min-Max Langevin Dynamics and Algorithm for Zero-Sum Games
Dec 29, 2024We study zero-sum games in the space of probability distributions over the Euclidean space $\mathbb{R}^d$ with entropy regularization, in the setting when the interaction function between the players is smooth and strongly convex-concave. We prove an exponential convergence guarantee for the mean-field min-max Langevin dynamics to compute the equilibrium distribution of the zero-sum game. We also study the finite-particle approximation of the mean-field min-max Langevin dynamics, both in continuous and discrete times. We prove biased convergence guarantees for the continuous-time finite-particle min-max Langevin dynamics to the stationary mean-field equilibrium distribution with an explicit bias estimate which does not scale with the number of particles. We also prove biased convergence guarantees for the discrete-time finite-particle min-max Langevin algorithm to the stationary mean-field equilibrium distribution with an additional bias term which scales with the step size and the number of particles. This provides an explicit iteration complexity for the average particle along the finite-particle algorithm to approximately compute the equilibrium distribution of the zero-sum game.
High-accuracy sampling from constrained spaces with the Metropolis-adjusted Preconditioned Langevin Algorithm
Dec 24, 2024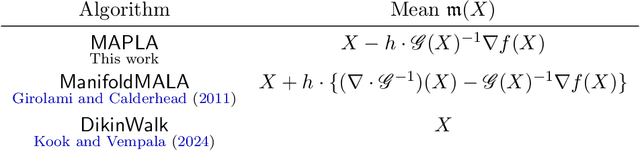
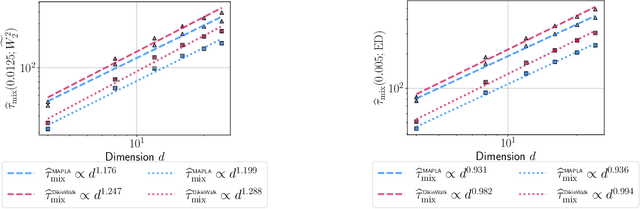

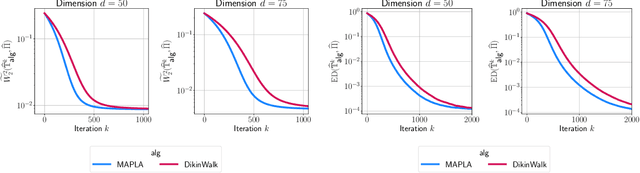
In this work, we propose a first-order sampling method called the Metropolis-adjusted Preconditioned Langevin Algorithm for approximate sampling from a target distribution whose support is a proper convex subset of $\mathbb{R}^{d}$. Our proposed method is the result of applying a Metropolis-Hastings filter to the Markov chain formed by a single step of the preconditioned Langevin algorithm with a metric $\mathscr{G}$, and is motivated by the natural gradient descent algorithm for optimisation. We derive non-asymptotic upper bounds for the mixing time of this method for sampling from target distributions whose potentials are bounded relative to $\mathscr{G}$, and for exponential distributions restricted to the support. Our analysis suggests that if $\mathscr{G}$ satisfies stronger notions of self-concordance introduced in Kook and Vempala (2024), then these mixing time upper bounds have a strictly better dependence on the dimension than when is merely self-concordant. We also provide numerical experiments that demonstrates the practicality of our proposed method. Our method is a high-accuracy sampler due to the polylogarithmic dependence on the error tolerance in our mixing time upper bounds.
Fast Convergence of $Φ$-Divergence Along the Unadjusted Langevin Algorithm and Proximal Sampler
Oct 14, 2024We study the mixing time of two popular discrete time Markov chains in continuous space, the unadjusted Langevin algorithm and the proximal sampler, which are discretizations of the Langevin dynamics. We extend mixing time analyses for these Markov chains to hold in $\Phi$-divergence. We show that any $\Phi$-divergence arising from a twice-differentiable strictly convex function $\Phi$ converges to $0$ exponentially fast along these Markov chains, under the assumption that their stationary distributions satisfies the corresponding $\Phi$-Sobolev inequality. Our rates of convergence are tight and include as special cases popular mixing time regimes, namely the mixing in chi-squared divergence under a Poincar\'e inequality, and the mixing in relative entropy under a log-Sobolev inequality. Our results follow by bounding the contraction coefficients arising in the appropriate strong data processing inequalities.