 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReevaluating Policy Gradient Methods for Imperfect-Information Games
Feb 13, 2025In the past decade, motivated by the putative failure of naive self-play deep reinforcement learning (DRL) in adversarial imperfect-information games, researchers have developed numerous DRL algorithms based on fictitious play (FP), double oracle (DO), and counterfactual regret minimization (CFR). In light of recent results of the magnetic mirror descent algorithm, we hypothesize that simpler generic policy gradient methods like PPO are competitive with or superior to these FP, DO, and CFR-based DRL approaches. To facilitate the resolution of this hypothesis, we implement and release the first broadly accessible exact exploitability computations for four large games. Using these games, we conduct the largest-ever exploitability comparison of DRL algorithms for imperfect-information games. Over 5600 training runs, FP, DO, and CFR-based approaches fail to outperform generic policy gradient methods. Code is available at https://github.com/nathanlct/IIG-RL-Benchmark and https://github.com/gabrfarina/exp-a-spiel .
Decoupling regularization from the action space
Jun 10, 2024Regularized reinforcement learning (RL), particularly the entropy-regularized kind, has gained traction in optimal control and inverse RL. While standard unregularized RL methods remain unaffected by changes in the number of actions, we show that it can severely impact their regularized counterparts. This paper demonstrates the importance of decoupling the regularizer from the action space: that is, to maintain a consistent level of regularization regardless of how many actions are involved to avoid over-regularization. Whereas the problem can be avoided by introducing a task-specific temperature parameter, it is often undesirable and cannot solve the problem when action spaces are state-dependent. In the state-dependent action context, different states with varying action spaces are regularized inconsistently. We introduce two solutions: a static temperature selection approach and a dynamic counterpart, universally applicable where this problem arises. Implementing these changes improves performance on the DeepMind control suite in static and dynamic temperature regimes and a biological sequence design task.
Maximum entropy GFlowNets with soft Q-learning
Dec 21, 2023Generative Flow Networks (GFNs) have emerged as a powerful tool for sampling discrete objects from unnormalized distributions, offering a scalable alternative to Markov Chain Monte Carlo (MCMC) methods. While GFNs draw inspiration from maximum entropy reinforcement learning (RL), the connection between the two has largely been unclear and seemingly applicable only in specific cases. This paper addresses the connection by constructing an appropriate reward function, thereby establishing an exact relationship between GFNs and maximum entropy RL. This construction allows us to introduce maximum entropy GFNs, which, in contrast to GFNs with uniform backward policy, achieve the maximum entropy attainable by GFNs without constraints on the state space.
Arc travel time and path choice model estimation subsumed
Oct 25, 2022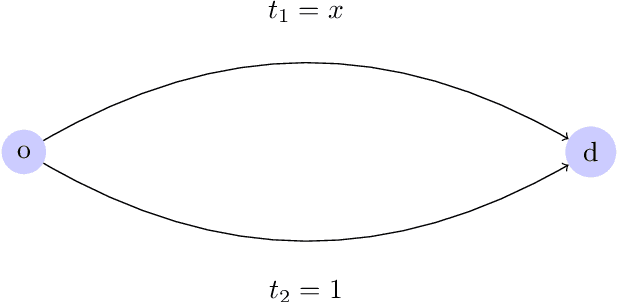
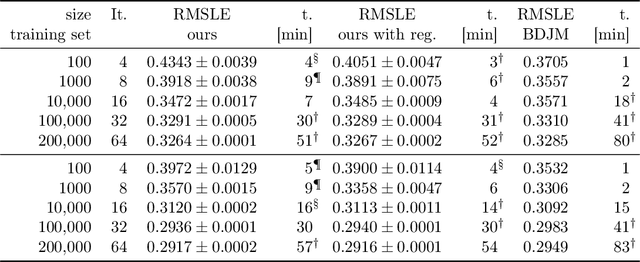
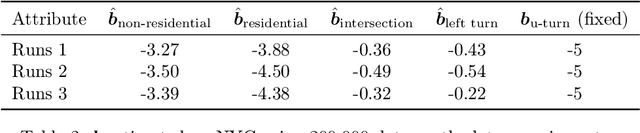
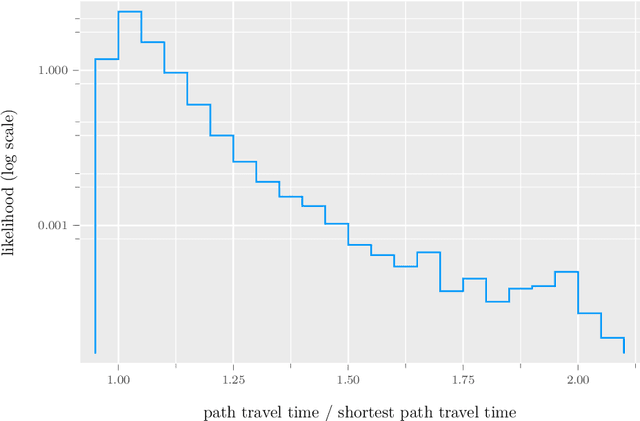
We propose a method for maximum likelihood estimation of path choice model parameters and arc travel time using data of different levels of granularity. Hitherto these two tasks have been tackled separately under strong assumptions. Using a small example, we illustrate that this can lead to biased results. Results on both real (New York yellow cab) and simulated data show strong performance of our method compared to existing baselines.