 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Data Minimization for Machine Learning over Internet-of-Things Data Streams
Mar 07, 2025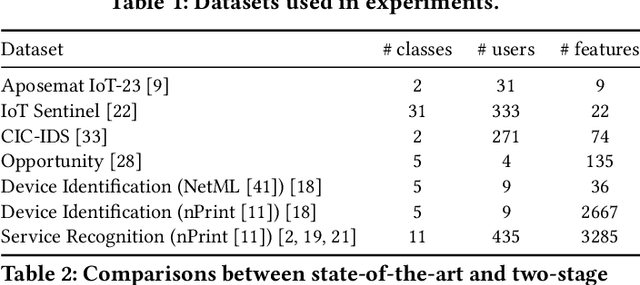
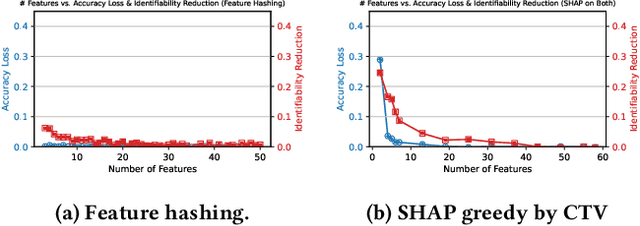
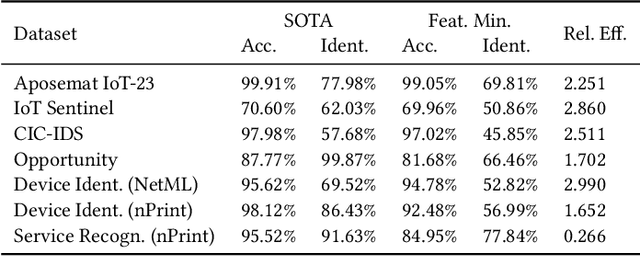
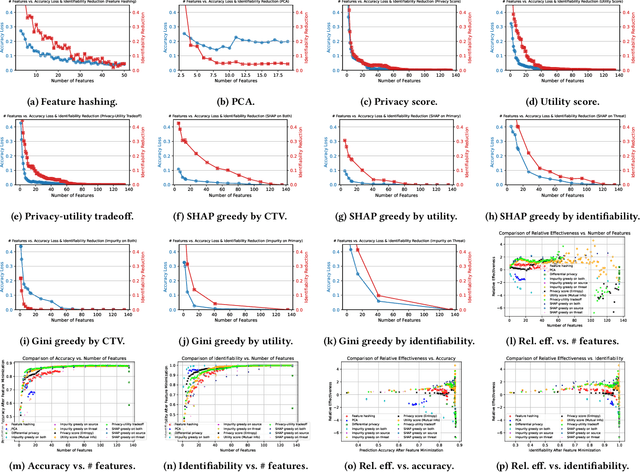
Machine learning can analyze vast amounts of data generated by IoT devices to identify patterns, make predictions, and enable real-time decision-making. By processing sensor data, machine learning models can optimize processes, improve efficiency, and enhance personalized user experiences in smart systems. However, IoT systems are often deployed in sensitive environments such as households and offices, where they may inadvertently expose identifiable information, including location, habits, and personal identifiers. This raises significant privacy concerns, necessitating the application of data minimization -- a foundational principle in emerging data regulations, which mandates that service providers only collect data that is directly relevant and necessary for a specified purpose. Despite its importance, data minimization lacks a precise technical definition in the context of sensor data, where collections of weak signals make it challenging to apply a binary "relevant and necessary" rule. This paper provides a technical interpretation of data minimization in the context of sensor streams, explores practical methods for implementation, and addresses the challenges involved. Through our approach, we demonstrate that our framework can reduce user identifiability by up to 16.7% while maintaining accuracy loss below 1%, offering a viable path toward privacy-preserving IoT data processing.
A Simple and Fast Way to Handle Semantic Errors in Transactions
Dec 17, 2024
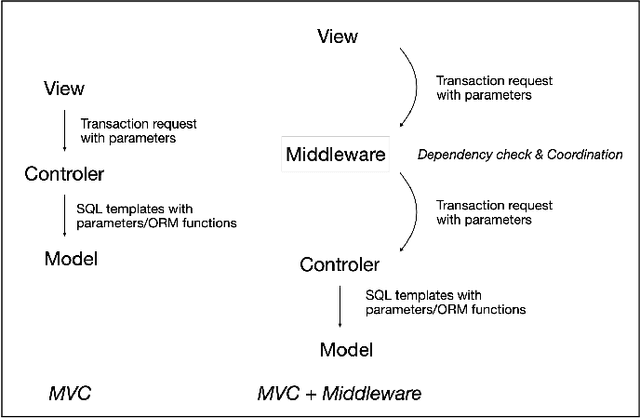

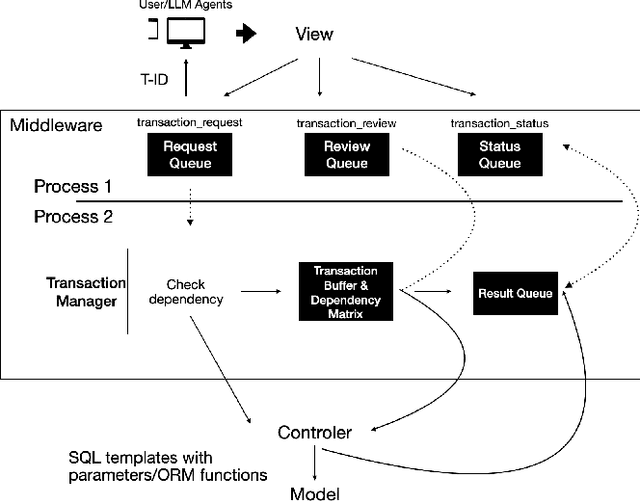
Many computer systems are now being redesigned to incorporate LLM-powered agents, enabling natural language input and more flexible operations. This paper focuses on handling database transactions created by large language models (LLMs). Transactions generated by LLMs may include semantic errors, requiring systems to treat them as long-lived. This allows for human review and, if the transaction is incorrect, removal from the database history. Any removal action must ensure the database's consistency (the "C" in ACID principles) is maintained throughout the process. We propose a novel middleware framework based on Invariant Satisfaction (I-Confluence), which ensures consistency by identifying and coordinating dependencies between long-lived transactions and new transactions. This middleware buffers suspicious or compensating transactions to manage coordination states. Using the TPC-C benchmark, we evaluate how transaction generation frequency, user reviews, and invariant completeness impact system performance. For system researchers, this study establishes an interactive paradigm between LLMs and database systems, providing an "undoing" mechanism for handling incorrect operations while guaranteeing database consistency. For system engineers, this paper offers a middleware design that integrates removable LLM-generated transactions into existing systems with minimal modifications.
Towards Causal Physical Error Discovery in Video Analytics Systems
May 27, 2024Video analytics systems based on deep learning models are often opaque and brittle and require explanation systems to help users debug. Current model explanation system are very good at giving literal explanations of behavior in terms of pixel contributions but cannot integrate information about the physical or systems processes that might influence a prediction. This paper introduces the idea that a simple form of causal reasoning, called a regression discontinuity design, can be used to associate changes in multiple key performance indicators to physical real world phenomena to give users a more actionable set of video analytics explanations. We overview the system architecture and describe a vision of the impact that such a system might have.
ServeFlow: A Fast-Slow Model Architecture for Network Traffic Analysis
Feb 06, 2024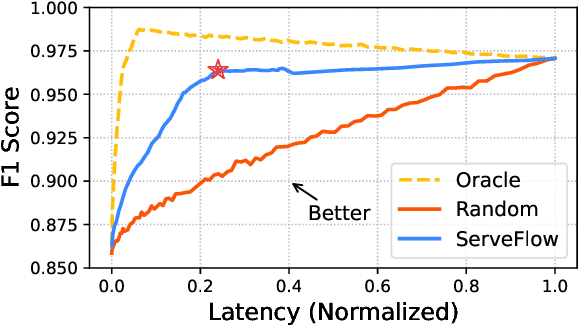
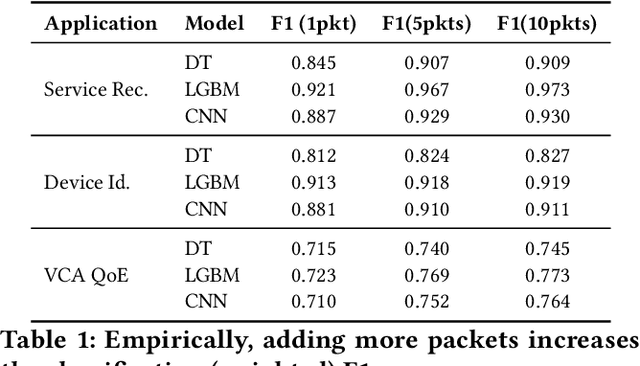
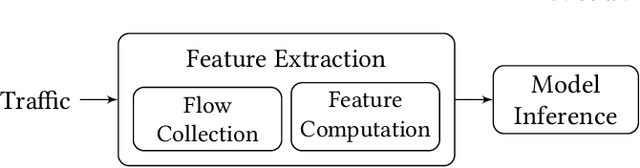
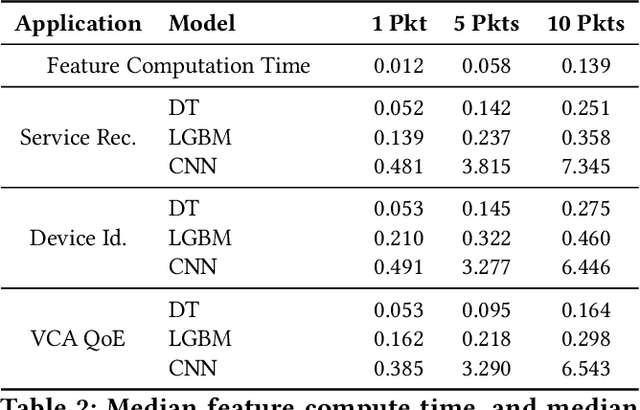
Network traffic analysis increasingly uses complex machine learning models as the internet consolidates and traffic gets more encrypted. However, over high-bandwidth networks, flows can easily arrive faster than model inference rates. The temporal nature of network flows limits simple scale-out approaches leveraged in other high-traffic machine learning applications. Accordingly, this paper presents ServeFlow, a solution for machine-learning model serving aimed at network traffic analysis tasks, which carefully selects the number of packets to collect and the models to apply for individual flows to achieve a balance between minimal latency, high service rate, and high accuracy. We identify that on the same task, inference time across models can differ by 2.7x-136.3x, while the median inter-packet waiting time is often 6-8 orders of magnitude higher than the inference time! ServeFlow is able to make inferences on 76.3% flows in under 16ms, which is a speed-up of 40.5x on the median end-to-end serving latency while increasing the service rate and maintaining similar accuracy. Even with thousands of features per flow, it achieves a service rate of over 48.5k new flows per second on a 16-core CPU commodity server, which matches the order of magnitude of flow rates observed on city-level network backbones.
DeepScribe: Localization and Classification of Elamite Cuneiform Signs Via Deep Learning
Jun 02, 2023



Twenty-five hundred years ago, the paperwork of the Achaemenid Empire was recorded on clay tablets. In 1933, archaeologists from the University of Chicago's Oriental Institute (OI) found tens of thousands of these tablets and fragments during the excavation of Persepolis. Many of these tablets have been painstakingly photographed and annotated by expert cuneiformists, and now provide a rich dataset consisting of over 5,000 annotated tablet images and 100,000 cuneiform sign bounding boxes. We leverage this dataset to develop DeepScribe, a modular computer vision pipeline capable of localizing cuneiform signs and providing suggestions for the identity of each sign. We investigate the difficulty of learning subtasks relevant to cuneiform tablet transcription on ground-truth data, finding that a RetinaNet object detector can achieve a localization mAP of 0.78 and a ResNet classifier can achieve a top-5 sign classification accuracy of 0.89. The end-to-end pipeline achieves a top-5 classification accuracy of 0.80. As part of the classification module, DeepScribe groups cuneiform signs into morphological clusters. We consider how this automatic clustering approach differs from the organization of standard, printed sign lists and what we may learn from it. These components, trained individually, are sufficient to produce a system that can analyze photos of cuneiform tablets from the Achaemenid period and provide useful transliteration suggestions to researchers. We evaluate the model's end-to-end performance on locating and classifying signs, providing a roadmap to a linguistically-aware transliteration system, then consider the model's potential utility when applied to other periods of cuneiform writing.
EdgeServe: An Execution Layer for Decentralized Prediction
Mar 02, 2023The relevant features for a machine learning task may be aggregated from data sources collected on different nodes in a network. This problem, which we call decentralized prediction, creates a number of interesting systems challenges in managing data routing, placing computation, and time-synchronization. This paper presents EdgeServe, a machine learning system that can serve decentralized predictions. EdgeServe relies on a low-latency message broker to route data through a network to nodes that can serve predictions. EdgeServe relies on a series of novel optimizations that can tradeoff computation, communication, and accuracy. We evaluate EdgeServe on three decentralized prediction tasks: (1) multi-camera object tracking, (2) network intrusion detection, and (3) human activity recognition.
VizExtract: Automatic Relation Extraction from Data Visualizations
Dec 07, 2021

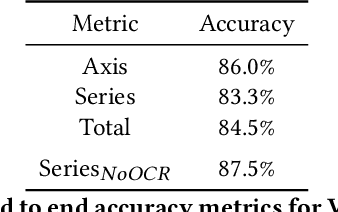
Visual graphics, such as plots, charts, and figures, are widely used to communicate statistical conclusions. Extracting information directly from such visualizations is a key sub-problem for effective search through scientific corpora, fact-checking, and data extraction. This paper presents a framework for automatically extracting compared variables from statistical charts. Due to the diversity and variation of charting styles, libraries, and tools, we leverage a computer vision based framework to automatically identify and localize visualization facets in line graphs, scatter plots, or bar graphs and can include multiple series per graph. The framework is trained on a large synthetically generated corpus of matplotlib charts and we evaluate the trained model on other chart datasets. In controlled experiments, our framework is able to classify, with 87.5% accuracy, the correlation between variables for graphs with 1-3 series per graph, varying colors, and solid line styles. When deployed on real-world graphs scraped from the internet, it achieves 72.8% accuracy (81.2% accuracy when excluding "hard" graphs). When deployed on the FigureQA dataset, it achieves 84.7% accuracy.
Machine Learning enabled Spectrum Sharing in Dense LTE-U/Wi-Fi Coexistence Scenarios
Mar 18, 2020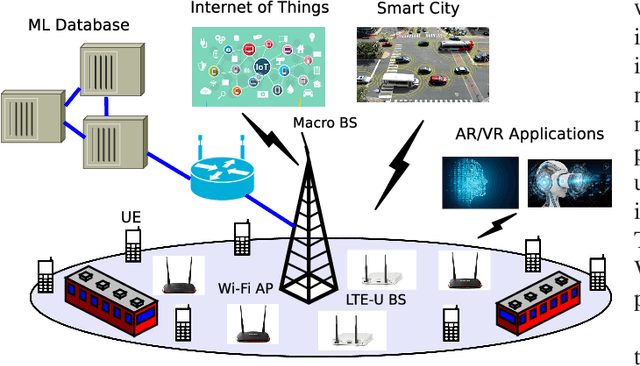
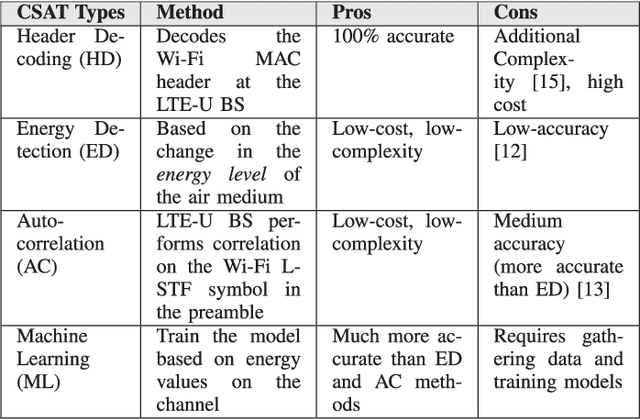
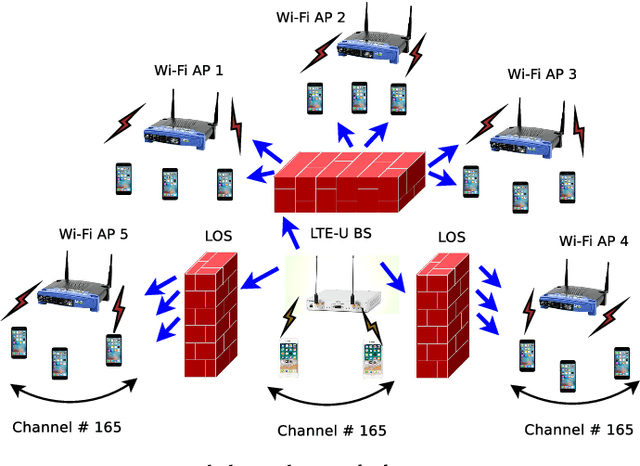
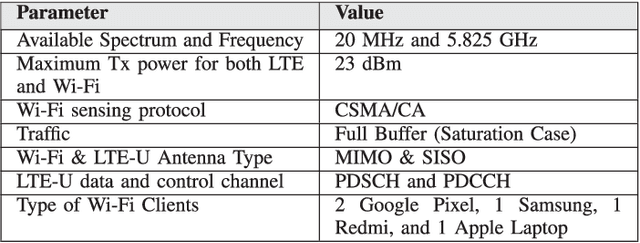
The application of Machine Learning (ML) techniques to complex engineering problems has proved to be an attractive and efficient solution. ML has been successfully applied to several practical tasks like image recognition, automating industrial operations, etc. The promise of ML techniques in solving non-linear problems influenced this work which aims to apply known ML techniques and develop new ones for wireless spectrum sharing between Wi-Fi and LTE in the unlicensed spectrum. In this work, we focus on the LTE-Unlicensed (LTE-U) specification developed by the LTE-U Forum, which uses the duty-cycle approach for fair coexistence. The specification suggests reducing the duty cycle at the LTE-U base-station (BS) when the number of co-channel Wi-Fi basic service sets (BSSs) increases from one to two or more. However, without decoding the Wi-Fi packets, detecting the number of Wi-Fi BSSs operating on the channel in real-time is a challenging problem. In this work, we demonstrate a novel ML-based approach which solves this problem by using energy values observed during the LTE-U OFF duration. It is relatively straightforward to observe only the energy values during the LTE-U BS OFF time compared to decoding the entire Wi-Fi packet, which would require a full Wi-Fi receiver at the LTE-U base-station. We implement and validate the proposed ML-based approach by real-time experiments and demonstrate that there exist distinct patterns between the energy distributions between one and many Wi-Fi AP transmissions. The proposed ML-based approach results in a higher accuracy (close to 99\% in all cases) as compared to the existing auto-correlation (AC) and energy detection (ED) approaches.
An Empirical Evaluation of Perturbation-based Defenses
Feb 08, 2020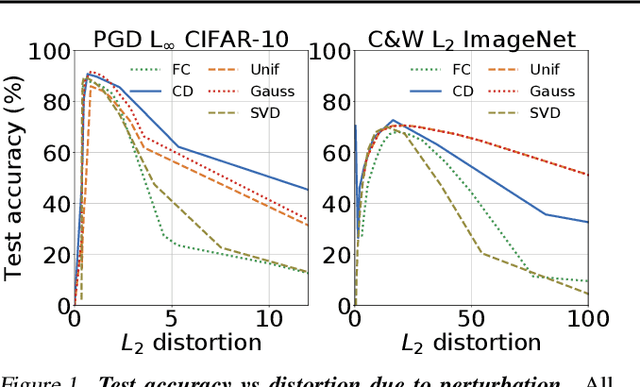
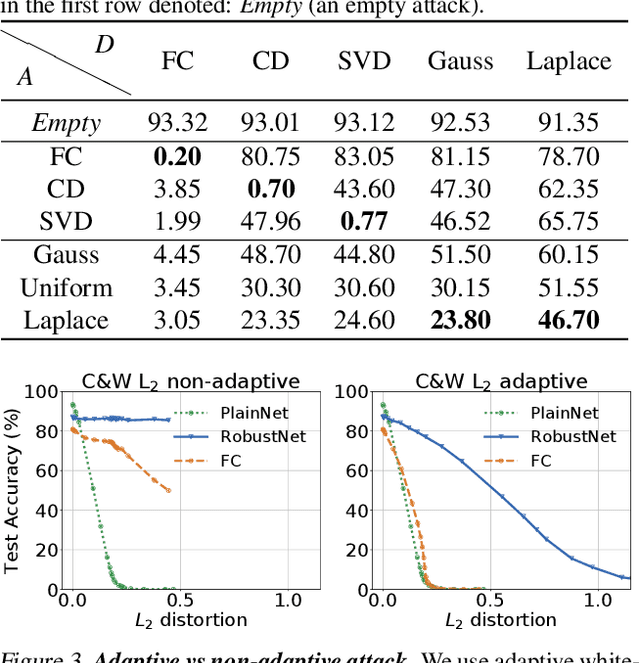
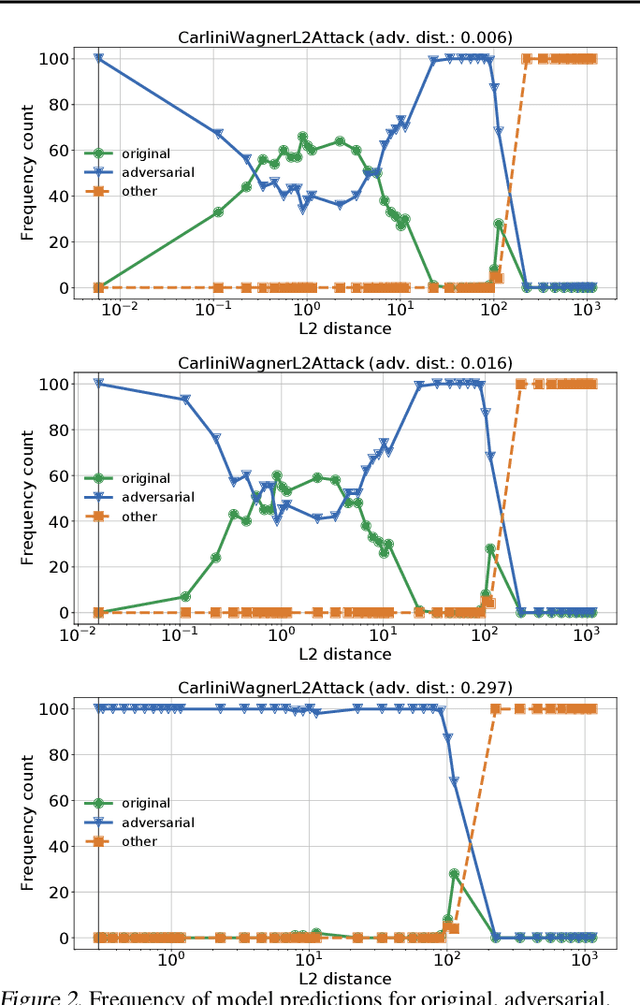
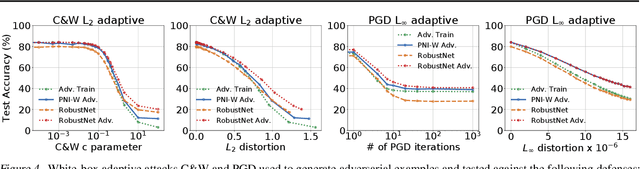
Recent work has extensively shown that randomized perturbations of a neural network can improve its robustness to adversarial attacks. The literature is, however, lacking a detailed compare-and-contrast of the latest proposals to understand what classes of perturbations work, when they work, and why they work. We contribute a detailed experimental evaluation that elucidates these questions and benchmarks perturbation defenses in a consistent way. In particular, we show five main results: (1) all input perturbation defenses, whether random or deterministic, are essentially equivalent in their efficacy, (2) such defenses offer almost no robustness to adaptive attacks unless these perturbations are observed during training, (3) a tuned sequence of noise layers across a network provides the best empirical robustness, (4) attacks transfer between perturbation defenses so the attackers need not know the specific type of defense only that it involves perturbations, and (5) adversarial examples very close to original images show an elevated sensitivity to perturbation in a first-order analysis. Based on these insights, we demonstrate a new robust model built on noise injection and adversarial training that achieves state-of-the-art robustness.
Machine Learning based detection of multiple Wi-Fi BSSs for LTE-U CSAT
Nov 21, 2019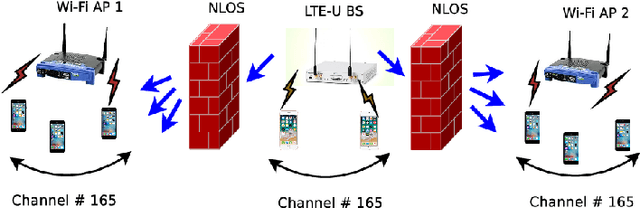
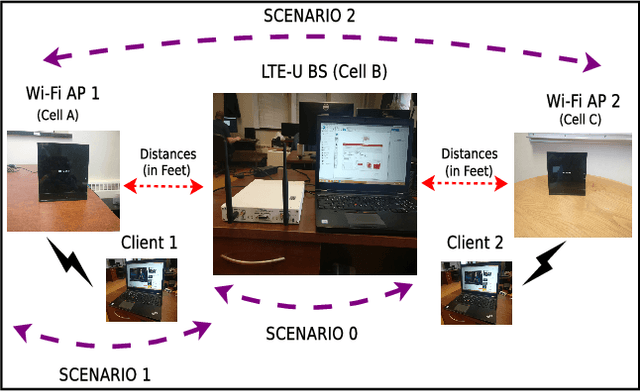
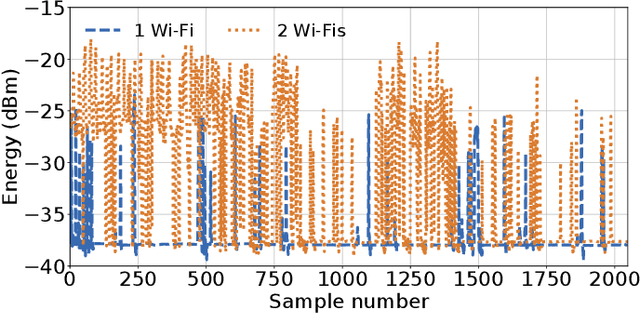
According to the LTE-U Forum specification, a LTE-U base-station (BS) reduces its duty cycle from 50% to 33% when it senses an increase in the number of co-channel Wi-Fi basic service sets (BSSs) from one to two. The detection of the number of Wi-Fi BSSs that are operating on the channel in real-time, without decoding the Wi-Fi packets, still remains a challenge. In this paper, we present a novel machine learning (ML) approach that solves the problem by using energy values observed during LTE-U OFF duration. Observing the energy values (at LTE-U BS OFF time) is a much simpler operation than decoding the entire Wi-Fi packets. In this work, we implement and validate the proposed ML based approach in real-time experiments, and demonstrate that there are two distinct patterns between one and two Wi-Fi APs. This approach delivers an accuracy close to 100% compared to auto-correlation (AC) and energy detection (ED) approaches.