 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNull Counterfactual Factor Interactions for Goal-Conditioned Reinforcement Learning
May 06, 2025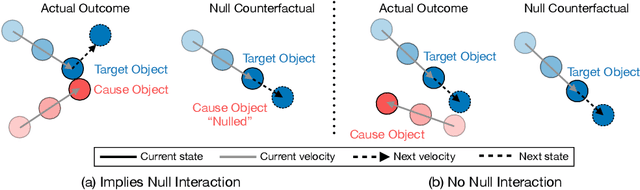
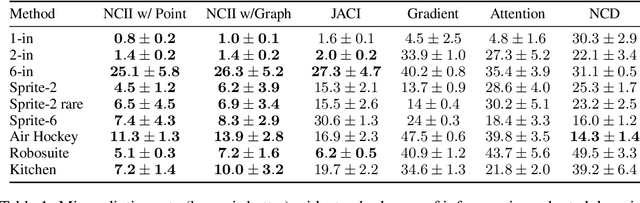

Hindsight relabeling is a powerful tool for overcoming sparsity in goal-conditioned reinforcement learning (GCRL), especially in certain domains such as navigation and locomotion. However, hindsight relabeling can struggle in object-centric domains. For example, suppose that the goal space consists of a robotic arm pushing a particular target block to a goal location. In this case, hindsight relabeling will give high rewards to any trajectory that does not interact with the block. However, these behaviors are only useful when the object is already at the goal -- an extremely rare case in practice. A dataset dominated by these kinds of trajectories can complicate learning and lead to failures. In object-centric domains, one key intuition is that meaningful trajectories are often characterized by object-object interactions such as pushing the block with the gripper. To leverage this intuition, we introduce Hindsight Relabeling using Interactions (HInt), which combines interactions with hindsight relabeling to improve the sample efficiency of downstream RL. However because interactions do not have a consensus statistical definition tractable for downstream GCRL, we propose a definition of interactions based on the concept of null counterfactual: a cause object is interacting with a target object if, in a world where the cause object did not exist, the target object would have different transition dynamics. We leverage this definition to infer interactions in Null Counterfactual Interaction Inference (NCII), which uses a "nulling'' operation with a learned model to infer interactions. NCII is able to achieve significantly improved interaction inference accuracy in both simple linear dynamics domains and dynamic robotic domains in Robosuite, Robot Air Hockey, and Franka Kitchen and HInt improves sample efficiency by up to 4x.
* Published at ICLR 2025
RL Zero: Zero-Shot Language to Behaviors without any Supervision
Dec 07, 2024Rewards remain an uninterpretable way to specify tasks for Reinforcement Learning, as humans are often unable to predict the optimal behavior of any given reward function, leading to poor reward design and reward hacking. Language presents an appealing way to communicate intent to agents and bypass reward design, but prior efforts to do so have been limited by costly and unscalable labeling efforts. In this work, we propose a method for a completely unsupervised alternative to grounding language instructions in a zero-shot manner to obtain policies. We present a solution that takes the form of imagine, project, and imitate: The agent imagines the observation sequence corresponding to the language description of a task, projects the imagined sequence to our target domain, and grounds it to a policy. Video-language models allow us to imagine task descriptions that leverage knowledge of tasks learned from internet-scale video-text mappings. The challenge remains to ground these generations to a policy. In this work, we show that we can achieve a zero-shot language-to-behavior policy by first grounding the imagined sequences in real observations of an unsupervised RL agent and using a closed-form solution to imitation learning that allows the RL agent to mimic the grounded observations. Our method, RLZero, is the first to our knowledge to show zero-shot language to behavior generation abilities without any supervision on a variety of tasks on simulated domains. We further show that RLZero can also generate policies zero-shot from cross-embodied videos such as those scraped from YouTube.
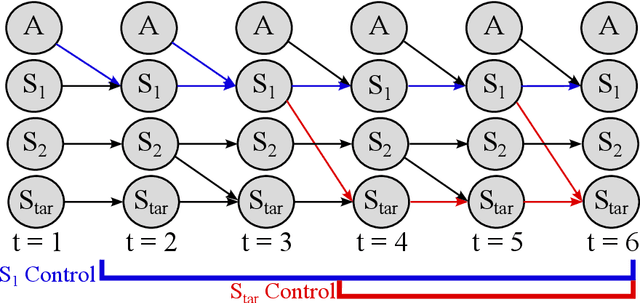
SkiLD: Unsupervised Skill Discovery Guided by Factor Interactions
Oct 24, 2024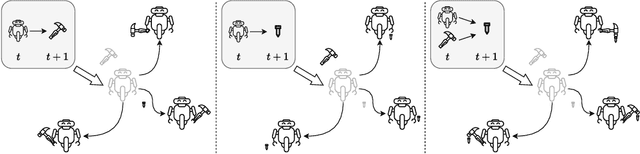
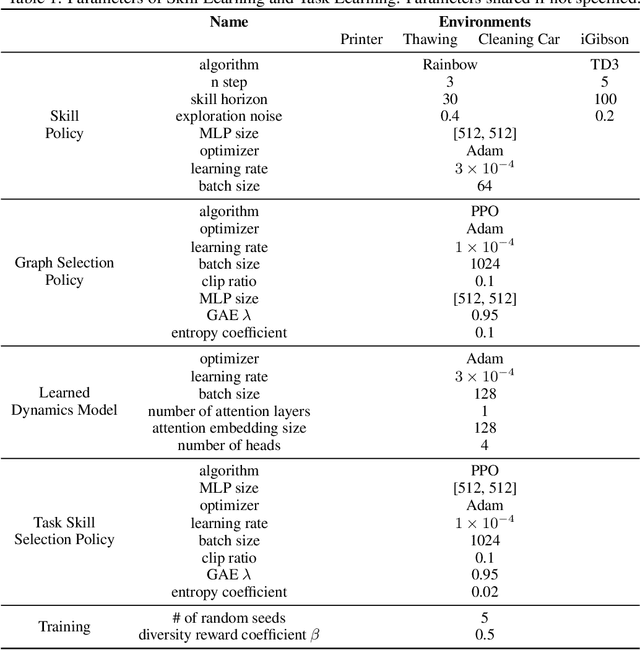
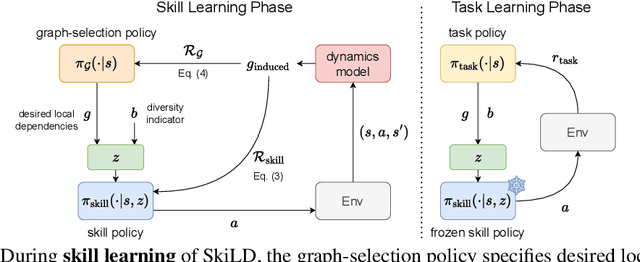
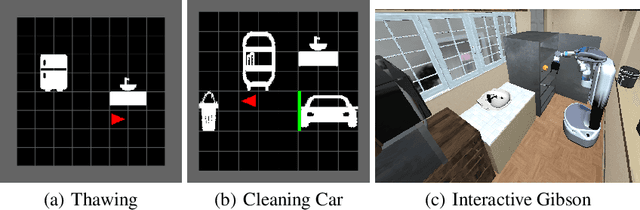
Unsupervised skill discovery carries the promise that an intelligent agent can learn reusable skills through autonomous, reward-free environment interaction. Existing unsupervised skill discovery methods learn skills by encouraging distinguishable behaviors that cover diverse states. However, in complex environments with many state factors (e.g., household environments with many objects), learning skills that cover all possible states is impossible, and naively encouraging state diversity often leads to simple skills that are not ideal for solving downstream tasks. This work introduces Skill Discovery from Local Dependencies (Skild), which leverages state factorization as a natural inductive bias to guide the skill learning process. The key intuition guiding Skild is that skills that induce <b>diverse interactions</b> between state factors are often more valuable for solving downstream tasks. To this end, Skild develops a novel skill learning objective that explicitly encourages the mastering of skills that effectively induce different interactions within an environment. We evaluate Skild in several domains with challenging, long-horizon sparse reward tasks including a realistic simulated household robot domain, where Skild successfully learns skills with clear semantic meaning and shows superior performance compared to existing unsupervised reinforcement learning methods that only maximize state coverage.
A Dual Approach to Imitation Learning from Observations with Offline Datasets
Jun 13, 2024



Demonstrations are an effective alternative to task specification for learning agents in settings where designing a reward function is difficult. However, demonstrating expert behavior in the action space of the agent becomes unwieldy when robots have complex, unintuitive morphologies. We consider the practical setting where an agent has a dataset of prior interactions with the environment and is provided with observation-only expert demonstrations. Typical learning from observations approaches have required either learning an inverse dynamics model or a discriminator as intermediate steps of training. Errors in these intermediate one-step models compound during downstream policy learning or deployment. We overcome these limitations by directly learning a multi-step utility function that quantifies how each action impacts the agent's divergence from the expert's visitation distribution. Using the principle of duality, we derive DILO(Dual Imitation Learning from Observations), an algorithm that can leverage arbitrary suboptimal data to learn imitating policies without requiring expert actions. DILO reduces the learning from observations problem to that of simply learning an actor and a critic, bearing similar complexity to vanilla offline RL. This allows DILO to gracefully scale to high dimensional observations, and demonstrate improved performance across the board. Project page (code and videos): $\href{https://hari-sikchi.github.io/dilo/}{\text{hari-sikchi.github.io/dilo/}}$
Robot Air Hockey: A Manipulation Testbed for Robot Learning with Reinforcement Learning
May 06, 2024



Reinforcement Learning is a promising tool for learning complex policies even in fast-moving and object-interactive domains where human teleoperation or hard-coded policies might fail. To effectively reflect this challenging category of tasks, we introduce a dynamic, interactive RL testbed based on robot air hockey. By augmenting air hockey with a large family of tasks ranging from easy tasks like reaching, to challenging ones like pushing a block by hitting it with a puck, as well as goal-based and human-interactive tasks, our testbed allows a varied assessment of RL capabilities. The robot air hockey testbed also supports sim-to-real transfer with three domains: two simulators of increasing fidelity and a real robot system. Using a dataset of demonstration data gathered through two teleoperation systems: a virtualized control environment, and human shadowing, we assess the testbed with behavior cloning, offline RL, and RL from scratch.
Automated Discovery of Functional Actual Causes in Complex Environments
Apr 16, 2024



Reinforcement learning (RL) algorithms often struggle to learn policies that generalize to novel situations due to issues such as causal confusion, overfitting to irrelevant factors, and failure to isolate control of state factors. These issues stem from a common source: a failure to accurately identify and exploit state-specific causal relationships in the environment. While some prior works in RL aim to identify these relationships explicitly, they rely on informal domain-specific heuristics such as spatial and temporal proximity. Actual causality offers a principled and general framework for determining the causes of particular events. However, existing definitions of actual cause often attribute causality to a large number of events, even if many of them rarely influence the outcome. Prior work on actual causality proposes normality as a solution to this problem, but its existing implementations are challenging to scale to complex and continuous-valued RL environments. This paper introduces functional actual cause (FAC), a framework that uses context-specific independencies in the environment to restrict the set of actual causes. We additionally introduce Joint Optimization for Actual Cause Inference (JACI), an algorithm that learns from observational data to infer functional actual causes. We demonstrate empirically that FAC agrees with known results on a suite of examples from the actual causality literature, and JACI identifies actual causes with significantly higher accuracy than existing heuristic methods in a set of complex, continuous-valued environments.
Learning Action-based Representations Using Invariance
Mar 25, 2024Robust reinforcement learning agents using high-dimensional observations must be able to identify relevant state features amidst many exogeneous distractors. A representation that captures controllability identifies these state elements by determining what affects agent control. While methods such as inverse dynamics and mutual information capture controllability for a limited number of timesteps, capturing long-horizon elements remains a challenging problem. Myopic controllability can capture the moment right before an agent crashes into a wall, but not the control-relevance of the wall while the agent is still some distance away. To address this we introduce action-bisimulation encoding, a method inspired by the bisimulation invariance pseudometric, that extends single-step controllability with a recursive invariance constraint. By doing this, action-bisimulation learns a multi-step controllability metric that smoothly discounts distant state features that are relevant for control. We demonstrate that action-bisimulation pretraining on reward-free, uniformly random data improves sample efficiency in several environments, including a photorealistic 3D simulation domain, Habitat. Additionally, we provide theoretical analysis and qualitative results demonstrating the information captured by action-bisimulation.
Granger-Causal Hierarchical Skill Discovery
Jun 15, 2023



Reinforcement Learning (RL) has shown promising results learning policies for complex tasks, but can often suffer from low sample efficiency and limited transfer. We introduce the Hierarchy of Interaction Skills (HIntS) algorithm, which uses learned interaction detectors to discover and train a hierarchy of skills that manipulate factors in factored environments. Inspired by Granger causality, these unsupervised detectors capture key events between factors to sample efficiently learn useful skills and transfer those skills to other related tasks -- tasks where many reinforcement learning techniques struggle. We evaluate HIntS on a robotic pushing task with obstacles -- a challenging domain where other RL and HRL methods fall short. The learned skills not only demonstrate transfer using variants of Breakout, a common RL benchmark, but also show 2-3x improvement in both sample efficiency and final performance compared to comparable RL baselines. Together, HIntS demonstrates a proof of concept for using Granger-causal relationships for skill discovery.
Hypothesis-Driven Skill Discovery for Hierarchical Deep Reinforcement Learning
May 27, 2019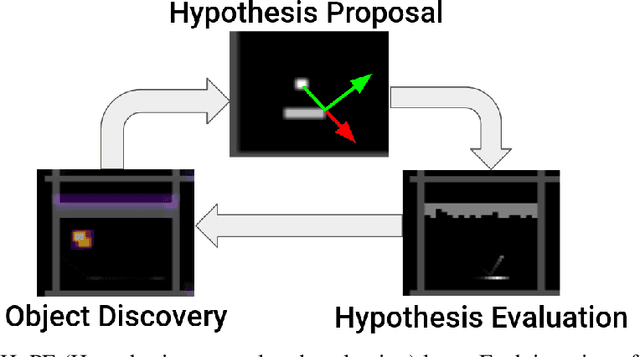


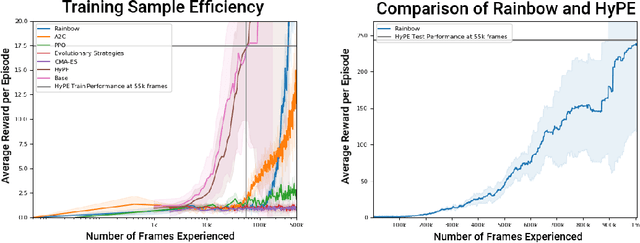
Deep reinforcement learning encompasses many versatile tools for designing learning agents that can perform well on a variety of high-dimensional visual tasks, ranging from video games to robotic manipulation. However, these methods typically suffer from poor sample efficiency, partially because they strive to be largely problem-agnostic. In this work, we demonstrate the utility of a different approach that is extremely sample efficient, but limited to object-centric tasks that (approximately) obey basic physical laws. Specifically, we propose the Hypothesis Proposal and Evaluation (HyPE) algorithm, which utilizes a small set of intuitive assumptions about the behavior of objects in the physical world (or in games that mimic physics) to automatically define and learn hierarchical skills in a highly efficient manner. HyPE does this by discovering objects from raw pixel data, generating hypotheses about the controllability of observed changes in object state, and learning a hierarchy of skills that can test these hypotheses and control increasingly complex interactions with objects. We demonstrate that HyPE can dramatically improve sample efficiency when learning a high-quality pixels-to-actions policy; in the popular benchmark task, Breakout, HyPE learns an order of magnitude faster than common baseline reinforcement learning and evolutionary strategies for policy learning.
Comparing Human-Centric and Robot-Centric Sampling for Robot Deep Learning from Demonstrations
Mar 29, 2017
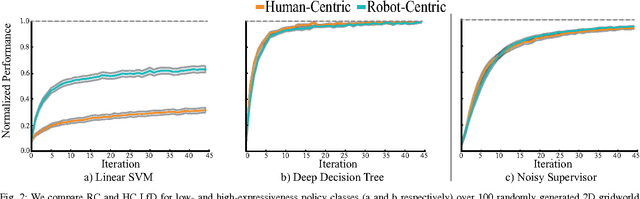
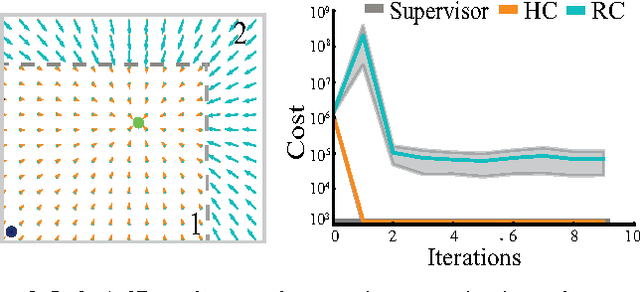
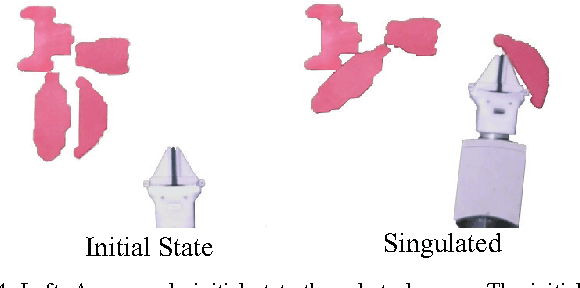
Motivated by recent advances in Deep Learning for robot control, this paper considers two learning algorithms in terms of how they acquire demonstrations. "Human-Centric" (HC) sampling is the standard supervised learning algorithm, where a human supervisor demonstrates the task by teleoperating the robot to provide trajectories consisting of state-control pairs. "Robot-Centric" (RC) sampling is an increasingly popular alternative used in algorithms such as DAgger, where a human supervisor observes the robot executing a learned policy and provides corrective control labels for each state visited. RC sampling can be challenging for human supervisors and prone to mislabeling. RC sampling can also induce error in policy performance because it repeatedly visits areas of the state space that are harder to learn. Although policies learned with RC sampling can be superior to HC sampling for standard learning models such as linear SVMs, policies learned with HC sampling may be comparable with highly-expressive learning models such as deep learning and hyper-parametric decision trees, which have little model error. We compare HC and RC using a grid world and a physical robot singulation task, where in the latter the input is a binary image of a connected set of objects on a planar worksurface and the policy generates a motion of the gripper to separate one object from the rest. We observe in simulation that for linear SVMs, policies learned with RC outperformed those learned with HC but that with deep models this advantage disappears. We also find that with RC, the corrective control labels provided by humans can be highly inconsistent. We prove there exists a class of examples where in the limit, HC is guaranteed to converge to an optimal policy while RC may fail to converge.