 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Other Side of the Coin: Unveiling the Downsides of Model Aggregation in Federated Learning from a Layer-peeled Perspective
Paper and Code
Feb 05, 2025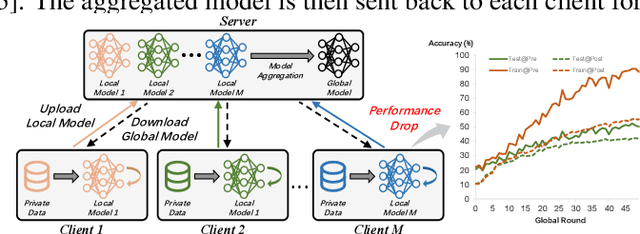
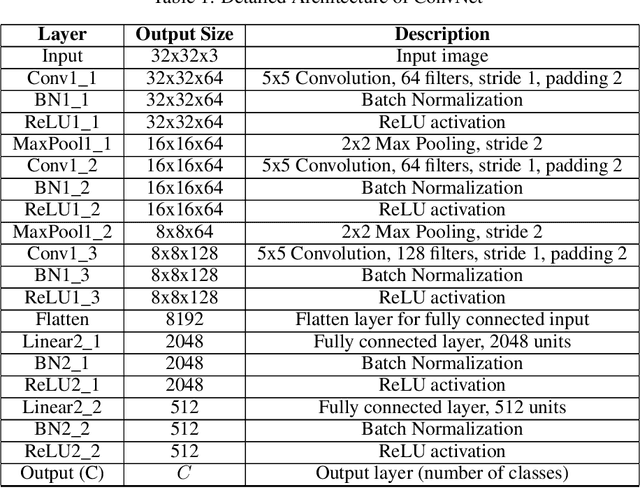
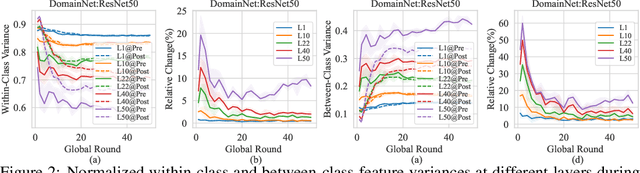
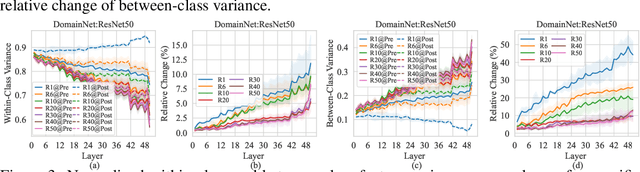
In federated learning (FL), model aggregation is a critical step by which multiple clients share their knowledge with one another. However, it is also widely recognized that the aggregated model, when sent back to each client, performs poorly on local data until after several rounds of local training. This temporary performance drop can potentially slow down the convergence of the FL model. Most research in FL regards this performance drop as an inherent cost of knowledge sharing among clients and does not give it special attention. While some studies directly focus on designing techniques to alleviate the issue, an in-depth investigation of the reasons behind this performance drop has yet to be conducted.To address this gap, we conduct a layer-peeled analysis of model aggregation across various datasets and model architectures. Our findings reveal that the performance drop can be attributed to two major consequences of the aggregation process: (1) it disrupts feature variability suppression in deep neural networks (DNNs), and (2) it weakens the coupling between features and subsequent parameters.Based on these findings, we propose several simple yet effective strategies to mitigate the negative impacts of model aggregation while still enjoying the benefit it brings. To the best of our knowledge, our work is the first to conduct a layer-peeled analysis of model aggregation, potentially paving the way for the development of more effective FL algorithms.