 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2vNTM: Semi-supervised vMF Neural Topic Modeling
Jul 06, 2023Language model based methods are powerful techniques for text classification. However, the models have several shortcomings. (1) It is difficult to integrate human knowledge such as keywords. (2) It needs a lot of resources to train the models. (3) It relied on large text data to pretrain. In this paper, we propose Semi-Supervised vMF Neural Topic Modeling (S2vNTM) to overcome these difficulties. S2vNTM takes a few seed keywords as input for topics. S2vNTM leverages the pattern of keywords to identify potential topics, as well as optimize the quality of topics' keywords sets. Across a variety of datasets, S2vNTM outperforms existing semi-supervised topic modeling methods in classification accuracy with limited keywords provided. S2vNTM is at least twice as fast as baselines.
* 17 pages, 9 figures, ICLR Workshop 2023. arXiv admin note: text overlap with arXiv:2307.01226
KDSTM: Neural Semi-supervised Topic Modeling with Knowledge Distillation
Jul 04, 2023



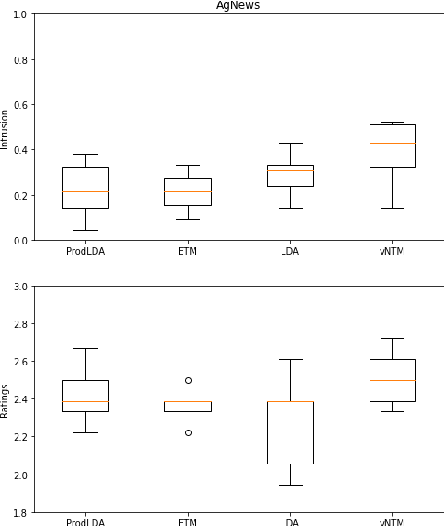
In text classification tasks, fine tuning pretrained language models like BERT and GPT-3 yields competitive accuracy; however, both methods require pretraining on large text datasets. In contrast, general topic modeling methods possess the advantage of analyzing documents to extract meaningful patterns of words without the need of pretraining. To leverage topic modeling's unsupervised insights extraction on text classification tasks, we develop the Knowledge Distillation Semi-supervised Topic Modeling (KDSTM). KDSTM requires no pretrained embeddings, few labeled documents and is efficient to train, making it ideal under resource constrained settings. Across a variety of datasets, our method outperforms existing supervised topic modeling methods in classification accuracy, robustness and efficiency and achieves similar performance compare to state of the art weakly supervised text classification methods.
* 12 pages, 4 figures, ICLR 2022 Workshop
vONTSS: vMF based semi-supervised neural topic modeling with optimal transport
Jul 03, 2023
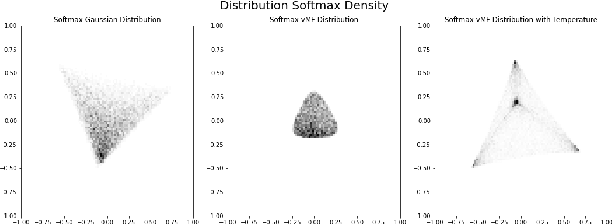
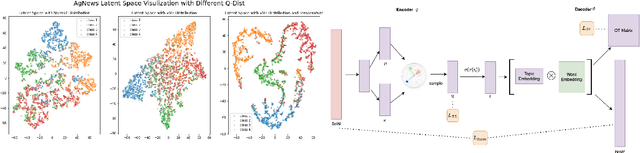
Recently, Neural Topic Models (NTM), inspired by variational autoencoders, have attracted a lot of research interest; however, these methods have limited applications in the real world due to the challenge of incorporating human knowledge. This work presents a semi-supervised neural topic modeling method, vONTSS, which uses von Mises-Fisher (vMF) based variational autoencoders and optimal transport. When a few keywords per topic are provided, vONTSS in the semi-supervised setting generates potential topics and optimizes topic-keyword quality and topic classification. Experiments show that vONTSS outperforms existing semi-supervised topic modeling methods in classification accuracy and diversity. vONTSS also supports unsupervised topic modeling. Quantitative and qualitative experiments show that vONTSS in the unsupervised setting outperforms recent NTMs on multiple aspects: vONTSS discovers highly clustered and coherent topics on benchmark datasets. It is also much faster than the state-of-the-art weakly supervised text classification method while achieving similar classification performance. We further prove the equivalence of optimal transport loss and cross-entropy loss at the global minimum.
* 24 pages, 12 figures, ACL findings 2023
FFPDG: Fast, Fair and Private Data Generation
Jun 30, 2023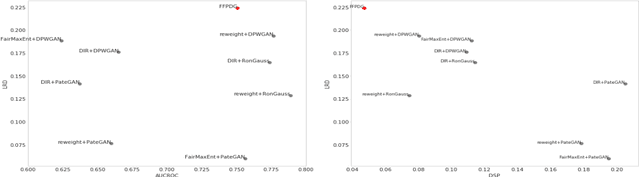
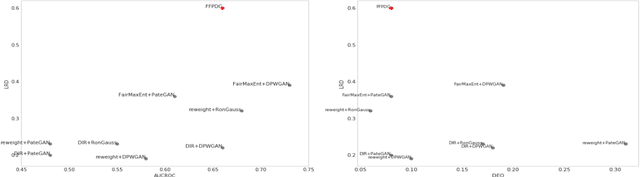

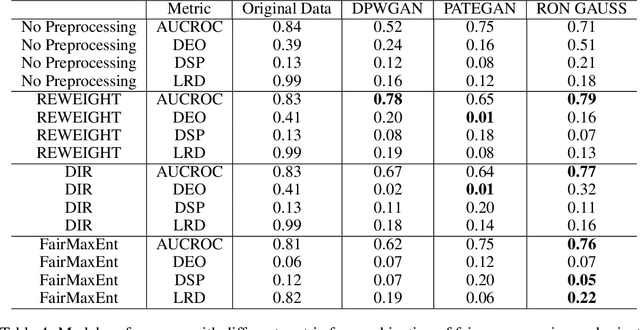
Generative modeling has been used frequently in synthetic data generation. Fairness and privacy are two big concerns for synthetic data. Although Recent GAN [\cite{goodfellow2014generative}] based methods show good results in preserving privacy, the generated data may be more biased. At the same time, these methods require high computation resources. In this work, we design a fast, fair, flexible and private data generation method. We show the effectiveness of our method theoretically and empirically. We show that models trained on data generated by the proposed method can perform well (in inference stage) on real application scenarios.
* 12 pages, 2 figures, ICLR 2021 Workshop on Synthetic Data Generation