 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgem3BERT: A Modern, Multi-lingual, Matryoshka Bidirectional Encoder
May 19, 2026Embedding models are pivotal in industrial information retrieval systems like search and advertising. However, existing pretrained models often exhibit fixed architectures and embedding dimensionalities, posing significant challenges when adapting them to diverse deployment scenarios with varying business-driven constraints. A common practice involves fine-tuning with partial parameter initialization from larger pretrained models for resource-constrained tasks. This method is often suboptimal as the misalignment between pretraining and downstream usage prevents full realization of pretraining benefits. To address this limitation, we introduce m3BERT: a Modern, Multi-lingual, Matryoshka Bidirectional Encoder, which features a novel pretraining strategy that jointly optimizes representations across both transformer layers and multiple embedding dimensions. This enables a single model to be tailored to varied resource and accuracy targets while maintaining consistency with pretraining. Incorporating recent architectural improvements, m3BERT uses a three-stage pretraining: monolingual pretraining, multilingual adaptation to serve diverse user bases, and crucial continual pretraining on a massive web domain corpus to enhance utility in commercial retrieval. m3BERT significantly outperforms state-of-the-art embedding models in Bing-Click, a large-scale industrial retrieval dataset, showcasing its practical versatility as an efficient foundation for resource-aware industrial retrieval systems. Further experiments on public datasets also confirm the general effectiveness of our multigranular Matryoshka pretraining strategy.
MSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration
Feb 02, 2026Training instability remains a critical challenge in large language model (LLM) pretraining, often manifesting as sudden gradient explosions that waste significant computational resources. We study training failures in a 5M-parameter NanoGPT model scaled via $μ$P, identifying two key phenomena preceding collapse: (1) rapid decline in weight matrix stable rank (ratio of squared Frobenius norm to squared spectral norm), and (2) increasing alignment between adjacent layer Jacobians. We prove theoretically that these two conditions jointly cause exponential gradient norm growth with network depth. To break this instability mechanism, we propose MSign, a new optimizer that periodically applies matrix sign operations to restore stable rank. Experiments on models from 5M to 3B parameters demonstrate that MSign effectively prevents training failures with a computational overhead of less than 7.0%.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025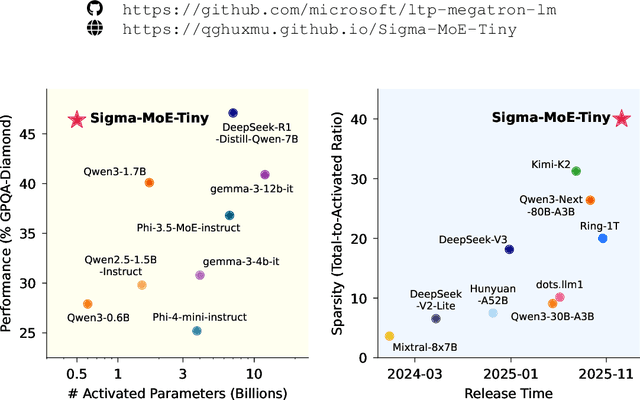

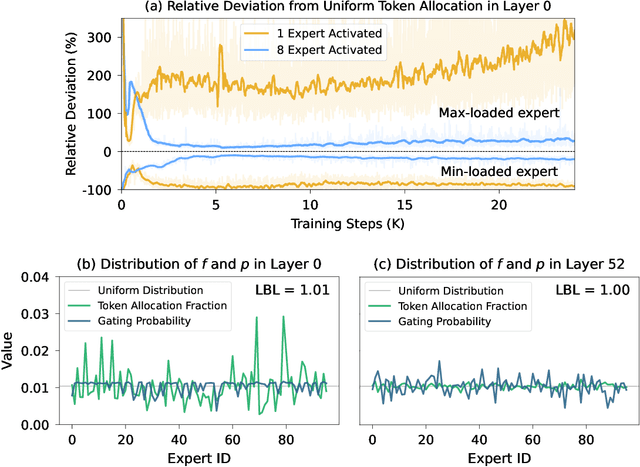
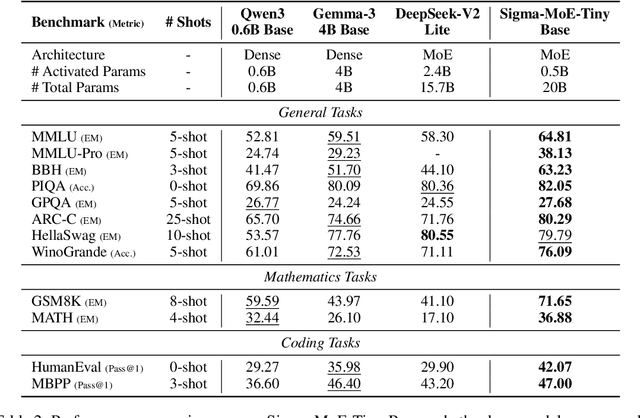
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025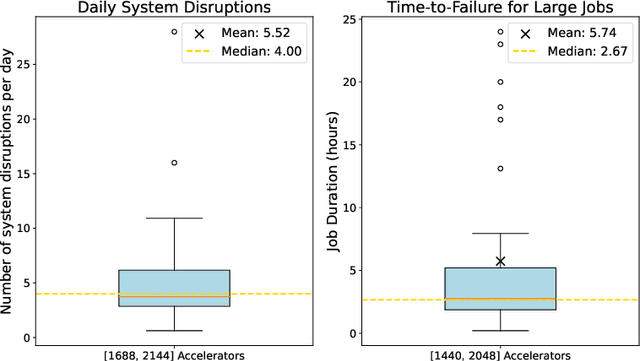

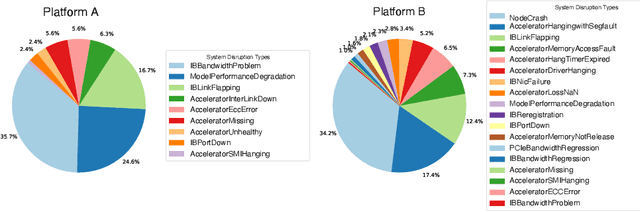

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Recycling Pretrained Checkpoints: Orthogonal Growth of Mixture-of-Experts for Efficient Large Language Model Pre-Training
Oct 09, 2025The rapidly increasing computational cost of pretraining Large Language Models necessitates more efficient approaches. Numerous computational costs have been invested in existing well-trained checkpoints, but many of them remain underutilized due to engineering constraints or limited model capacity. To efficiently reuse this "sunk" cost, we propose to recycle pretrained checkpoints by expanding their parameter counts and continuing training. We propose orthogonal growth method well-suited for converged Mixture-of-Experts model: interpositional layer copying for depth growth and expert duplication with injected noise for width growth. To determine the optimal timing for such growth across checkpoints sequences, we perform comprehensive scaling experiments revealing that the final accuracy has a strong positive correlation with the amount of sunk cost, indicating that greater prior investment leads to better performance. We scale our approach to models with 70B parameters and over 1T training tokens, achieving 10.66% accuracy gain over training from scratch under the same additional compute budget. Our checkpoint recycling approach establishes a foundation for economically efficient large language model pretraining.
Training Matryoshka Mixture-of-Experts for Elastic Inference-Time Expert Utilization
Sep 30, 2025Mixture-of-Experts (MoE) has emerged as a promising paradigm for efficiently scaling large language models without a proportional increase in computational cost. However, the standard training strategy of Top-K router prevents MoE models from realizing their full potential for elastic inference. When the number of activated experts is altered at inference time, these models exhibit precipitous performance degradation. In this work, we introduce Matryoshka MoE (M-MoE), a training framework that instills a coarse-to-fine structure directly into the expert ensemble. By systematically varying the number of activated experts during training, M-MoE compels the model to learn a meaningful ranking: top-ranked experts collaborate to provide essential, coarse-grained capabilities, while subsequent experts add progressively finer-grained detail. We explore this principle at multiple granularities, identifying a layer-wise randomization strategy as the most effective. Our experiments demonstrate that a single M-MoE model achieves remarkable elasticity, with its performance at various expert counts closely matching that of an entire suite of specialist models, but at only a fraction of the total training cost. This flexibility not only unlocks elastic inference but also enables optimizing performance by allocating different computational budgets to different model layers. Our work paves the way for more practical and adaptable deployments of large-scale MoE models.
Discovering Fine-Grained Visual-Concept Relations by Disentangled Optimal Transport Concept Bottleneck Models
May 12, 2025



Concept Bottleneck Models (CBMs) try to make the decision-making process transparent by exploring an intermediate concept space between the input image and the output prediction. Existing CBMs just learn coarse-grained relations between the whole image and the concepts, less considering local image information, leading to two main drawbacks: i) they often produce spurious visual-concept relations, hence decreasing model reliability; and ii) though CBMs could explain the importance of every concept to the final prediction, it is still challenging to tell which visual region produces the prediction. To solve these problems, this paper proposes a Disentangled Optimal Transport CBM (DOT-CBM) framework to explore fine-grained visual-concept relations between local image patches and concepts. Specifically, we model the concept prediction process as a transportation problem between the patches and concepts, thereby achieving explicit fine-grained feature alignment. We also incorporate orthogonal projection losses within the modality to enhance local feature disentanglement. To further address the shortcut issues caused by statistical biases in the data, we utilize the visual saliency map and concept label statistics as transportation priors. Thus, DOT-CBM can visualize inversion heatmaps, provide more reliable concept predictions, and produce more accurate class predictions. Comprehensive experiments demonstrate that our proposed DOT-CBM achieves SOTA performance on several tasks, including image classification, local part detection and out-of-distribution generalization.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025


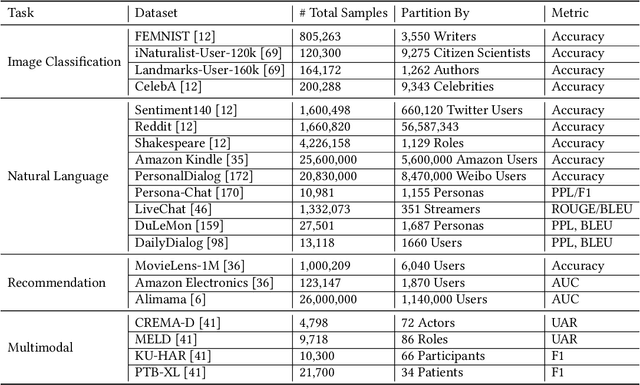
The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.
Personalized Language Model Learning on Text Data Without User Identifiers
Jan 10, 2025



In many practical natural language applications, user data are highly sensitive, requiring anonymous uploads of text data from mobile devices to the cloud without user identifiers. However, the absence of user identifiers restricts the ability of cloud-based language models to provide personalized services, which are essential for catering to diverse user needs. The trivial method of replacing an explicit user identifier with a static user embedding as model input still compromises data anonymization. In this work, we propose to let each mobile device maintain a user-specific distribution to dynamically generate user embeddings, thereby breaking the one-to-one mapping between an embedding and a specific user. We further theoretically demonstrate that to prevent the cloud from tracking users via uploaded embeddings, the local distributions of different users should either be derived from a linearly dependent space to avoid identifiability or be close to each other to prevent accurate attribution. Evaluation on both public and industrial datasets using different language models reveals a remarkable improvement in accuracy from incorporating anonymous user embeddings, while preserving real-time inference requirement.
DC-CCL: Device-Cloud Collaborative Controlled Learning for Large Vision Models
Mar 18, 2023Many large vision models have been deployed on the cloud for real-time services. Meanwhile, fresh samples are continuously generated on the served mobile device. How to leverage the device-side samples to improve the cloud-side large model becomes a practical requirement, but falls into the dilemma of no raw sample up-link and no large model down-link. Specifically, the user may opt out of sharing raw samples with the cloud due to the concern of privacy or communication overhead, while the size of some large vision models far exceeds the mobile device's runtime capacity. In this work, we propose a device-cloud collaborative controlled learning framework, called DC-CCL, enabling a cloud-side large vision model that cannot be directly deployed on the mobile device to still benefit from the device-side local samples. In particular, DC-CCL vertically splits the base model into two submodels, one large submodel for learning from the cloud-side samples and the other small submodel for learning from the device-side samples and performing device-cloud knowledge fusion. Nevertheless, on-device training of the small submodel requires the output of the cloud-side large submodel to compute the desired gradients. DC-CCL thus introduces a light-weight model to mimic the large cloud-side submodel with knowledge distillation, which can be offloaded to the mobile device to control its small submodel's optimization direction. Given the decoupling nature of two submodels in collaborative learning, DC-CCL also allows the cloud to take a pre-trained model and the mobile device to take another model with a different backbone architecture.