 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReevaluating Policy Gradient Methods for Imperfect-Information Games
Feb 13, 2025In the past decade, motivated by the putative failure of naive self-play deep reinforcement learning (DRL) in adversarial imperfect-information games, researchers have developed numerous DRL algorithms based on fictitious play (FP), double oracle (DO), and counterfactual regret minimization (CFR). In light of recent results of the magnetic mirror descent algorithm, we hypothesize that simpler generic policy gradient methods like PPO are competitive with or superior to these FP, DO, and CFR-based DRL approaches. To facilitate the resolution of this hypothesis, we implement and release the first broadly accessible exact exploitability computations for four large games. Using these games, we conduct the largest-ever exploitability comparison of DRL algorithms for imperfect-information games. Over 5600 training runs, FP, DO, and CFR-based approaches fail to outperform generic policy gradient methods. Code is available at https://github.com/nathanlct/IIG-RL-Benchmark and https://github.com/gabrfarina/exp-a-spiel .
RL Zero: Zero-Shot Language to Behaviors without any Supervision
Dec 07, 2024Rewards remain an uninterpretable way to specify tasks for Reinforcement Learning, as humans are often unable to predict the optimal behavior of any given reward function, leading to poor reward design and reward hacking. Language presents an appealing way to communicate intent to agents and bypass reward design, but prior efforts to do so have been limited by costly and unscalable labeling efforts. In this work, we propose a method for a completely unsupervised alternative to grounding language instructions in a zero-shot manner to obtain policies. We present a solution that takes the form of imagine, project, and imitate: The agent imagines the observation sequence corresponding to the language description of a task, projects the imagined sequence to our target domain, and grounds it to a policy. Video-language models allow us to imagine task descriptions that leverage knowledge of tasks learned from internet-scale video-text mappings. The challenge remains to ground these generations to a policy. In this work, we show that we can achieve a zero-shot language-to-behavior policy by first grounding the imagined sequences in real observations of an unsupervised RL agent and using a closed-form solution to imitation learning that allows the RL agent to mimic the grounded observations. Our method, RLZero, is the first to our knowledge to show zero-shot language to behavior generation abilities without any supervision on a variety of tasks on simulated domains. We further show that RLZero can also generate policies zero-shot from cross-embodied videos such as those scraped from YouTube.
Robot Air Hockey: A Manipulation Testbed for Robot Learning with Reinforcement Learning
May 06, 2024



Reinforcement Learning is a promising tool for learning complex policies even in fast-moving and object-interactive domains where human teleoperation or hard-coded policies might fail. To effectively reflect this challenging category of tasks, we introduce a dynamic, interactive RL testbed based on robot air hockey. By augmenting air hockey with a large family of tasks ranging from easy tasks like reaching, to challenging ones like pushing a block by hitting it with a puck, as well as goal-based and human-interactive tasks, our testbed allows a varied assessment of RL capabilities. The robot air hockey testbed also supports sim-to-real transfer with three domains: two simulators of increasing fidelity and a real robot system. Using a dataset of demonstration data gathered through two teleoperation systems: a virtualized control environment, and human shadowing, we assess the testbed with behavior cloning, offline RL, and RL from scratch.
Learning Action-based Representations Using Invariance
Mar 25, 2024Robust reinforcement learning agents using high-dimensional observations must be able to identify relevant state features amidst many exogeneous distractors. A representation that captures controllability identifies these state elements by determining what affects agent control. While methods such as inverse dynamics and mutual information capture controllability for a limited number of timesteps, capturing long-horizon elements remains a challenging problem. Myopic controllability can capture the moment right before an agent crashes into a wall, but not the control-relevance of the wall while the agent is still some distance away. To address this we introduce action-bisimulation encoding, a method inspired by the bisimulation invariance pseudometric, that extends single-step controllability with a recursive invariance constraint. By doing this, action-bisimulation learns a multi-step controllability metric that smoothly discounts distant state features that are relevant for control. We demonstrate that action-bisimulation pretraining on reward-free, uniformly random data improves sample efficiency in several environments, including a photorealistic 3D simulation domain, Habitat. Additionally, we provide theoretical analysis and qualitative results demonstrating the information captured by action-bisimulation.
Generalization of Heterogeneous Multi-Robot Policies via Awareness and Communication of Capabilities
Jan 23, 2024Recent advances in multi-agent reinforcement learning (MARL) are enabling impressive coordination in heterogeneous multi-robot teams. However, existing approaches often overlook the challenge of generalizing learned policies to teams of new compositions, sizes, and robots. While such generalization might not be important in teams of virtual agents that can retrain policies on-demand, it is pivotal in multi-robot systems that are deployed in the real-world and must readily adapt to inevitable changes. As such, multi-robot policies must remain robust to team changes -- an ability we call adaptive teaming. In this work, we investigate if awareness and communication of robot capabilities can provide such generalization by conducting detailed experiments involving an established multi-robot test bed. We demonstrate that shared decentralized policies, that enable robots to be both aware of and communicate their capabilities, can achieve adaptive teaming by implicitly capturing the fundamental relationship between collective capabilities and effective coordination. Videos of trained policies can be viewed at: https://sites.google.com/view/cap-comm
Range Limited Coverage Control using Air-Ground Multi-Robot Teams
Jun 12, 2023In this paper, we investigate how heterogeneous multi-robot systems with different sensing capabilities can observe a domain with an apriori unknown density function. Common coverage control techniques are targeted towards homogeneous teams of robots and do not consider what happens when the sensing capabilities of the robots are vastly different. This work proposes an extension to Lloyd's algorithm that fuses coverage information from heterogeneous robots with differing sensing capabilities to effectively observe a domain. Namely, we study a bimodal team of robots consisting of aerial and ground agents. In our problem formulation we use aerial robots with coarse domain sensors to approximate the number of ground robots needed within their sensing region to effectively cover it. This information is relayed to ground robots, who perform an extension to the Lloyd's algorithm that balances a locally focused coverage controller with a globally focused distribution controller. The stability of the Lloyd's algorithm extension is proven and its performance is evaluated through simulation and experiments using the Robotarium, a remotely-accessible, multi-robot testbed.
Rethinking Sim2Real: Lower Fidelity Simulation Leads to Higher Sim2Real Transfer in Navigation
Jul 21, 2022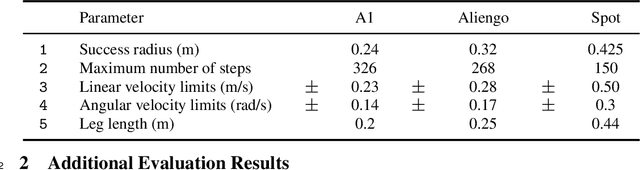
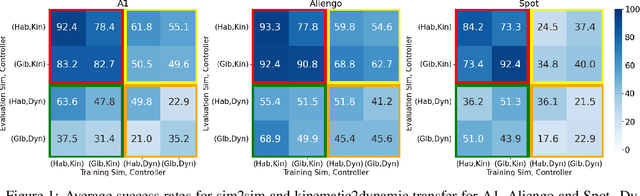


If we want to train robots in simulation before deploying them in reality, it seems natural and almost self-evident to presume that reducing the sim2real gap involves creating simulators of increasing fidelity (since reality is what it is). We challenge this assumption and present a contrary hypothesis -- sim2real transfer of robots may be improved with lower (not higher) fidelity simulation. We conduct a systematic large-scale evaluation of this hypothesis on the problem of visual navigation -- in the real world, and on 2 different simulators (Habitat and iGibson) using 3 different robots (A1, AlienGo, Spot). Our results show that, contrary to expectation, adding fidelity does not help with learning; performance is poor due to slow simulation speed (preventing large-scale learning) and overfitting to inaccuracies in simulation physics. Instead, building simple models of the robot motion using real-world data can improve learning and generalization.
Desperate Times Call for Desperate Measures: Towards Risk-Adaptive Task Allocation
Aug 07, 2021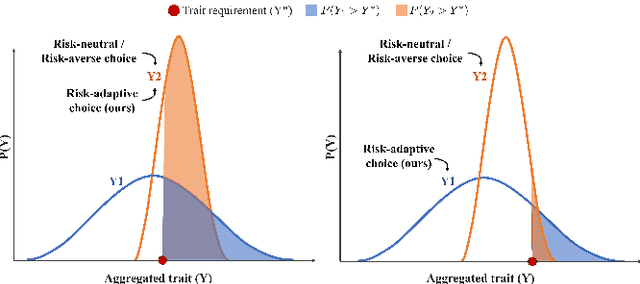
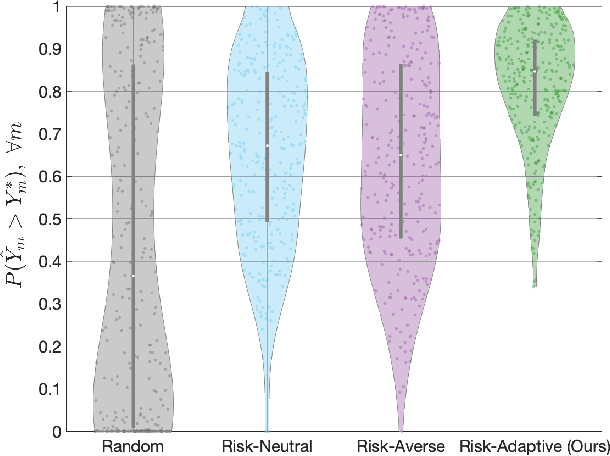
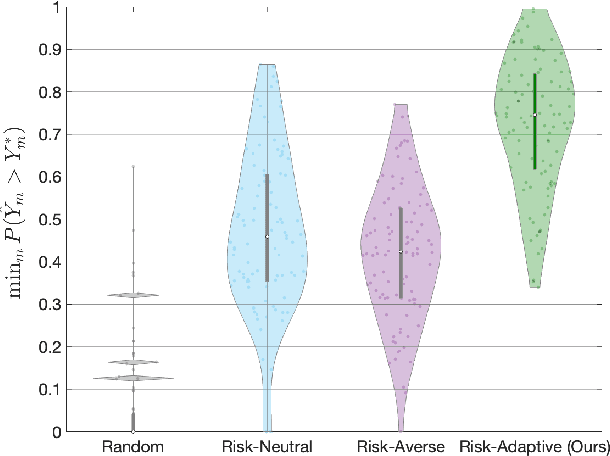
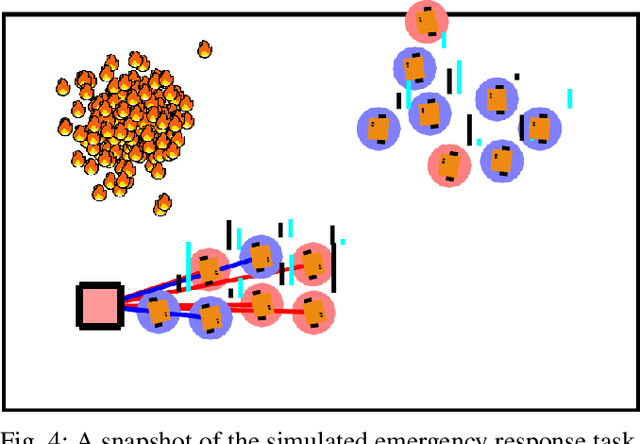
Multi-robot task allocation (MRTA) problems involve optimizing the allocation of robots to tasks. MRTA problems are known to be challenging when tasks require multiple robots and the team is composed of heterogeneous robots. These challenges are further exacerbated when we need to account for uncertainties encountered in the real-world. In this work, we address coalition formation in heterogeneous multi-robot teams with uncertain capabilities. We specifically focus on tasks that require coalitions to collectively satisfy certain minimum requirements. Existing approaches to uncertainty-aware task allocation either maximize expected pay-off (risk-neutral approaches) or improve worst-case or near-worst-case outcomes (risk-averse approaches). Within the context of our problem, we demonstrate the inherent limitations of unilaterally ignoring or avoiding risk and show that these approaches can in fact reduce the probability of satisfying task requirements. Inspired by models that explain foraging behaviors in animals, we develop a risk-adaptive approach to task allocation. Our approach adaptively switches between risk-averse and risk-seeking behavior in order to maximize the probability of satisfying task requirements. Comprehensive numerical experiments conclusively demonstrate that our risk-adaptive approach outperforms risk-neutral and risk-averse approaches. We also demonstrate the effectiveness of our approach using a simulated multi-robot emergency response scenario.