 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Mar 01, 2024Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
DeTiME: Diffusion-Enhanced Topic Modeling using Encoder-decoder based LLM
Oct 23, 2023



In the burgeoning field of natural language processing, Neural Topic Models (NTMs) and Large Language Models (LLMs) have emerged as areas of significant research interest. Despite this, NTMs primarily utilize contextual embeddings from LLMs, which are not optimal for clustering or capable for topic generation. Our study addresses this gap by introducing a novel framework named Diffusion-Enhanced Topic Modeling using Encoder-Decoder-based LLMs (DeTiME). DeTiME leverages ncoder-Decoder-based LLMs to produce highly clusterable embeddings that could generate topics that exhibit both superior clusterability and enhanced semantic coherence compared to existing methods. Additionally, by exploiting the power of diffusion, our framework also provides the capability to generate content relevant to the identified topics. This dual functionality allows users to efficiently produce highly clustered topics and related content simultaneously. DeTiME's potential extends to generating clustered embeddings as well. Notably, our proposed framework proves to be efficient to train and exhibits high adaptability, demonstrating its potential for a wide array of applications.
* 19 pages, 4 figures, EMNLP 2023
S2vNTM: Semi-supervised vMF Neural Topic Modeling
Jul 06, 2023Language model based methods are powerful techniques for text classification. However, the models have several shortcomings. (1) It is difficult to integrate human knowledge such as keywords. (2) It needs a lot of resources to train the models. (3) It relied on large text data to pretrain. In this paper, we propose Semi-Supervised vMF Neural Topic Modeling (S2vNTM) to overcome these difficulties. S2vNTM takes a few seed keywords as input for topics. S2vNTM leverages the pattern of keywords to identify potential topics, as well as optimize the quality of topics' keywords sets. Across a variety of datasets, S2vNTM outperforms existing semi-supervised topic modeling methods in classification accuracy with limited keywords provided. S2vNTM is at least twice as fast as baselines.
* 17 pages, 9 figures, ICLR Workshop 2023. arXiv admin note: text overlap with arXiv:2307.01226
Universal Representation for Code
Mar 04, 2021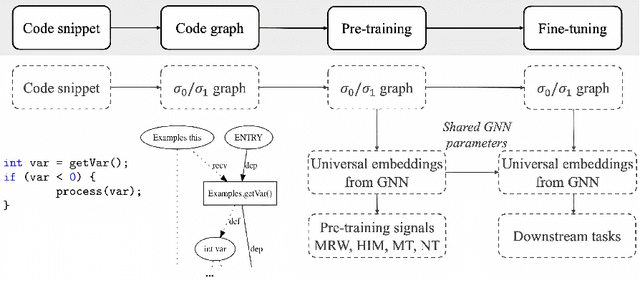
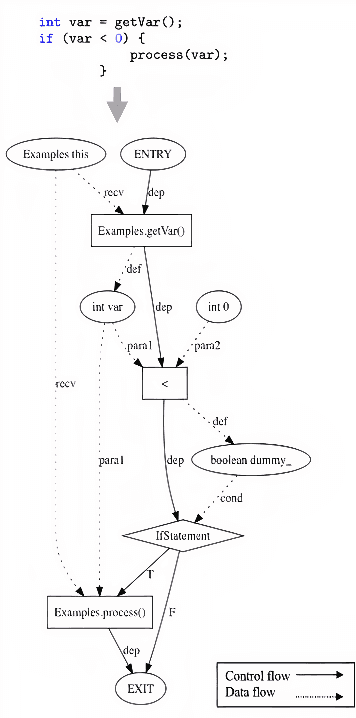

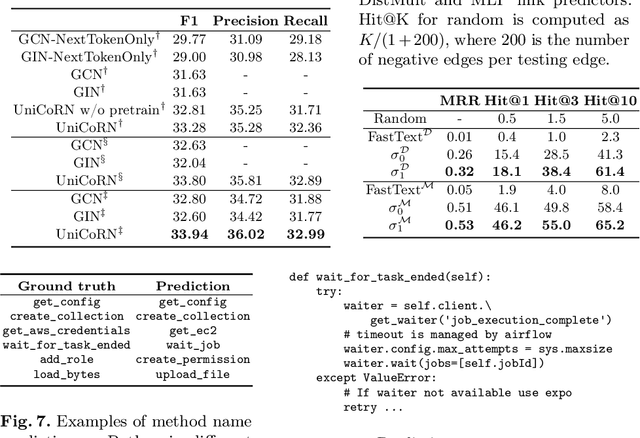
Learning from source code usually requires a large amount of labeled data. Despite the possible scarcity of labeled data, the trained model is highly task-specific and lacks transferability to different tasks. In this work, we present effective pre-training strategies on top of a novel graph-based code representation, to produce universal representations for code. Specifically, our graph-based representation captures important semantics between code elements (e.g., control flow and data flow). We pre-train graph neural networks on the representation to extract universal code properties. The pre-trained model then enables the possibility of fine-tuning to support various downstream applications. We evaluate our model on two real-world datasets -- spanning over 30M Java methods and 770K Python methods. Through visualization, we reveal discriminative properties in our universal code representation. By comparing multiple benchmarks, we demonstrate that the proposed framework achieves state-of-the-art results on method name prediction and code graph link prediction.