 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Optimization over Block-Cyclic Data
Paper and Code
Feb 18, 2020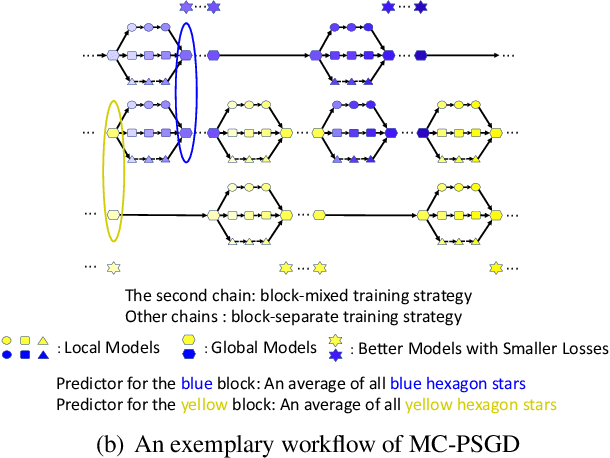
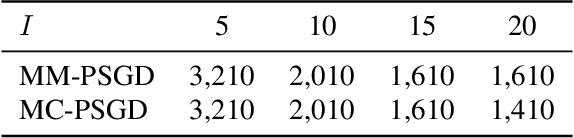
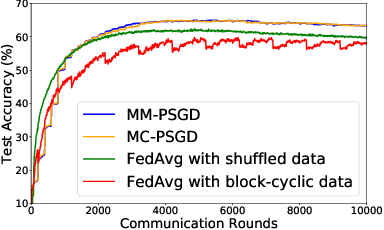
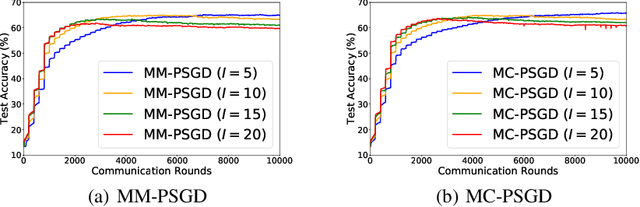
We consider practical data characteristics underlying federated learning, where unbalanced and non-i.i.d. data from clients have a block-cyclic structure: each cycle contains several blocks, and each client's training data follow block-specific and non-i.i.d. distributions. Such a data structure would introduce client and block biases during the collaborative training: the single global model would be biased towards the client or block specific data. To overcome the biases, we propose two new distributed optimization algorithms called multi-model parallel SGD (MM-PSGD) and multi-chain parallel SGD (MC-PSGD) with a convergence rate of $O(1/\sqrt{NT})$, achieving a linear speedup with respect to the total number of clients. In particular, MM-PSGD adopts the block-mixed training strategy, while MC-PSGD further adds the block-separate training strategy. Both algorithms create a specific predictor for each block by averaging and comparing the historical global models generated in this block from different cycles. We extensively evaluate our algorithms over the CIFAR-10 dataset. Evaluation results demonstrate that our algorithms significantly outperform the conventional federated averaging algorithm in terms of test accuracy, and also preserve robustness for the variance of critical parameters.