 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigma-MoE-Tiny Technical Report
Dec 19, 2025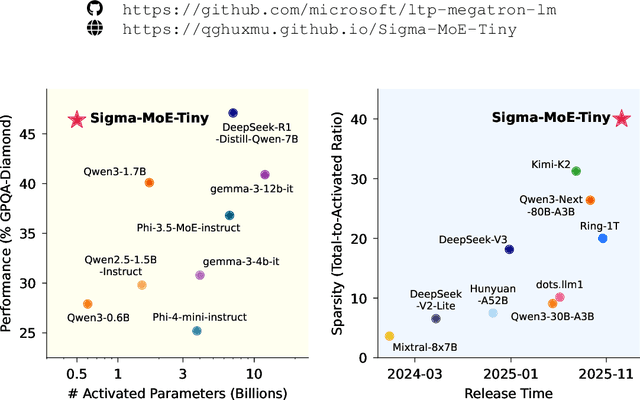

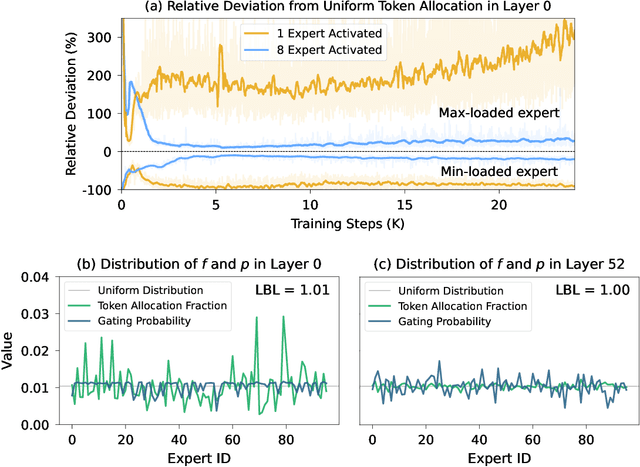
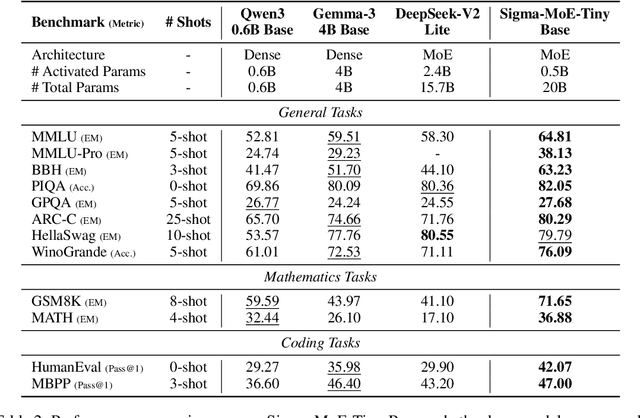
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025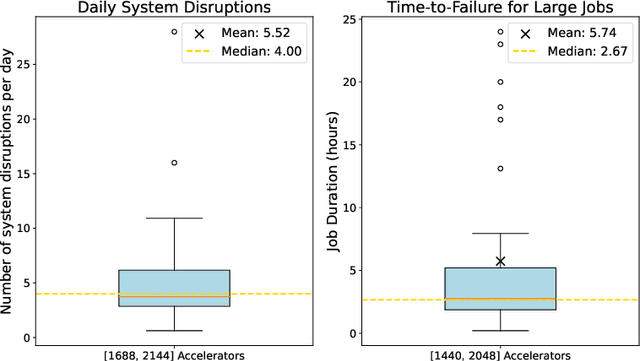

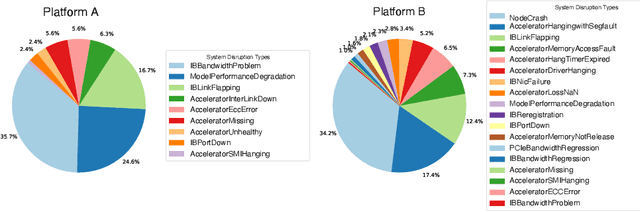

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation
Mar 09, 2025Implementing new features in repository-level codebases is a crucial application of code generation models. However, current benchmarks lack a dedicated evaluation framework for this capability. To fill this gap, we introduce FEA-Bench, a benchmark designed to assess the ability of large language models (LLMs) to perform incremental development within code repositories. We collect pull requests from 83 GitHub repositories and use rule-based and intent-based filtering to construct task instances focused on new feature development. Each task instance containing code changes is paired with relevant unit test files to ensure that the solution can be verified. The feature implementation requires LLMs to simultaneously possess code completion capabilities for new components and code editing abilities for other relevant parts in the code repository, providing a more comprehensive evaluation method of LLMs' automated software engineering capabilities. Experimental results show that LLMs perform significantly worse in the FEA-Bench, highlighting considerable challenges in such repository-level incremental code development.
Beyond Prompt Content: Enhancing LLM Performance via Content-Format Integrated Prompt Optimization
Feb 10, 2025Large Language Models (LLMs) have shown significant capability across various tasks, with their real-world effectiveness often driven by prompt design. While recent research has focused on optimizing prompt content, the role of prompt formatting, a critical but often overlooked dimension, has received limited systematic investigation. In this paper, we introduce Content-Format Integrated Prompt Optimization (CFPO), an innovative methodology that jointly optimizes both prompt content and formatting through an iterative refinement process. CFPO leverages natural language mutations to explore content variations and employs a dynamic format exploration strategy that systematically evaluates diverse format options. Our extensive evaluations across multiple tasks and open-source LLMs demonstrate that CFPO demonstrates measurable performance improvements compared to content-only optimization methods. This highlights the importance of integrated content-format optimization and offers a practical, model-agnostic approach to enhancing LLM performance. Code is available at https://github.com/HenryLau7/CFPO.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
EpiCoder: Encompassing Diversity and Complexity in Code Generation
Jan 08, 2025Effective instruction tuning is indispensable for optimizing code LLMs, aligning model behavior with user expectations and enhancing model performance in real-world applications. However, most existing methods focus on code snippets, which are limited to specific functionalities and rigid structures, restricting the complexity and diversity of the synthesized data. To address these limitations, we introduce a novel feature tree-based synthesis framework inspired by Abstract Syntax Trees (AST). Unlike AST, which captures syntactic structure of code, our framework models semantic relationships between code elements, enabling the generation of more nuanced and diverse data. The feature tree is constructed from raw data and refined iteratively to increase the quantity and diversity of the extracted features. This process enables the identification of more complex patterns and relationships within the code. By sampling subtrees with controlled depth and breadth, our framework allows precise adjustments to the complexity of the generated code, supporting a wide range of tasks from simple function-level operations to intricate multi-file scenarios. We fine-tuned widely-used base models to create the EpiCoder series, achieving state-of-the-art performance at both the function and file levels across multiple benchmarks. Notably, empirical evidence indicates that our approach shows significant potential in synthesizing highly complex repository-level code data. Further analysis elucidates the merits of this approach by rigorously assessing data complexity and diversity through software engineering principles and LLM-as-a-judge method.