 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Coverage via Constraint Active Search
Feb 17, 2026In this paper, we formulate the new multi-objective coverage (MOC) problem where our goal is to identify a small set of representative samples whose predicted outcomes broadly cover the feasible multi-objective space. This problem is of great importance in many critical real-world applications, e.g., drug discovery and materials design, as this representative set can be evaluated much faster than the whole feasible set, thus significantly accelerating the scientific discovery process. Existing works cannot be directly applied as they either focus on sample space coverage or multi-objective optimization that targets the Pareto front. However, chemically diverse samples often yield identical objective profiles, and safety constraints are usually defined on the objectives. To solve this MOC problem, we propose a novel search algorithm, MOC-CAS, which employs an upper confidence bound-based acquisition function to select optimistic samples guided by Gaussian process posterior predictions. For enabling efficient optimization, we develop a smoothed relaxation of the hard feasibility test and derive an approximate optimizer. Compared to the competitive baselines, we show that our MOC-CAS empirically achieves superior performances across large-scale protein-target datasets for SARS-CoV-2 and cancer, each assessed on five objectives derived from SMILES-based features.
Learning to Optimize Job Shop Scheduling Under Structural Uncertainty
Jan 29, 2026The Job-Shop Scheduling Problem (JSSP), under various forms of manufacturing uncertainty, has recently attracted considerable research attention. Most existing studies focus on parameter uncertainty, such as variable processing times, and typically adopt the actor-critic framework. In this paper, we explore a different but prevalent form of uncertainty in JSSP: structural uncertainty. Structural uncertainty arises when a job may follow one of several routing paths, and the selection is determined not by policy, but by situational factors (e.g., the quality of intermediate products) that cannot be known in advance. Existing methods struggle to address this challenge due to incorrect credit assignment: a high-quality action may be unfairly penalized if it is followed by a time-consuming path. To address this problem, we propose a novel method named UP-AAC. In contrast to conventional actor-critic methods, UP-AAC employs an asymmetric architecture. While its actor receives a standard stochastic state, the critic is crucially provided with a deterministic state reconstructed in hindsight. This design allows the critic to learn a more accurate value function, which in turn provides a lower-variance policy gradient to the actor, leading to more stable learning. In addition, we design an attention-based Uncertainty Perception Model (UPM) to enhance the actor's scheduling decisions. Extensive experiments demonstrate that our method outperforms existing approaches in reducing makespan on benchmark instances.
Regime-Adaptive Bayesian Optimization via Dirichlet Process Mixtures of Gaussian Processes
Jan 27, 2026Standard Bayesian Optimization (BO) assumes uniform smoothness across the search space an assumption violated in multi-regime problems such as molecular conformation search through distinct energy basins or drug discovery across heterogeneous molecular scaffolds. A single GP either oversmooths sharp transitions or hallucinates noise in smooth regions, yielding miscalibrated uncertainty. We propose RAMBO, a Dirichlet Process Mixture of Gaussian Processes that automatically discovers latent regimes during optimization, each modeled by an independent GP with locally-optimized hyperparameters. We derive collapsed Gibbs sampling that analytically marginalizes latent functions for efficient inference, and introduce adaptive concentration parameter scheduling for coarse-to-fine regime discovery. Our acquisition functions decompose uncertainty into intra-regime and inter-regime components. Experiments on synthetic benchmarks and real-world applications, including molecular conformer optimization, virtual screening for drug discovery, and fusion reactor design, demonstrate consistent improvements over state-of-the-art baselines on multi-regime objectives.
Monte Carlo Tree Diffusion with Multiple Experts for Protein Design
Sep 19, 2025The goal of protein design is to generate amino acid sequences that fold into functional structures with desired properties. Prior methods combining autoregressive language models with Monte Carlo Tree Search (MCTS) struggle with long-range dependencies and suffer from an impractically large search space. We propose MCTD-ME, Monte Carlo Tree Diffusion with Multiple Experts, which integrates masked diffusion models with tree search to enable multi-token planning and efficient exploration. Unlike autoregressive planners, MCTD-ME uses biophysical-fidelity-enhanced diffusion denoising as the rollout engine, jointly revising multiple positions and scaling to large sequence spaces. It further leverages experts of varying capacities to enrich exploration, guided by a pLDDT-based masking schedule that targets low-confidence regions while preserving reliable residues. We propose a novel multi-expert selection rule (PH-UCT-ME) extends predictive-entropy UCT to expert ensembles. On the inverse folding task (CAMEO and PDB benchmarks), MCTD-ME outperforms single-expert and unguided baselines in both sequence recovery (AAR) and structural similarity (scTM), with gains increasing for longer proteins and benefiting from multi-expert guidance. More generally, the framework is model-agnostic and applicable beyond inverse folding, including de novo protein engineering and multi-objective molecular generation.
WGLE:Backdoor-free and Multi-bit Black-box Watermarking for Graph Neural Networks
Jun 10, 2025Graph Neural Networks (GNNs) are increasingly deployed in graph-related applications, making ownership verification critical to protect their intellectual property against model theft. Fingerprinting and black-box watermarking are two main methods. However, the former relies on determining model similarity, which is computationally expensive and prone to ownership collisions after model post-processing such as model pruning or fine-tuning. The latter embeds backdoors, exposing watermarked models to the risk of backdoor attacks. Moreover, both methods enable ownership verification but do not convey additional information. As a result, each distributed model requires a unique trigger graph, and all trigger graphs must be used to query the suspect model during verification. Multiple queries increase the financial cost and the risk of detection. To address these challenges, this paper proposes WGLE, a novel black-box watermarking paradigm for GNNs that enables embedding the multi-bit string as the ownership information without using backdoors. WGLE builds on a key insight we term Layer-wise Distance Difference on an Edge (LDDE), which quantifies the difference between the feature distance and the prediction distance of two connected nodes. By predefining positive or negative LDDE values for multiple selected edges, WGLE embeds the watermark encoding the intended information without introducing incorrect mappings that compromise the primary task. WGLE is evaluated on six public datasets and six mainstream GNN architectures along with state-of-the-art methods. The results show that WGLE achieves 100% ownership verification accuracy, an average fidelity degradation of 0.85%, comparable robustness against potential attacks, and low embedding overhead. The code is available in the repository.
Bidirectional Hierarchical Protein Multi-Modal Representation Learning
Apr 07, 2025Protein representation learning is critical for numerous biological tasks. Recently, large transformer-based protein language models (pLMs) pretrained on large scale protein sequences have demonstrated significant success in sequence-based tasks. However, pLMs lack structural information. Conversely, graph neural networks (GNNs) designed to leverage 3D structural information have shown promising generalization in protein-related prediction tasks, but their effectiveness is often constrained by the scarcity of labeled structural data. Recognizing that sequence and structural representations are complementary perspectives of the same protein entity, we propose a multimodal bidirectional hierarchical fusion framework to effectively merge these modalities. Our framework employs attention and gating mechanisms to enable effective interaction between pLMs-generated sequential representations and GNN-extracted structural features, improving information exchange and enhancement across layers of the neural network. Based on the framework, we further introduce local Bi-Hierarchical Fusion with gating and global Bi-Hierarchical Fusion with multihead self-attention approaches. Through extensive experiments on a diverse set of protein-related tasks, our method demonstrates consistent improvements over strong baselines and existing fusion techniques in a variety of protein representation learning benchmarks, including react (enzyme/EC classification), model quality assessment (MQA), protein-ligand binding affinity prediction (LBA), protein-protein binding site prediction (PPBS), and B cell epitopes prediction (BCEs). Our method establishes a new state-of-the-art for multimodal protein representation learning, emphasizing the efficacy of BIHIERARCHICAL FUSION in bridging sequence and structural modalities.
Enhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Mar 16, 2025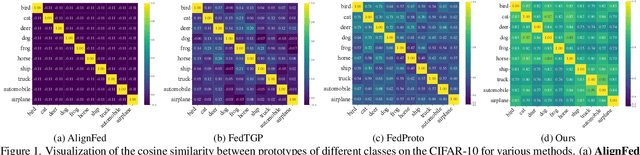
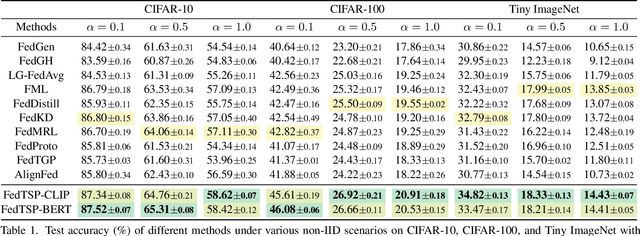
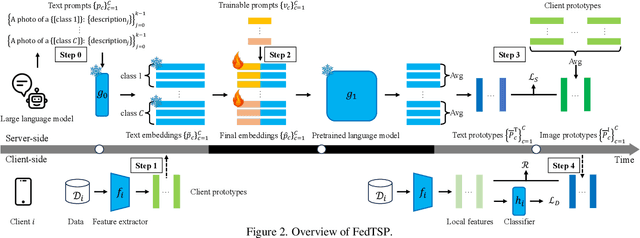
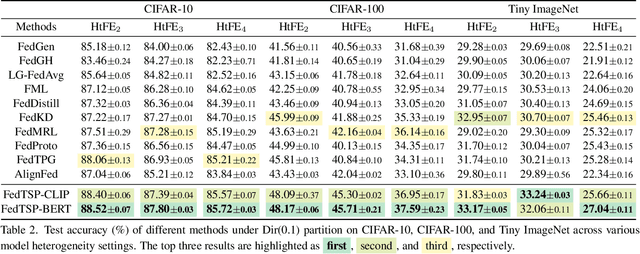
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.
Active Advantage-Aligned Online Reinforcement Learning with Offline Data
Feb 11, 2025Online reinforcement learning (RL) enhances policies through direct interactions with the environment, but faces challenges related to sample efficiency. In contrast, offline RL leverages extensive pre-collected data to learn policies, but often produces suboptimal results due to limited data coverage. Recent efforts have sought to integrate offline and online RL in order to harness the advantages of both approaches. However, effectively combining online and offline RL remains challenging due to issues that include catastrophic forgetting, lack of robustness and sample efficiency. In an effort to address these challenges, we introduce A3 RL , a novel method that actively selects data from combined online and offline sources to optimize policy improvement. We provide theoretical guarantee that validates the effectiveness our active sampling strategy and conduct thorough empirical experiments showing that our method outperforms existing state-of-the-art online RL techniques that utilize offline data. Our code will be publicly available at: https://github.com/xuefeng-cs/A3RL.
DrugImproverGPT: A Large Language Model for Drug Optimization with Fine-Tuning via Structured Policy Optimization
Feb 11, 2025Finetuning a Large Language Model (LLM) is crucial for generating results towards specific objectives. This research delves into the realm of drug optimization and introduce a novel reinforcement learning algorithm to finetune a drug optimization LLM-based generative model, enhancing the original drug across target objectives, while retains the beneficial chemical properties of the original drug. This work is comprised of two primary components: (1) DrugImprover: A framework tailored for improving robustness and efficiency in drug optimization. It includes a LLM designed for drug optimization and a novel Structured Policy Optimization (SPO) algorithm, which is theoretically grounded. This algorithm offers a unique perspective for fine-tuning the LLM-based generative model by aligning the improvement of the generated molecule with the input molecule under desired objectives. (2) A dataset of 1 million compounds, each with OEDOCK docking scores on 5 human proteins associated with cancer cells and 24 binding sites from SARS-CoV-2 virus. We conduct a comprehensive evaluation of SPO and demonstrate its effectiveness in improving the original drug across target properties. Our code and dataset will be publicly available at: https://github.com/xuefeng-cs/DrugImproverGPT.
ScaffoldGPT: A Scaffold-based Large Language Model for Drug Improvement
Feb 09, 2025Drug optimization has become increasingly crucial in light of fast-mutating virus strains and drug-resistant cancer cells. Nevertheless, it remains challenging as it necessitates retaining the beneficial properties of the original drug while simultaneously enhancing desired attributes beyond its scope. In this work, we aim to tackle this challenge by introducing ScaffoldGPT, a novel Large Language Model (LLM) designed for drug optimization based on molecular scaffolds. Our work comprises three key components: (1) A three-stage drug optimization approach that integrates pretraining, finetuning, and decoding optimization. (2) A uniquely designed two-phase incremental training approach for pre-training the drug optimization LLM-based generator on molecule scaffold with enhanced performance. (3) A token-level decoding optimization strategy, TOP-N, that enabling controlled, reward-guided generation using pretrained/finetuned LLMs. Finally, by conducting a comprehensive evaluation on COVID and cancer benchmarks, we demonstrate that SCAFFOLDGPT outperforms the competing baselines in drug optimization benchmarks, while excelling in preserving the original functional scaffold and enhancing desired properties.