Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFPDG: Fast, Fair and Private Data Generation
Paper and Code
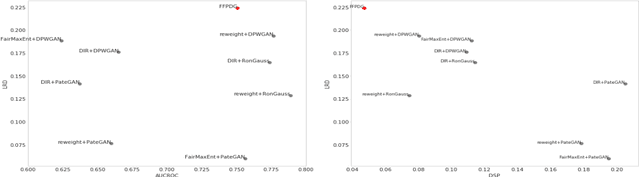
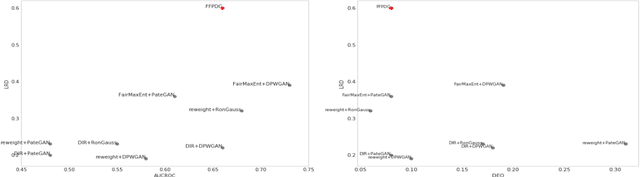

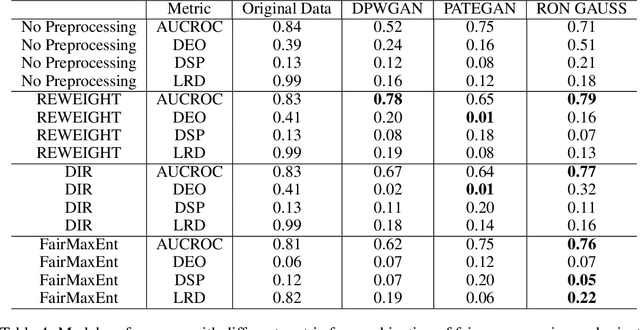
Generative modeling has been used frequently in synthetic data generation. Fairness and privacy are two big concerns for synthetic data. Although Recent GAN [\cite{goodfellow2014generative}] based methods show good results in preserving privacy, the generated data may be more biased. At the same time, these methods require high computation resources. In this work, we design a fast, fair, flexible and private data generation method. We show the effectiveness of our method theoretically and empirically. We show that models trained on data generated by the proposed method can perform well (in inference stage) on real application scenarios.
* ICLR 2021 Workshop on Synthetic Data Generation * 12 pages, 2 figures, ICLR 2021 Workshop on Synthetic Data Generation
View paper on