 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Online Control with Adversarial Disturbances
Jun 23, 2025Multi-agent control problems involving a large number of agents with competing and time-varying objectives are increasingly prevalent in applications across robotics, economics, and energy systems. In this paper, we study online control in multi-agent linear dynamical systems with disturbances. In contrast to most prior work in multi-agent control, we consider an online setting where disturbances are adversarial and where each agent seeks to minimize its own, adversarial sequence of convex losses. In this setting, we investigate the robustness of gradient-based controllers from single-agent online control, with a particular focus on understanding how individual regret guarantees are influenced by the number of agents in the system. Under minimal communication assumptions, we prove near-optimal sublinear regret bounds that hold uniformly for all agents. Finally, when the objectives of the agents are aligned, we show that the multi-agent control problem induces a time-varying potential game for which we derive equilibrium gap guarantees.
Fast and Furious Symmetric Learning in Zero-Sum Games: Gradient Descent as Fictitious Play
Jun 16, 2025This paper investigates the sublinear regret guarantees of two non-no-regret algorithms in zero-sum games: Fictitious Play, and Online Gradient Descent with constant stepsizes. In general adversarial online learning settings, both algorithms may exhibit instability and linear regret due to no regularization (Fictitious Play) or small amounts of regularization (Gradient Descent). However, their ability to obtain tighter regret bounds in two-player zero-sum games is less understood. In this work, we obtain strong new regret guarantees for both algorithms on a class of symmetric zero-sum games that generalize the classic three-strategy Rock-Paper-Scissors to a weighted, n-dimensional regime. Under symmetric initializations of the players' strategies, we prove that Fictitious Play with any tiebreaking rule has $O(\sqrt{T})$ regret, establishing a new class of games for which Karlin's Fictitious Play conjecture holds. Moreover, by leveraging a connection between the geometry of the iterates of Fictitious Play and Gradient Descent in the dual space of payoff vectors, we prove that Gradient Descent, for almost all symmetric initializations, obtains a similar $O(\sqrt{T})$ regret bound when its stepsize is a sufficiently large constant. For Gradient Descent, this establishes the first "fast and furious" behavior (i.e., sublinear regret without time-vanishing stepsizes) for zero-sum games larger than 2x2.
Avoiding Obfuscation with Prover-Estimator Debate
Jun 16, 2025Training powerful AI systems to exhibit desired behaviors hinges on the ability to provide accurate human supervision on increasingly complex tasks. A promising approach to this problem is to amplify human judgement by leveraging the power of two competing AIs in a debate about the correct solution to a given problem. Prior theoretical work has provided a complexity-theoretic formalization of AI debate, and posed the problem of designing protocols for AI debate that guarantee the correctness of human judgements for as complex a class of problems as possible. Recursive debates, in which debaters decompose a complex problem into simpler subproblems, hold promise for growing the class of problems that can be accurately judged in a debate. However, existing protocols for recursive debate run into the obfuscated arguments problem: a dishonest debater can use a computationally efficient strategy that forces an honest opponent to solve a computationally intractable problem to win. We mitigate this problem with a new recursive debate protocol that, under certain stability assumptions, ensures that an honest debater can win with a strategy requiring computational efficiency comparable to their opponent.
Cautious Optimism: A Meta-Algorithm for Near-Constant Regret in General Games
Jun 05, 2025Recent work [Soleymani et al., 2025] introduced a variant of Optimistic Multiplicative Weights Updates (OMWU) that adaptively controls the learning pace in a dynamic, non-monotone manner, achieving new state-of-the-art regret minimization guarantees in general games. In this work, we demonstrate that no-regret learning acceleration through adaptive pacing of the learners is not an isolated phenomenon. We introduce \emph{Cautious Optimism}, a framework for substantially faster regularized learning in general games. Cautious Optimism takes as input any instance of Follow-the-Regularized-Leader (FTRL) and outputs an accelerated no-regret learning algorithm by pacing the underlying FTRL with minimal computational overhead. Importantly, we retain uncoupledness (learners do not need to know other players' utilities). Cautious Optimistic FTRL achieves near-optimal $O_T(\log T)$ regret in diverse self-play (mixing-and-matching regularizers) while preserving the optimal $O(\sqrt{T})$ regret in adversarial scenarios. In contrast to prior works (e.g. Syrgkanis et al. [2015], Daskalakis et al. [2021]), our analysis does not rely on monotonic step-sizes, showcasing a novel route for fast learning in general games.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Faster Rates for No-Regret Learning in General Games via Cautious Optimism
Mar 31, 2025
We establish the first uncoupled learning algorithm that attains $O(n \log^2 d \log T)$ per-player regret in multi-player general-sum games, where $n$ is the number of players, $d$ is the number of actions available to each player, and $T$ is the number of repetitions of the game. Our results exponentially improve the dependence on $d$ compared to the $O(n\, d \log T)$ regret attainable by Log-Regularized Lifted Optimistic FTRL [Far+22c], and also reduce the dependence on the number of iterations $T$ from $\log^4 T$ to $\log T$ compared to Optimistic Hedge, the previously well-studied algorithm with $O(n \log d \log^4 T)$ regret [DFG21]. Our algorithm is obtained by combining the classic Optimistic Multiplicative Weights Update (OMWU) with an adaptive, non-monotonic learning rate that paces the learning process of the players, making them more cautious when their regret becomes too negative.
Re-evaluating Open-ended Evaluation of Large Language Models
Feb 27, 2025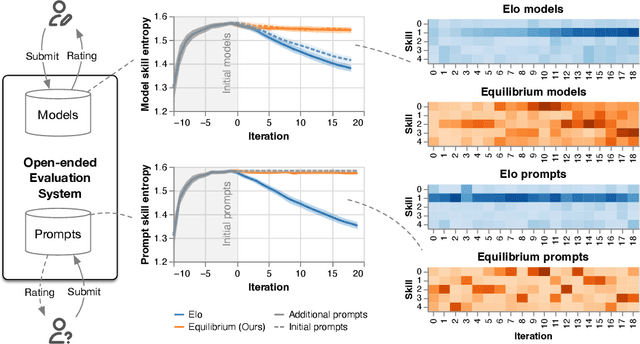

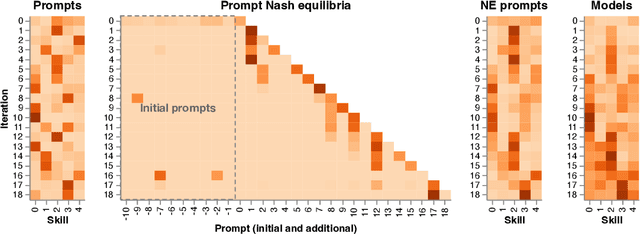
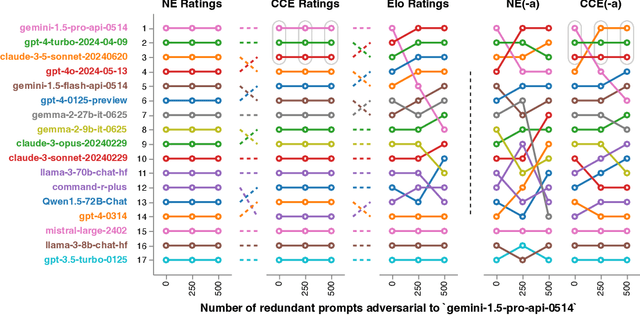
Evaluation has traditionally focused on ranking candidates for a specific skill. Modern generalist models, such as Large Language Models (LLMs), decidedly outpace this paradigm. Open-ended evaluation systems, where candidate models are compared on user-submitted prompts, have emerged as a popular solution. Despite their many advantages, we show that the current Elo-based rating systems can be susceptible to and even reinforce biases in data, intentional or accidental, due to their sensitivity to redundancies. To address this issue, we propose evaluation as a 3-player game, and introduce novel game-theoretic solution concepts to ensure robustness to redundancy. We show that our method leads to intuitive ratings and provide insights into the competitive landscape of LLM development.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Deviation Ratings: A General, Clone-Invariant Rating Method
Feb 17, 2025Many real-world multi-agent or multi-task evaluation scenarios can be naturally modelled as normal-form games due to inherent strategic (adversarial, cooperative, and mixed motive) interactions. These strategic interactions may be agentic (e.g. players trying to win), fundamental (e.g. cost vs quality), or complementary (e.g. niche finding and specialization). In such a formulation, it is the strategies (actions, policies, agents, models, tasks, prompts, etc.) that are rated. However, the rating problem is complicated by redundancy and complexity of N-player strategic interactions. Repeated or similar strategies can distort ratings for those that counter or complement them. Previous work proposed ``clone invariant'' ratings to handle such redundancies, but this was limited to two-player zero-sum (i.e. strictly competitive) interactions. This work introduces the first N-player general-sum clone invariant rating, called deviation ratings, based on coarse correlated equilibria. The rating is explored on several domains including LLMs evaluation.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.