 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
Nov 10, 2025Few classical games have been regarded as such significant benchmarks of artificial intelligence as to have justified training costs in the millions of dollars. Among these, Stratego -- a board wargame exemplifying the challenge of strategic decision making under massive amounts of hidden information -- stands apart as a case where such efforts failed to produce performance at the level of top humans. This work establishes a step change in both performance and cost for Stratego, showing that it is now possible not only to reach the level of top humans, but to achieve vastly superhuman level -- and that doing so requires not an industrial budget, but merely a few thousand dollars. We achieved this result by developing general approaches for self-play reinforcement learning and test-time search under imperfect information.
Cautious Optimism: A Meta-Algorithm for Near-Constant Regret in General Games
Jun 05, 2025Recent work [Soleymani et al., 2025] introduced a variant of Optimistic Multiplicative Weights Updates (OMWU) that adaptively controls the learning pace in a dynamic, non-monotone manner, achieving new state-of-the-art regret minimization guarantees in general games. In this work, we demonstrate that no-regret learning acceleration through adaptive pacing of the learners is not an isolated phenomenon. We introduce \emph{Cautious Optimism}, a framework for substantially faster regularized learning in general games. Cautious Optimism takes as input any instance of Follow-the-Regularized-Leader (FTRL) and outputs an accelerated no-regret learning algorithm by pacing the underlying FTRL with minimal computational overhead. Importantly, we retain uncoupledness (learners do not need to know other players' utilities). Cautious Optimistic FTRL achieves near-optimal $O_T(\log T)$ regret in diverse self-play (mixing-and-matching regularizers) while preserving the optimal $O(\sqrt{T})$ regret in adversarial scenarios. In contrast to prior works (e.g. Syrgkanis et al. [2015], Daskalakis et al. [2021]), our analysis does not rely on monotonic step-sizes, showcasing a novel route for fast learning in general games.
UFT: Unifying Supervised and Reinforcement Fine-Tuning
May 22, 2025



Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT's inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
A Polynomial-Time Algorithm for Variational Inequalities under the Minty Condition
Apr 04, 2025
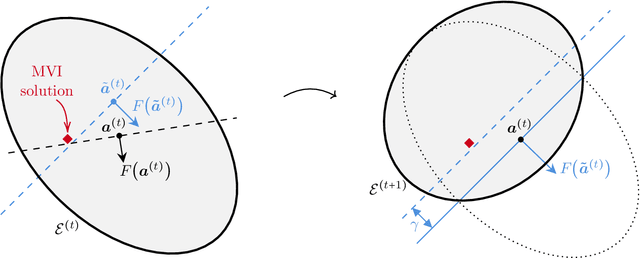


Solving (Stampacchia) variational inequalities (SVIs) is a foundational problem at the heart of optimization, with a host of critical applications ranging from engineering to economics. However, this expressivity comes at the cost of computational hardness. As a result, most research has focused on carving out specific subclasses that elude those intractability barriers. A classical property that goes back to the 1960s is the Minty condition, which postulates that the Minty VI (MVI) problem -- the weak dual of the SVI problem -- admits a solution. In this paper, we establish the first polynomial-time algorithm -- that is, with complexity growing polynomially in the dimension $d$ and $\log(1/\epsilon)$ -- for solving $\epsilon$-SVIs for Lipschitz continuous mappings under the Minty condition. Prior approaches either incurred an exponentially worse dependence on $1/\epsilon$ (and other natural parameters of the problem) or made overly restrictive assumptions -- such as strong monotonicity. To do so, we introduce a new variant of the ellipsoid algorithm wherein separating hyperplanes are obtained after taking a gradient descent step from the center of the ellipsoid. It succeeds even though the set of SVIs can be nonconvex and not fully dimensional. Moreover, when our algorithm is applied to an instance with no MVI solution and fails to identify an SVI solution, it produces a succinct certificate of MVI infeasibility. We also show that deciding whether the Minty condition holds is $\mathsf{coNP}$-complete. We provide several extensions and new applications of our main results. Specifically, we obtain the first polynomial-time algorithms for i) solving monotone VIs, ii) globally minimizing a (potentially nonsmooth) quasar-convex function, and iii) computing Nash equilibria in multi-player harmonic games.
Efficient Near-Optimal Algorithm for Online Shortest Paths in Directed Acyclic Graphs with Bandit Feedback Against Adaptive Adversaries
Apr 01, 2025In this paper, we study the online shortest path problem in directed acyclic graphs (DAGs) under bandit feedback against an adaptive adversary. Given a DAG $G = (V, E)$ with a source node $v_{\mathsf{s}}$ and a sink node $v_{\mathsf{t}}$, let $X \subseteq \{0,1\}^{|E|}$ denote the set of all paths from $v_{\mathsf{s}}$ to $v_{\mathsf{t}}$. At each round $t$, we select a path $\mathbf{x}_t \in X$ and receive bandit feedback on our loss $\langle \mathbf{x}_t, \mathbf{y}_t \rangle \in [-1,1]$, where $\mathbf{y}_t$ is an adversarially chosen loss vector. Our goal is to minimize regret with respect to the best path in hindsight over $T$ rounds. We propose the first computationally efficient algorithm to achieve a near-minimax optimal regret bound of $\tilde O(\sqrt{|E|T\log |X|})$ with high probability against any adaptive adversary, where $\tilde O(\cdot)$ hides logarithmic factors in the number of edges $|E|$. Our algorithm leverages a novel loss estimator and a centroid-based decomposition in a nontrivial manner to attain this regret bound. As an application, we show that our algorithm for DAGs provides state-of-the-art efficient algorithms for $m$-sets, extensive-form games, the Colonel Blotto game, shortest walks in directed graphs, hypercubes, and multi-task multi-armed bandits, achieving improved high-probability regret guarantees in all these settings.
Faster Rates for No-Regret Learning in General Games via Cautious Optimism
Mar 31, 2025
We establish the first uncoupled learning algorithm that attains $O(n \log^2 d \log T)$ per-player regret in multi-player general-sum games, where $n$ is the number of players, $d$ is the number of actions available to each player, and $T$ is the number of repetitions of the game. Our results exponentially improve the dependence on $d$ compared to the $O(n\, d \log T)$ regret attainable by Log-Regularized Lifted Optimistic FTRL [Far+22c], and also reduce the dependence on the number of iterations $T$ from $\log^4 T$ to $\log T$ compared to Optimistic Hedge, the previously well-studied algorithm with $O(n \log d \log^4 T)$ regret [DFG21]. Our algorithm is obtained by combining the classic Optimistic Multiplicative Weights Update (OMWU) with an adaptive, non-monotonic learning rate that paces the learning process of the players, making them more cautious when their regret becomes too negative.
Differentially Private Equilibrium Finding in Polymatrix Games
Mar 12, 2025



We study equilibrium finding in polymatrix games under differential privacy constraints. To start, we show that high accuracy and asymptotically vanishing differential privacy budget (as the number of players goes to infinity) cannot be achieved simultaneously under either of the two settings: (i) We seek to establish equilibrium approximation guarantees in terms of Euclidean distance to the equilibrium set, and (ii) the adversary has access to all communication channels. Then, assuming the adversary has access to a constant number of communication channels, we develop a novel distributed algorithm that recovers strategies with simultaneously vanishing Nash gap (in expected utility, also referred to as exploitability and privacy budget as the number of players increases.
On Separation Between Best-Iterate, Random-Iterate, and Last-Iterate Convergence of Learning in Games
Mar 04, 2025Non-ergodic convergence of learning dynamics in games is widely studied recently because of its importance in both theory and practice. Recent work (Cai et al., 2024) showed that a broad class of learning dynamics, including Optimistic Multiplicative Weights Update (OMWU), can exhibit arbitrarily slow last-iterate convergence even in simple $2 \times 2$ matrix games, despite many of these dynamics being known to converge asymptotically in the last iterate. It remains unclear, however, whether these algorithms achieve fast non-ergodic convergence under weaker criteria, such as best-iterate convergence. We show that for $2\times 2$ matrix games, OMWU achieves an $O(T^{-1/6})$ best-iterate convergence rate, in stark contrast to its slow last-iterate convergence in the same class of games. Furthermore, we establish a lower bound showing that OMWU does not achieve any polynomial random-iterate convergence rate, measured by the expected duality gaps across all iterates. This result challenges the conventional wisdom that random-iterate convergence is essentially equivalent to best-iterate convergence, with the former often used as a proxy for establishing the latter. Our analysis uncovers a new connection to dynamic regret and presents a novel two-phase approach to best-iterate convergence, which could be of independent interest.
Expected Variational Inequalities
Feb 25, 2025Variational inequalities (VIs) encompass many fundamental problems in diverse areas ranging from engineering to economics and machine learning. However, their considerable expressivity comes at the cost of computational intractability. In this paper, we introduce and analyze a natural relaxation -- which we refer to as expected variational inequalities (EVIs) -- where the goal is to find a distribution that satisfies the VI constraint in expectation. By adapting recent techniques from game theory, we show that, unlike VIs, EVIs can be solved in polynomial time under general (nonmonotone) operators. EVIs capture the seminal notion of correlated equilibria, but enjoy a greater reach beyond games. We also employ our framework to capture and generalize several existing disparate results, including from settings such as smooth games, and games with coupled constraints or nonconcave utilities.
Learning and Computation of $Φ$-Equilibria at the Frontier of Tractability
Feb 25, 2025$\Phi$-equilibria -- and the associated notion of $\Phi$-regret -- are a powerful and flexible framework at the heart of online learning and game theory, whereby enriching the set of deviations $\Phi$ begets stronger notions of rationality. Recently, Daskalakis, Farina, Fishelson, Pipis, and Schneider (STOC '24) -- abbreviated as DFFPS -- settled the existence of efficient algorithms when $\Phi$ contains only linear maps under a general, $d$-dimensional convex constraint set $\mathcal{X}$. In this paper, we significantly extend their work by resolving the case where $\Phi$ is $k$-dimensional; degree-$\ell$ polynomials constitute a canonical such example with $k = d^{O(\ell)}$. In particular, positing only oracle access to $\mathcal{X}$, we obtain two main positive results: i) a $\text{poly}(n, d, k, \text{log}(1/\epsilon))$-time algorithm for computing $\epsilon$-approximate $\Phi$-equilibria in $n$-player multilinear games, and ii) an efficient online algorithm that incurs average $\Phi$-regret at most $\epsilon$ using $\text{poly}(d, k)/\epsilon^2$ rounds. We also show nearly matching lower bounds in the online learning setting, thereby obtaining for the first time a family of deviations that captures the learnability of $\Phi$-regret. From a technical standpoint, we extend the framework of DFFPS from linear maps to the more challenging case of maps with polynomial dimension. At the heart of our approach is a polynomial-time algorithm for computing an expected fixed point of any $\phi : \mathcal{X} \to \mathcal{X}$ based on the ellipsoid against hope (EAH) algorithm of Papadimitriou and Roughgarden (JACM '08). In particular, our algorithm for computing $\Phi$-equilibria is based on executing EAH in a nested fashion -- each step of EAH itself being implemented by invoking a separate call to EAH.