 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Causal Physical Error Discovery in Video Analytics Systems
May 27, 2024Video analytics systems based on deep learning models are often opaque and brittle and require explanation systems to help users debug. Current model explanation system are very good at giving literal explanations of behavior in terms of pixel contributions but cannot integrate information about the physical or systems processes that might influence a prediction. This paper introduces the idea that a simple form of causal reasoning, called a regression discontinuity design, can be used to associate changes in multiple key performance indicators to physical real world phenomena to give users a more actionable set of video analytics explanations. We overview the system architecture and describe a vision of the impact that such a system might have.
vONTSS: vMF based semi-supervised neural topic modeling with optimal transport
Jul 03, 2023
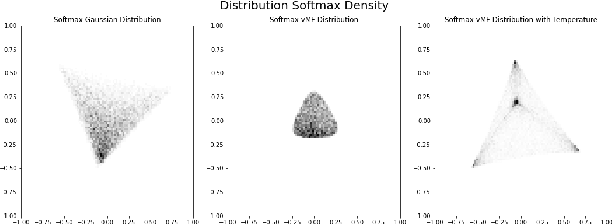
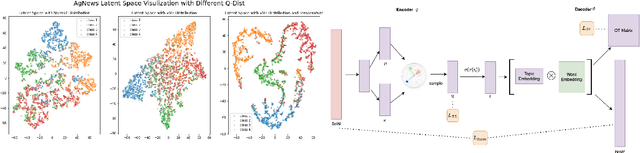
Recently, Neural Topic Models (NTM), inspired by variational autoencoders, have attracted a lot of research interest; however, these methods have limited applications in the real world due to the challenge of incorporating human knowledge. This work presents a semi-supervised neural topic modeling method, vONTSS, which uses von Mises-Fisher (vMF) based variational autoencoders and optimal transport. When a few keywords per topic are provided, vONTSS in the semi-supervised setting generates potential topics and optimizes topic-keyword quality and topic classification. Experiments show that vONTSS outperforms existing semi-supervised topic modeling methods in classification accuracy and diversity. vONTSS also supports unsupervised topic modeling. Quantitative and qualitative experiments show that vONTSS in the unsupervised setting outperforms recent NTMs on multiple aspects: vONTSS discovers highly clustered and coherent topics on benchmark datasets. It is also much faster than the state-of-the-art weakly supervised text classification method while achieving similar classification performance. We further prove the equivalence of optimal transport loss and cross-entropy loss at the global minimum.
* 24 pages, 12 figures, ACL findings 2023
FFPDG: Fast, Fair and Private Data Generation
Jun 30, 2023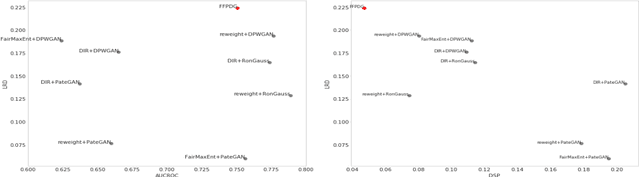
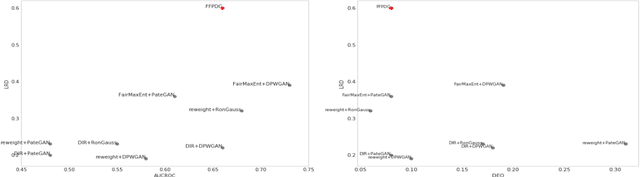

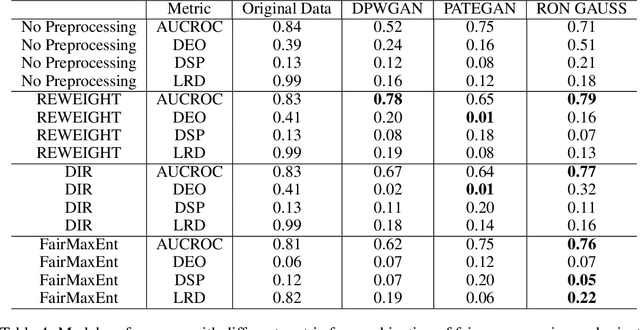
Generative modeling has been used frequently in synthetic data generation. Fairness and privacy are two big concerns for synthetic data. Although Recent GAN [\cite{goodfellow2014generative}] based methods show good results in preserving privacy, the generated data may be more biased. At the same time, these methods require high computation resources. In this work, we design a fast, fair, flexible and private data generation method. We show the effectiveness of our method theoretically and empirically. We show that models trained on data generated by the proposed method can perform well (in inference stage) on real application scenarios.
* 12 pages, 2 figures, ICLR 2021 Workshop on Synthetic Data Generation
Deep Transfer Learning with Graph Neural Network for Sensor-Based Human Activity Recognition
Mar 14, 2022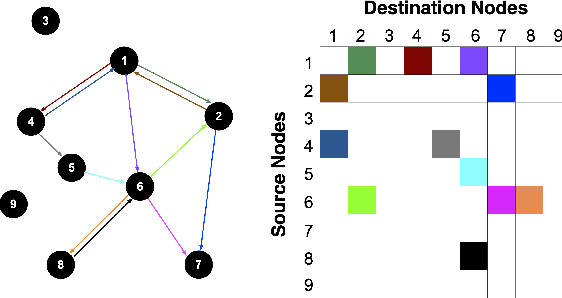
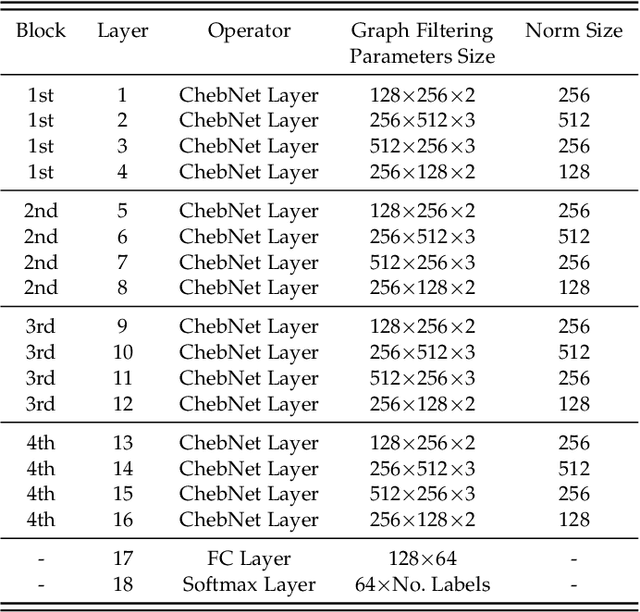
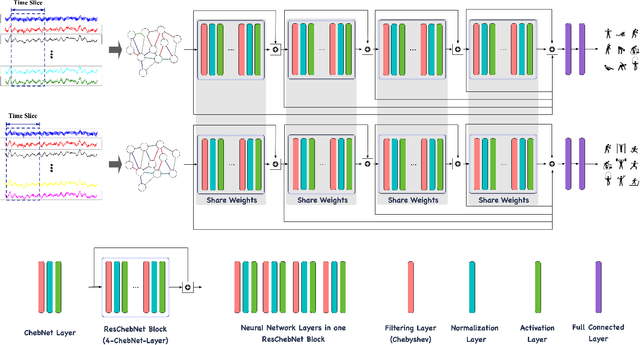
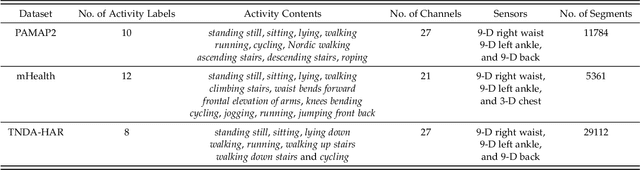
The sensor-based human activity recognition (HAR) in mobile application scenarios is often confronted with sensor modalities variation and annotated data deficiency. Given this observation, we devised a graph-inspired deep learning approach toward the sensor-based HAR tasks, which was further used to build a deep transfer learning model toward giving a tentative solution for these two challenging problems. Specifically, we present a multi-layer residual structure involved graph convolutional neural network (ResGCNN) toward the sensor-based HAR tasks, namely the HAR-ResGCNN approach. Experimental results on the PAMAP2 and mHealth data sets demonstrate that our ResGCNN is effective at capturing the characteristics of actions with comparable results compared to other sensor-based HAR models (with an average accuracy of 98.18% and 99.07%, respectively). More importantly, the deep transfer learning experiments using the ResGCNN model show excellent transferability and few-shot learning performance. The graph-based framework shows good meta-learning ability and is supposed to be a promising solution in sensor-based HAR tasks.
Knowledge Graph semantic enhancement of input data for improving AI
May 10, 2020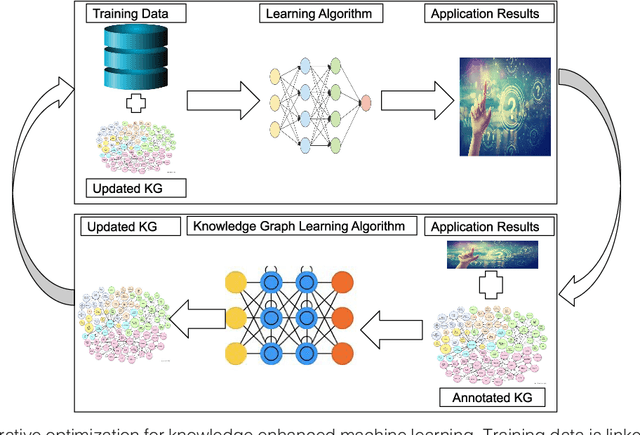
Intelligent systems designed using machine learning algorithms require a large number of labeled data. Background knowledge provides complementary, real world factual information that can augment the limited labeled data to train a machine learning algorithm. The term Knowledge Graph (KG) is in vogue as for many practical applications, it is convenient and useful to organize this background knowledge in the form of a graph. Recent academic research and implemented industrial intelligent systems have shown promising performance for machine learning algorithms that combine training data with a knowledge graph. In this article, we discuss the use of relevant KGs to enhance input data for two applications that use machine learning -- recommendation and community detection. The KG improves both accuracy and explainability.