 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coordinate Matching to Structural Alignment: Rethinking Prototype Alignment in Heterogeneous Federated Learning
May 07, 2026Heterogeneous federated learning (HtFL) aims to enable collaboration among clients that differ in both data distributions and model architectures. Prototype-based methods, which communicate class-level feature centers (prototypes) instead of full model parameters, have recently shown strong potential for HtFL. Existing prototype-based HtFL methods typically reuse the MSE-based or cosine-based alignment mechanism developed for homogeneous FL when aligning client-specific representations with global prototypes. These approaches are essentially coordinate alignment, where representations of clients are forced to match the global prototypes in the embedding space in an element-wise manner. Such alignment implicitly assumes that all clients should map their representations into the feature subspace defined by the global prototypes. This assumption is reasonable in homogeneous FL, where all clients share the same feature extractor. However, it becomes problematic in HtFL, since heterogeneous feature extractors naturally induce client-specific feature subspaces, and forcing all clients to optimize within a single global subspace unnecessarily suppresses their learning capacity. We observe that coordinate alignment implicitly couples two distinct objectives: aligning inter-class semantic structure, which is directly beneficial for classification, and enforcing a shared feature basis, which is unnecessary and even harmful under model heterogeneity. Building on this insight, we design FedSAF, which shifts the alignment objective from absolute coordinates to inter-class relational structure. We demonstrate that structural alignment consistently outperforms coordinate alignment in heterogeneous settings. Experiments on multiple benchmarks show that our structural alignment outperforms state-of-the-art prototype-based HtFL methods by up to 3.52\%.
Point Cloud Registration for Fusion between SPECT MPI and CTA Images
Apr 27, 2026Clinical fusion of Single Photon Emission Computed Tomography Myocardial Perfusion Imaging (SPECT MPI) and Computed Tomography Angiography (CTA) remains limited by cross-modality misregistration and reliance on manual landmarks, which can hinder accurate ischemia localization and lesion-level functional assessment. To address this issue, we propose a registration and fusion framework for SPECT MPI and CTA that integrates functional and structural information for comprehensive cardiac evaluation. The proposed pipeline performs U-Net-based segmentation on both modalities. On SPECT MPI, only the left ventricle (LV) is extracted, and anatomical landmarks are automatically derived from characteristic LV structures. On CTA, both ventricles are segmented, and their spatial relationship is used to automatically define landmarks at the interventricular septal junction. Scale-space consistency preprocessing and landmark-driven coarse registration are applied to mitigate initial misalignment. Based on this initialization, multiple fine registration methods are evaluated on LV epicardial surface point clouds, including ICP, SICP, CPD, CluReg, FFD, and BCPD-plus-plus. The resulting transformations are then propagated to voxel-level resampling for high-precision SPECT-CTA fusion. In a retrospective cohort of 60 patients, the proposed framework preserved sub-millimeter coronary detail from CTA while accurately overlaying quantitative SPECT perfusion. Among the evaluated methods, BCPD-plus-plus achieved the highest accuracy with a mean point cloud distance of 1.7 mm. By combining robust initialization, comparative fine registration, and voxel-level fusion, the proposed approach provides a practical solution for myocardial ischemia localization and functional evaluation of coronary lesions, while remaining independent of any specific fine registration algorithm.
Learning to Seek Help: Dynamic Collaboration Between Small and Large Language Models
Apr 20, 2026Large language models (LLMs) offer strong capabilities but raise cost and privacy concerns, whereas small language models (SLMs) facilitate efficient and private local inference yet suffer from limited capacity. To synergize the complementary strengths, we introduce a dynamic collaboration framework, where an SLM learns to proactively decide how to request an LLM during multi-step reasoning, while the LLM provides adaptive feedback instead of acting as a passive tool. We further systematically investigate how collaboration strategies are shaped by SLM and LLM capabilities as well as efficiency and privacy constraints. Evaluation results reveal a distinct scaling effect: stronger SLMs become more self-reliant, while stronger LLMs enable fewer and more informative interactions. In addition, the learned dynamic collaboration strategies significantly outperform static pipelines and standalone inference, and transfer robustly to unseen LLMs.
From Myopic Selection to Long-Horizon Awareness: Sequential LLM Routing for Multi-Turn Dialogue
Apr 14, 2026Multi-turn dialogue is the predominant form of interaction with large language models (LLMs). While LLM routing is effective in single-turn settings, existing methods fail to maximize cumulative performance in multi-turn dialogue due to interaction dynamics and delayed rewards. To address this challenge, we move from myopic, single-turn selection to long-horizon sequential routing for multi-turn dialogue. Accordingly, we propose DialRouter, which first performs MCTS to explore dialogue branches induced by different LLM selections and collect trajectories with high cumulative rewards. DialRouter then learns a lightweight routing policy from search-derived data, augmented with retrieval-based future state approximation, enabling multi-turn routing without online search. Experiments on both open-domain and domain-specific dialogue tasks across diverse candidate sets of both open-source and closed-source LLMs demonstrate that DialRouter significantly outperforms single LLMs and existing routing baselines in task success rate, while achieving a superior performance-cost trade-off when combined with a cost-aware reward.
Learning to Optimize Job Shop Scheduling Under Structural Uncertainty
Jan 29, 2026The Job-Shop Scheduling Problem (JSSP), under various forms of manufacturing uncertainty, has recently attracted considerable research attention. Most existing studies focus on parameter uncertainty, such as variable processing times, and typically adopt the actor-critic framework. In this paper, we explore a different but prevalent form of uncertainty in JSSP: structural uncertainty. Structural uncertainty arises when a job may follow one of several routing paths, and the selection is determined not by policy, but by situational factors (e.g., the quality of intermediate products) that cannot be known in advance. Existing methods struggle to address this challenge due to incorrect credit assignment: a high-quality action may be unfairly penalized if it is followed by a time-consuming path. To address this problem, we propose a novel method named UP-AAC. In contrast to conventional actor-critic methods, UP-AAC employs an asymmetric architecture. While its actor receives a standard stochastic state, the critic is crucially provided with a deterministic state reconstructed in hindsight. This design allows the critic to learn a more accurate value function, which in turn provides a lower-variance policy gradient to the actor, leading to more stable learning. In addition, we design an attention-based Uncertainty Perception Model (UPM) to enhance the actor's scheduling decisions. Extensive experiments demonstrate that our method outperforms existing approaches in reducing makespan on benchmark instances.
Scalable Mixed-Integer Optimization with Neural Constraints via Dual Decomposition
Nov 12, 2025Embedding deep neural networks (NNs) into mixed-integer programs (MIPs) is attractive for decision making with learned constraints, yet state-of-the-art monolithic linearisations blow up in size and quickly become intractable. In this paper, we introduce a novel dual-decomposition framework that relaxes the single coupling equality u=x with an augmented Lagrange multiplier and splits the problem into a vanilla MIP and a constrained NN block. Each part is tackled by the solver that suits it best-branch and cut for the MIP subproblem, first-order optimisation for the NN subproblem-so the model remains modular, the number of integer variables never grows with network depth, and the per-iteration cost scales only linearly with the NN size. On the public \textsc{SurrogateLIB} benchmark, our method proves \textbf{scalable}, \textbf{modular}, and \textbf{adaptable}: it runs \(120\times\) faster than an exact Big-M formulation on the largest test case; the NN sub-solver can be swapped from a log-barrier interior step to a projected-gradient routine with no code changes and identical objective value; and swapping the MLP for an LSTM backbone still completes the full optimisation in 47s without any bespoke adaptation.
MVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Automated Privacy Information Annotation in Large Language Model Interactions
May 27, 2025Users interacting with large language models (LLMs) under their real identifiers often unknowingly risk disclosing private information. Automatically notifying users whether their queries leak privacy and which phrases leak what private information has therefore become a practical need. Existing privacy detection methods, however, were designed for different objectives and application scenarios, typically tagging personally identifiable information (PII) in anonymous content. In this work, to support the development and evaluation of privacy detection models for LLM interactions that are deployable on local user devices, we construct a large-scale multilingual dataset with 249K user queries and 154K annotated privacy phrases. In particular, we build an automated privacy annotation pipeline with cloud-based strong LLMs to automatically extract privacy phrases from dialogue datasets and annotate leaked information. We also design evaluation metrics at the levels of privacy leakage, extracted privacy phrase, and privacy information. We further establish baseline methods using light-weight LLMs with both tuning-free and tuning-based methods, and report a comprehensive evaluation of their performance. Evaluation results reveal a gap between current performance and the requirements of real-world LLM applications, motivating future research into more effective local privacy detection methods grounded in our dataset.
Enhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Mar 16, 2025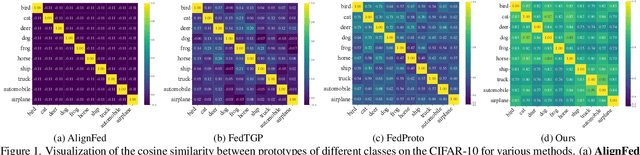
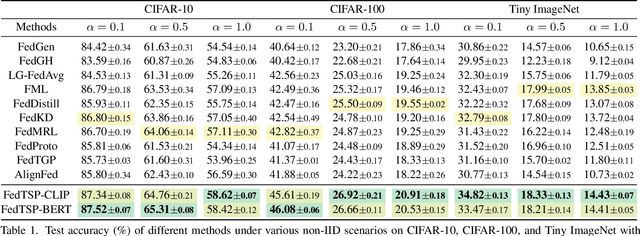
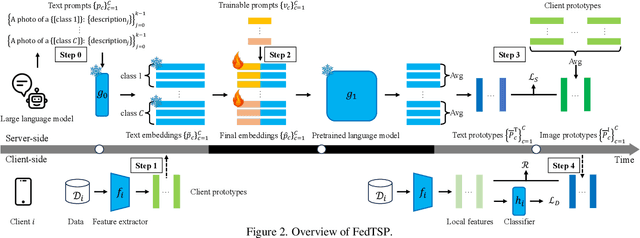
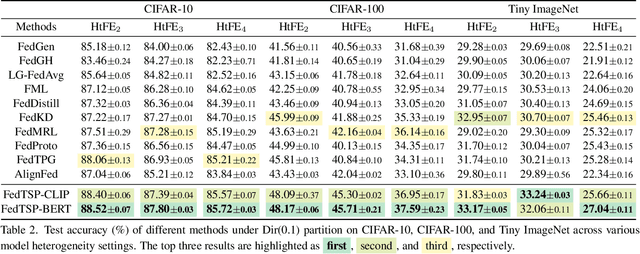
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.
The Other Side of the Coin: Unveiling the Downsides of Model Aggregation in Federated Learning from a Layer-peeled Perspective
Feb 05, 2025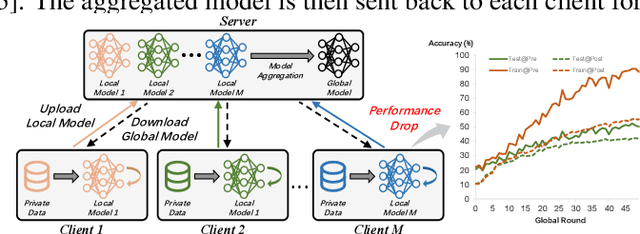
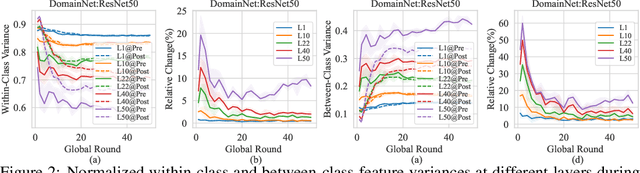
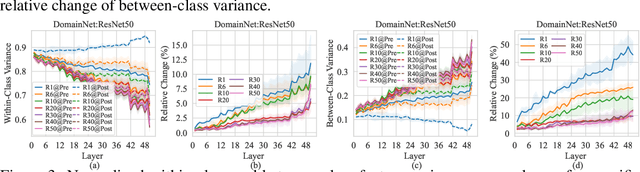
In federated learning (FL), model aggregation is a critical step by which multiple clients share their knowledge with one another. However, it is also widely recognized that the aggregated model, when sent back to each client, performs poorly on local data until after several rounds of local training. This temporary performance drop can potentially slow down the convergence of the FL model. Most research in FL regards this performance drop as an inherent cost of knowledge sharing among clients and does not give it special attention. While some studies directly focus on designing techniques to alleviate the issue, an in-depth investigation of the reasons behind this performance drop has yet to be conducted.To address this gap, we conduct a layer-peeled analysis of model aggregation across various datasets and model architectures. Our findings reveal that the performance drop can be attributed to two major consequences of the aggregation process: (1) it disrupts feature variability suppression in deep neural networks (DNNs), and (2) it weakens the coupling between features and subsequent parameters.Based on these findings, we propose several simple yet effective strategies to mitigate the negative impacts of model aggregation while still enjoying the benefit it brings. To the best of our knowledge, our work is the first to conduct a layer-peeled analysis of model aggregation, potentially paving the way for the development of more effective FL algorithms.