 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Markov Policies to Reduce Sequential Failures in Robot Bin Picking
Jul 20, 2020



A new generation of automated bin picking systems using deep learning is evolving to support increasing demand for e-commerce. To accommodate a wide variety of products, many automated systems include multiple gripper types and/or tool changers. However, for some objects, sequential grasp failures are common: when a computed grasp fails to lift and remove the object, the bin is often left unchanged; as the sensor input is consistent, the system retries the same grasp over and over, resulting in a significant reduction in mean successful picks per hour (MPPH). Based on an empirical study of sequential failures, we characterize a class of "sequential failure objects" (SFOs) -- objects prone to sequential failures based on a novel taxonomy. We then propose three non-Markov picking policies that incorporate memory of past failures to modify subsequent actions. Simulation experiments on SFO models and the EGAD dataset suggest that the non-Markov policies significantly outperform the Markov policy in terms of the sequential failure rate and MPPH. In physical experiments on 50 heaps of 12 SFOs the most effective Non-Markov policy increased MPPH over the Dex-Net Markov policy by 107%.
Minimal Work: A Grasp Quality Metric for Deformable Hollow Objects
Sep 24, 2019

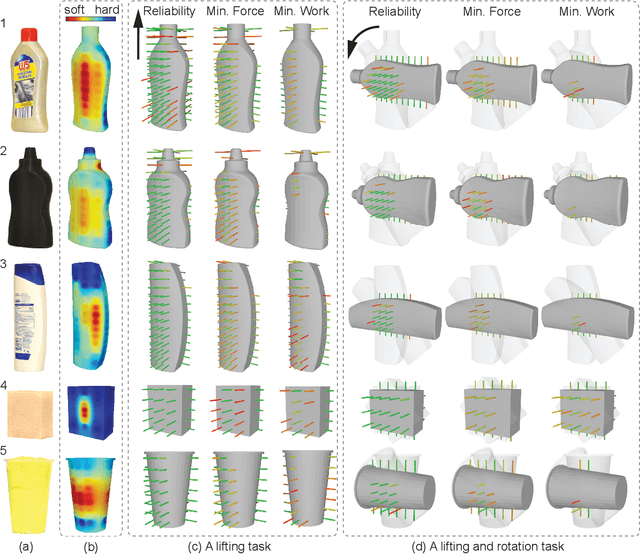
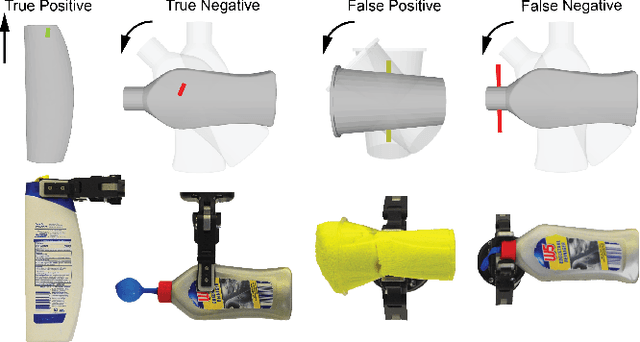
Robot grasping of deformable hollow objects such as plastic bottles and cups is challenging as the grasp should resist disturbances while minimally deforming the object so as not to damage it or dislodge liquids. We propose minimal work as a novel grasp quality metric that combines wrench resistance and the object deformation. We introduce an efficient algorithm to compute required work to resist an external wrench for a manipulation task by solving a linear program. The algorithm first computes the minimum required grasp force and an estimation of the gripper jaw displacements based on the object deformability at different locations measured with physical experiments. The work done by the jaws is the product of the grasp force and the displacements. The grasp quality metric is computed based on the required work under perturbations of grasp poses to address uncertainties in actuation. We collect 460 physical grasps with a UR5 robot and a Robotiq gripper. Physical experiments suggest the minimal work quality metric reaches 74.2% balanced accuracy and is up to 24.2% higher than classical wrench-based quality metrics, where the balanced accuracy is the raw accuracy normalized by the number of successful and failed real-world grasps.
Segmenting Unknown 3D Objects from Real Depth Images using Mask R-CNN Trained on Synthetic Data
Mar 03, 2019



The ability to segment unknown objects in depth images has potential to enhance robot skills in grasping and object tracking. Recent computer vision research has demonstrated that Mask R-CNN can be trained to segment specific categories of objects in RGB images when massive hand-labeled datasets are available. As generating these datasets is time consuming, we instead train with synthetic depth images. Many robots now use depth sensors, and recent results suggest training on synthetic depth data can transfer successfully to the real world. We present a method for automated dataset generation and rapidly generate a synthetic training dataset of 50,000 depth images and 320,000 object masks using simulated heaps of 3D CAD models. We train a variant of Mask R-CNN with domain randomization on the generated dataset to perform category-agnostic instance segmentation without any hand-labeled data and we evaluate the trained network, which we refer to as Synthetic Depth (SD) Mask R-CNN, on a set of real, high-resolution depth images of challenging, densely-cluttered bins containing objects with highly-varied geometry. SD Mask R-CNN outperforms point cloud clustering baselines by an absolute 15% in Average Precision and 20% in Average Recall on COCO benchmarks, and achieves performance levels similar to a Mask R-CNN trained on a massive, hand-labeled RGB dataset and fine-tuned on real images from the experimental setup. We deploy the model in an instance-specific grasping pipeline to demonstrate its usefulness in a robotics application. Code, the synthetic training dataset, and supplementary material are available at https://bit.ly/2letCuE.
Dex-Net 3.0: Computing Robust Robot Vacuum Suction Grasp Targets in Point Clouds using a New Analytic Model and Deep Learning
Apr 13, 2018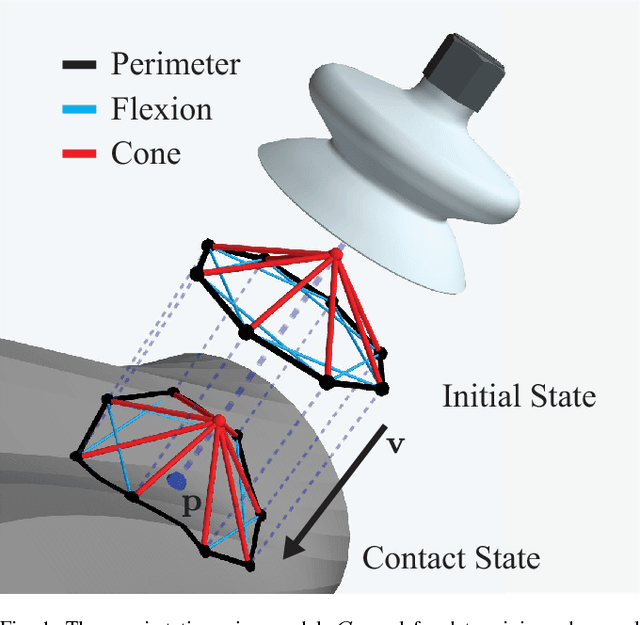
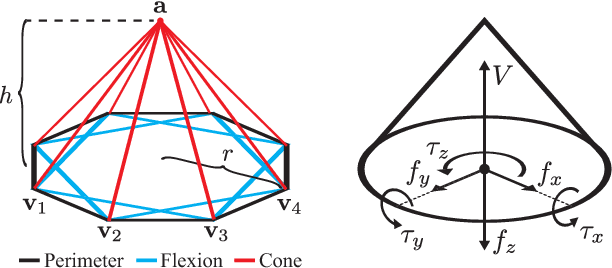
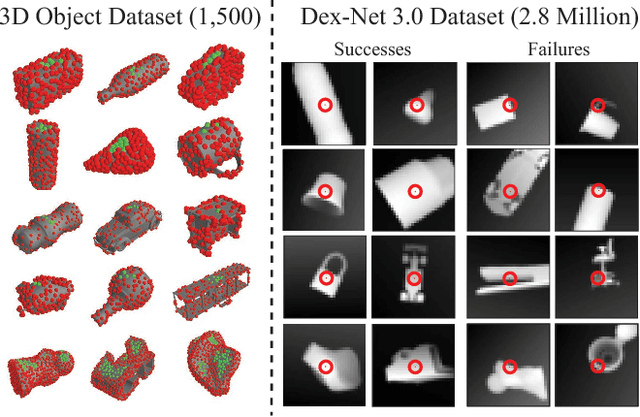

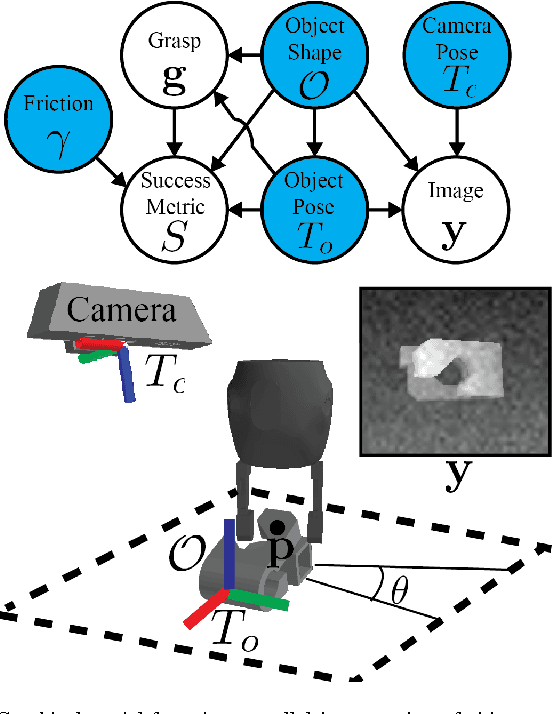
Vacuum-based end effectors are widely used in industry and are often preferred over parallel-jaw and multifinger grippers due to their ability to lift objects with a single point of contact. Suction grasp planners often target planar surfaces on point clouds near the estimated centroid of an object. In this paper, we propose a compliant suction contact model that computes the quality of the seal between the suction cup and local target surface and a measure of the ability of the suction grasp to resist an external gravity wrench. To characterize grasps, we estimate robustness to perturbations in end-effector and object pose, material properties, and external wrenches. We analyze grasps across 1,500 3D object models to generate Dex-Net 3.0, a dataset of 2.8 million point clouds, suction grasps, and grasp robustness labels. We use Dex-Net 3.0 to train a Grasp Quality Convolutional Neural Network (GQ-CNN) to classify robust suction targets in point clouds containing a single object. We evaluate the resulting system in 350 physical trials on an ABB YuMi fitted with a pneumatic suction gripper. When evaluated on novel objects that we categorize as Basic (prismatic or cylindrical), Typical (more complex geometry), and Adversarial (with few available suction-grasp points) Dex-Net 3.0 achieves success rates of 98$\%$, 82$\%$, and 58$\%$ respectively, improving to 81$\%$ in the latter case when the training set includes only adversarial objects. Code, datasets, and supplemental material can be found at http://berkeleyautomation.github.io/dex-net .
Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics
Aug 08, 2017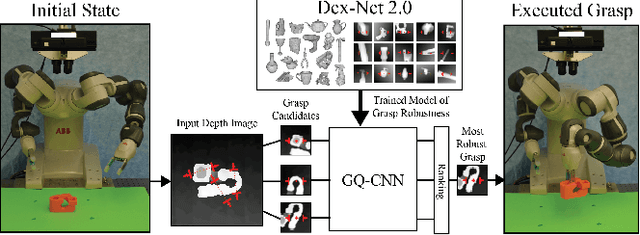
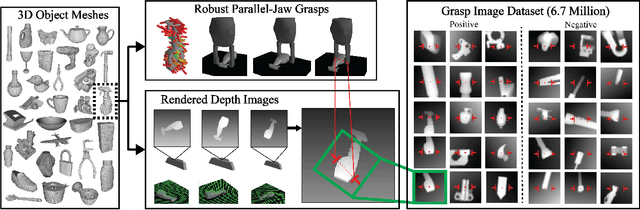
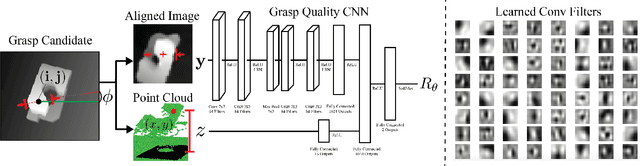
To reduce data collection time for deep learning of robust robotic grasp plans, we explore training from a synthetic dataset of 6.7 million point clouds, grasps, and analytic grasp metrics generated from thousands of 3D models from Dex-Net 1.0 in randomized poses on a table. We use the resulting dataset, Dex-Net 2.0, to train a Grasp Quality Convolutional Neural Network (GQ-CNN) model that rapidly predicts the probability of success of grasps from depth images, where grasps are specified as the planar position, angle, and depth of a gripper relative to an RGB-D sensor. Experiments with over 1,000 trials on an ABB YuMi comparing grasp planning methods on singulated objects suggest that a GQ-CNN trained with only synthetic data from Dex-Net 2.0 can be used to plan grasps in 0.8sec with a success rate of 93% on eight known objects with adversarial geometry and is 3x faster than registering point clouds to a precomputed dataset of objects and indexing grasps. The Dex-Net 2.0 grasp planner also has the highest success rate on a dataset of 10 novel rigid objects and achieves 99% precision (one false positive out of 69 grasps classified as robust) on a dataset of 40 novel household objects, some of which are articulated or deformable. Code, datasets, videos, and supplementary material are available at http://berkeleyautomation.github.io/dex-net .
Comparing Human-Centric and Robot-Centric Sampling for Robot Deep Learning from Demonstrations
Mar 29, 2017
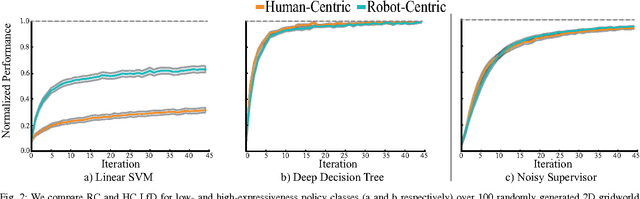
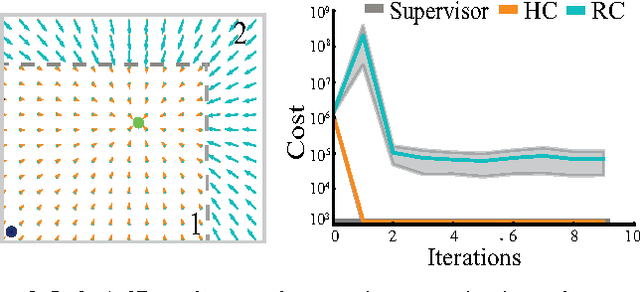
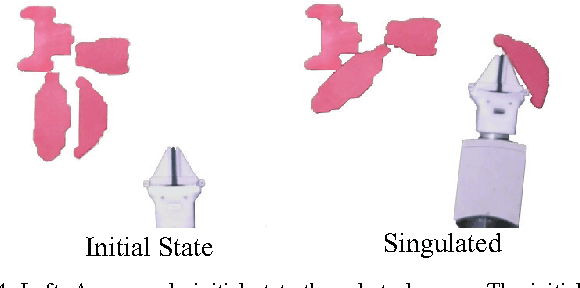
Motivated by recent advances in Deep Learning for robot control, this paper considers two learning algorithms in terms of how they acquire demonstrations. "Human-Centric" (HC) sampling is the standard supervised learning algorithm, where a human supervisor demonstrates the task by teleoperating the robot to provide trajectories consisting of state-control pairs. "Robot-Centric" (RC) sampling is an increasingly popular alternative used in algorithms such as DAgger, where a human supervisor observes the robot executing a learned policy and provides corrective control labels for each state visited. RC sampling can be challenging for human supervisors and prone to mislabeling. RC sampling can also induce error in policy performance because it repeatedly visits areas of the state space that are harder to learn. Although policies learned with RC sampling can be superior to HC sampling for standard learning models such as linear SVMs, policies learned with HC sampling may be comparable with highly-expressive learning models such as deep learning and hyper-parametric decision trees, which have little model error. We compare HC and RC using a grid world and a physical robot singulation task, where in the latter the input is a binary image of a connected set of objects on a planar worksurface and the policy generates a motion of the gripper to separate one object from the rest. We observe in simulation that for linear SVMs, policies learned with RC outperformed those learned with HC but that with deep models this advantage disappears. We also find that with RC, the corrective control labels provided by humans can be highly inconsistent. We prove there exists a class of examples where in the limit, HC is guaranteed to converge to an optimal policy while RC may fail to converge.