 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiCoder: Encompassing Diversity and Complexity in Code Generation
Jan 08, 2025Effective instruction tuning is indispensable for optimizing code LLMs, aligning model behavior with user expectations and enhancing model performance in real-world applications. However, most existing methods focus on code snippets, which are limited to specific functionalities and rigid structures, restricting the complexity and diversity of the synthesized data. To address these limitations, we introduce a novel feature tree-based synthesis framework inspired by Abstract Syntax Trees (AST). Unlike AST, which captures syntactic structure of code, our framework models semantic relationships between code elements, enabling the generation of more nuanced and diverse data. The feature tree is constructed from raw data and refined iteratively to increase the quantity and diversity of the extracted features. This process enables the identification of more complex patterns and relationships within the code. By sampling subtrees with controlled depth and breadth, our framework allows precise adjustments to the complexity of the generated code, supporting a wide range of tasks from simple function-level operations to intricate multi-file scenarios. We fine-tuned widely-used base models to create the EpiCoder series, achieving state-of-the-art performance at both the function and file levels across multiple benchmarks. Notably, empirical evidence indicates that our approach shows significant potential in synthesizing highly complex repository-level code data. Further analysis elucidates the merits of this approach by rigorously assessing data complexity and diversity through software engineering principles and LLM-as-a-judge method.
GRIN: GRadient-INformed MoE
Sep 18, 2024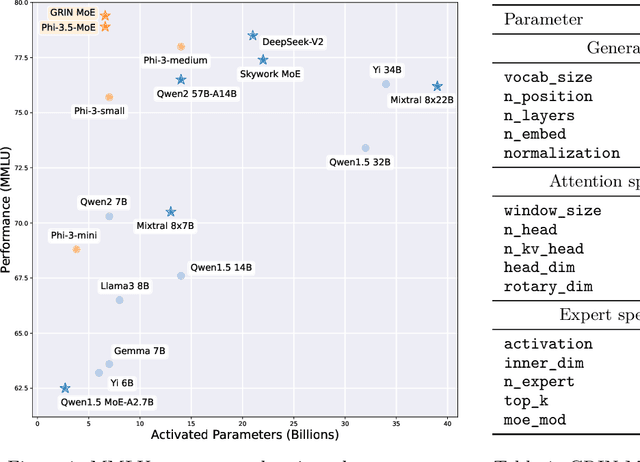
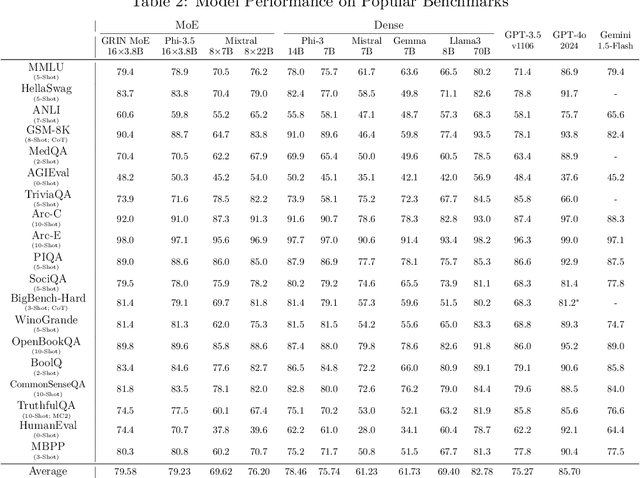
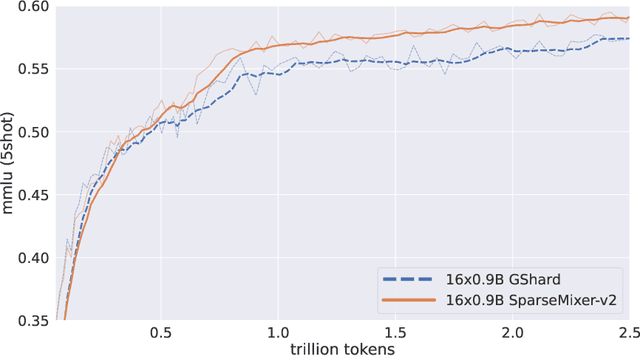

Mixture-of-Experts (MoE) models scale more effectively than dense models due to sparse computation through expert routing, selectively activating only a small subset of expert modules. However, sparse computation challenges traditional training practices, as discrete expert routing hinders standard backpropagation and thus gradient-based optimization, which are the cornerstone of deep learning. To better pursue the scaling power of MoE, we introduce GRIN (GRadient-INformed MoE training), which incorporates sparse gradient estimation for expert routing and configures model parallelism to avoid token dropping. Applying GRIN to autoregressive language modeling, we develop a top-2 16$\times$3.8B MoE model. Our model, with only 6.6B activated parameters, outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data. Extensive evaluations across diverse tasks demonstrate the potential of GRIN to significantly enhance MoE efficacy, achieving 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH.
HR-MultiWOZ: A Task Oriented Dialogue Dataset for HR LLM Agent
Feb 01, 2024



Recent advancements in Large Language Models (LLMs) have been reshaping Natural Language Processing (NLP) task in several domains. Their use in the field of Human Resources (HR) has still room for expansions and could be beneficial for several time consuming tasks. Examples such as time-off submissions, medical claims filing, and access requests are noteworthy, but they are by no means the sole instances. However, the aforementioned developments must grapple with the pivotal challenge of constructing a high-quality training dataset. On one hand, most conversation datasets are solving problems for customers not employees. On the other hand, gathering conversations with HR could raise privacy concerns. To solve it, we introduce HR-Multiwoz, a fully-labeled dataset of 550 conversations spanning 10 HR domains to evaluate LLM Agent. Our work has the following contributions: (1) It is the first labeled open-sourced conversation dataset in the HR domain for NLP research. (2) It provides a detailed recipe for the data generation procedure along with data analysis and human evaluations. The data generation pipeline is transferable and can be easily adapted for labeled conversation data generation in other domains. (3) The proposed data-collection pipeline is mostly based on LLMs with minimal human involvement for annotation, which is time and cost-efficient.
* 13 pages, 9 figures
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
Jan 11, 2024Recent work demonstrates that, after being fine-tuned on a high-quality instruction dataset, the resulting model can obtain impressive capabilities to address a wide range of tasks. However, existing methods for instruction data generation often produce duplicate data and are not controllable enough on data quality. In this paper, we extend the generalization of instruction tuning by classifying the instruction data to 4 code-related tasks and propose a LLM-based Generator-Discriminator data process framework to generate diverse, high-quality instruction data from open source code. Hence, we introduce CodeOcean, a dataset comprising 20,000 instruction instances across 4 universal code-related tasks,which is aimed at augmenting the effectiveness of instruction tuning and improving the generalization ability of fine-tuned model. Subsequently, we present WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. This model is specifically designed for enhancing instruction tuning of Code Language Models (LLMs). Our experiments demonstrate that Wavecoder models outperform other open-source models in terms of generalization ability across different code-related tasks at the same level of fine-tuning scale. Moreover, Wavecoder exhibits high efficiency in previous code generation tasks. This paper thus offers a significant contribution to the field of instruction data generation and fine-tuning models, providing new insights and tools for enhancing performance in code-related tasks.
DeTiME: Diffusion-Enhanced Topic Modeling using Encoder-decoder based LLM
Oct 23, 2023



In the burgeoning field of natural language processing, Neural Topic Models (NTMs) and Large Language Models (LLMs) have emerged as areas of significant research interest. Despite this, NTMs primarily utilize contextual embeddings from LLMs, which are not optimal for clustering or capable for topic generation. Our study addresses this gap by introducing a novel framework named Diffusion-Enhanced Topic Modeling using Encoder-Decoder-based LLMs (DeTiME). DeTiME leverages ncoder-Decoder-based LLMs to produce highly clusterable embeddings that could generate topics that exhibit both superior clusterability and enhanced semantic coherence compared to existing methods. Additionally, by exploiting the power of diffusion, our framework also provides the capability to generate content relevant to the identified topics. This dual functionality allows users to efficiently produce highly clustered topics and related content simultaneously. DeTiME's potential extends to generating clustered embeddings as well. Notably, our proposed framework proves to be efficient to train and exhibits high adaptability, demonstrating its potential for a wide array of applications.
* 19 pages, 4 figures, EMNLP 2023
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Jun 14, 2023Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we introduce WizardCoder, which empowers Code LLMs with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code. Through comprehensive experiments on four prominent code generation benchmarks, namely HumanEval, HumanEval+, MBPP, and DS-1000, we unveil the exceptional capabilities of our model. It surpasses all other open-source Code LLMs by a substantial margin. Moreover, our model even outperforms the largest closed LLMs, Anthropic's Claude and Google's Bard, on HumanEval and HumanEval+. Our code, model weights, and data are public at https://github.com/nlpxucan/WizardLM