 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coordinate Matching to Structural Alignment: Rethinking Prototype Alignment in Heterogeneous Federated Learning
May 07, 2026Heterogeneous federated learning (HtFL) aims to enable collaboration among clients that differ in both data distributions and model architectures. Prototype-based methods, which communicate class-level feature centers (prototypes) instead of full model parameters, have recently shown strong potential for HtFL. Existing prototype-based HtFL methods typically reuse the MSE-based or cosine-based alignment mechanism developed for homogeneous FL when aligning client-specific representations with global prototypes. These approaches are essentially coordinate alignment, where representations of clients are forced to match the global prototypes in the embedding space in an element-wise manner. Such alignment implicitly assumes that all clients should map their representations into the feature subspace defined by the global prototypes. This assumption is reasonable in homogeneous FL, where all clients share the same feature extractor. However, it becomes problematic in HtFL, since heterogeneous feature extractors naturally induce client-specific feature subspaces, and forcing all clients to optimize within a single global subspace unnecessarily suppresses their learning capacity. We observe that coordinate alignment implicitly couples two distinct objectives: aligning inter-class semantic structure, which is directly beneficial for classification, and enforcing a shared feature basis, which is unnecessary and even harmful under model heterogeneity. Building on this insight, we design FedSAF, which shifts the alignment objective from absolute coordinates to inter-class relational structure. We demonstrate that structural alignment consistently outperforms coordinate alignment in heterogeneous settings. Experiments on multiple benchmarks show that our structural alignment outperforms state-of-the-art prototype-based HtFL methods by up to 3.52\%.
HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark
Jun 04, 2025



As AI evolves, collaboration among heterogeneous models helps overcome data scarcity by enabling knowledge transfer across institutions and devices. Traditional Federated Learning (FL) only supports homogeneous models, limiting collaboration among clients with heterogeneous model architectures. To address this, Heterogeneous Federated Learning (HtFL) methods are developed to enable collaboration across diverse heterogeneous models while tackling the data heterogeneity issue at the same time. However, a comprehensive benchmark for standardized evaluation and analysis of the rapidly growing HtFL methods is lacking. Firstly, the highly varied datasets, model heterogeneity scenarios, and different method implementations become hurdles to making easy and fair comparisons among HtFL methods. Secondly, the effectiveness and robustness of HtFL methods are under-explored in various scenarios, such as the medical domain and sensor signal modality. To fill this gap, we introduce the first Heterogeneous Federated Learning Library (HtFLlib), an easy-to-use and extensible framework that integrates multiple datasets and model heterogeneity scenarios, offering a robust benchmark for research and practical applications. Specifically, HtFLlib integrates (1) 12 datasets spanning various domains, modalities, and data heterogeneity scenarios; (2) 40 model architectures, ranging from small to large, across three modalities; (3) a modularized and easy-to-extend HtFL codebase with implementations of 10 representative HtFL methods; and (4) systematic evaluations in terms of accuracy, convergence, computation costs, and communication costs. We emphasize the advantages and potential of state-of-the-art HtFL methods and hope that HtFLlib will catalyze advancing HtFL research and enable its broader applications. The code is released at https://github.com/TsingZ0/HtFLlib.
Enhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Mar 16, 2025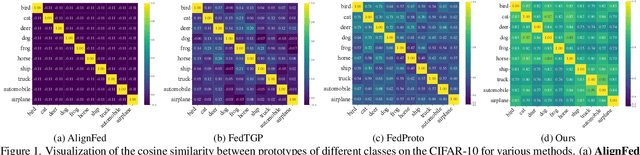
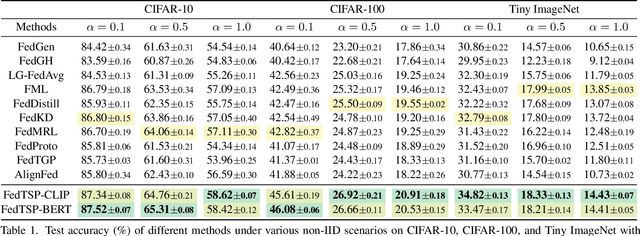
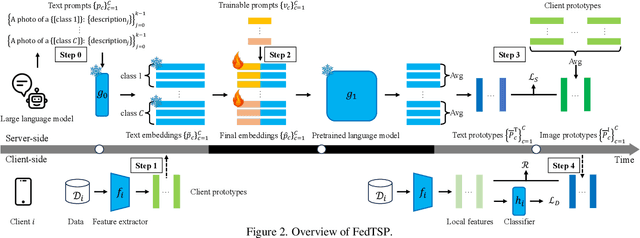
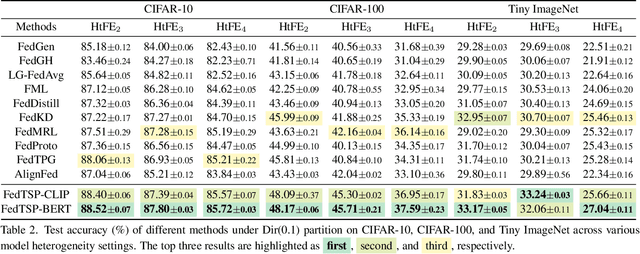
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.
The Other Side of the Coin: Unveiling the Downsides of Model Aggregation in Federated Learning from a Layer-peeled Perspective
Feb 05, 2025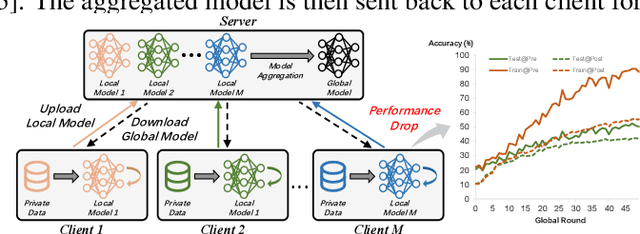
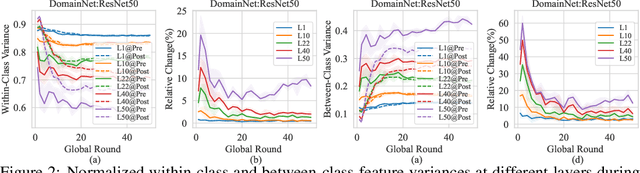
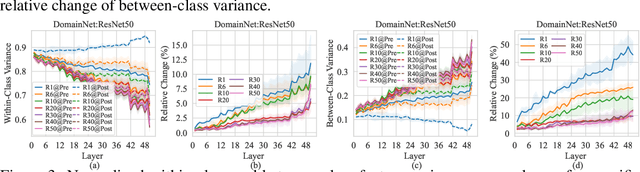
In federated learning (FL), model aggregation is a critical step by which multiple clients share their knowledge with one another. However, it is also widely recognized that the aggregated model, when sent back to each client, performs poorly on local data until after several rounds of local training. This temporary performance drop can potentially slow down the convergence of the FL model. Most research in FL regards this performance drop as an inherent cost of knowledge sharing among clients and does not give it special attention. While some studies directly focus on designing techniques to alleviate the issue, an in-depth investigation of the reasons behind this performance drop has yet to be conducted.To address this gap, we conduct a layer-peeled analysis of model aggregation across various datasets and model architectures. Our findings reveal that the performance drop can be attributed to two major consequences of the aggregation process: (1) it disrupts feature variability suppression in deep neural networks (DNNs), and (2) it weakens the coupling between features and subsequent parameters.Based on these findings, we propose several simple yet effective strategies to mitigate the negative impacts of model aggregation while still enjoying the benefit it brings. To the best of our knowledge, our work is the first to conduct a layer-peeled analysis of model aggregation, potentially paving the way for the development of more effective FL algorithms.
DualFed: Enjoying both Generalization and Personalization in Federated Learning via Hierachical Representations
Jul 25, 2024



In personalized federated learning (PFL), it is widely recognized that achieving both high model generalization and effective personalization poses a significant challenge due to their conflicting nature. As a result, existing PFL methods can only manage a trade-off between these two objectives. This raises an interesting question: Is it feasible to develop a model capable of achieving both objectives simultaneously? Our paper presents an affirmative answer, and the key lies in the observation that deep models inherently exhibit hierarchical architectures, which produce representations with various levels of generalization and personalization at different stages. A straightforward approach stemming from this observation is to select multiple representations from these layers and combine them to concurrently achieve generalization and personalization. However, the number of candidate representations is commonly huge, which makes this method infeasible due to high computational costs.To address this problem, we propose DualFed, a new method that can directly yield dual representations correspond to generalization and personalization respectively, thereby simplifying the optimization task. Specifically, DualFed inserts a personalized projection network between the encoder and classifier. The pre-projection representations are able to capture generalized information shareable across clients, and the post-projection representations are effective to capture task-specific information on local clients. This design minimizes the mutual interference between generalization and personalization, thereby achieving a win-win situation. Extensive experiments show that DualFed can outperform other FL methods. Code is available at https://github.com/GuogangZhu/DualFed.
Tackling Feature-Classifier Mismatch in Federated Learning via Prompt-Driven Feature Transformation
Jul 23, 2024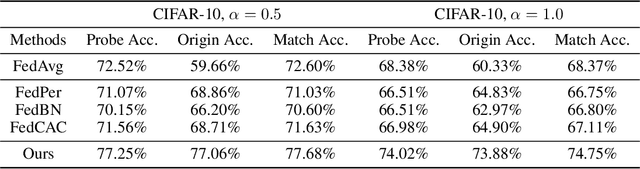
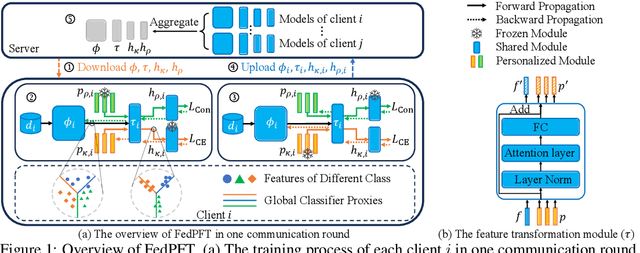
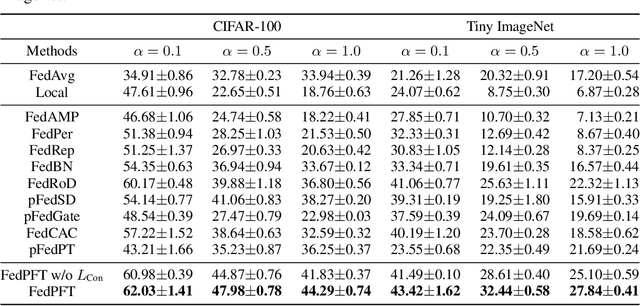
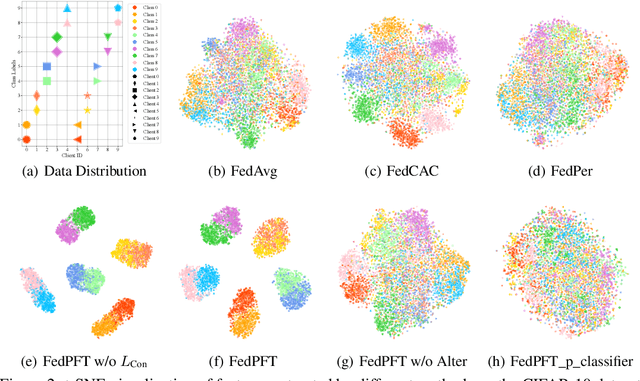
In traditional Federated Learning approaches like FedAvg, the global model underperforms when faced with data heterogeneity. Personalized Federated Learning (PFL) enables clients to train personalized models to fit their local data distribution better. However, we surprisingly find that the feature extractor in FedAvg is superior to those in most PFL methods. More interestingly, by applying a linear transformation on local features extracted by the feature extractor to align with the classifier, FedAvg can surpass the majority of PFL methods. This suggests that the primary cause of FedAvg's inadequate performance stems from the mismatch between the locally extracted features and the classifier. While current PFL methods mitigate this issue to some extent, their designs compromise the quality of the feature extractor, thus limiting the full potential of PFL. In this paper, we propose a new PFL framework called FedPFT to address the mismatch problem while enhancing the quality of the feature extractor. FedPFT integrates a feature transformation module, driven by personalized prompts, between the global feature extractor and classifier. In each round, clients first train prompts to transform local features to match the global classifier, followed by training model parameters. This approach can also align the training objectives of clients, reducing the impact of data heterogeneity on model collaboration. Moreover, FedPFT's feature transformation module is highly scalable, allowing for the use of different prompts to tailor local features to various tasks. Leveraging this, we introduce a collaborative contrastive learning task to further refine feature extractor quality. Our experiments demonstrate that FedPFT outperforms state-of-the-art methods by up to 7.08%.
The Diversity Bonus: Learning from Dissimilar Distributed Clients in Personalized Federated Learning
Jul 22, 2024



Personalized Federated Learning (PFL) is a commonly used framework that allows clients to collaboratively train their personalized models. PFL is particularly useful for handling situations where data from different clients are not independent and identically distributed (non-IID). Previous research in PFL implicitly assumes that clients can gain more benefits from those with similar data distributions. Correspondingly, methods such as personalized weight aggregation are developed to assign higher weights to similar clients during training. We pose a question: can a client benefit from other clients with dissimilar data distributions and if so, how? This question is particularly relevant in scenarios with a high degree of non-IID, where clients have widely different data distributions, and learning from only similar clients will lose knowledge from many other clients. We note that when dealing with clients with similar data distributions, methods such as personalized weight aggregation tend to enforce their models to be close in the parameter space. It is reasonable to conjecture that a client can benefit from dissimilar clients if we allow their models to depart from each other. Based on this idea, we propose DiversiFed which allows each client to learn from clients with diversified data distribution in personalized federated learning. DiversiFed pushes personalized models of clients with dissimilar data distributions apart in the parameter space while pulling together those with similar distributions. In addition, to achieve the above effect without using prior knowledge of data distribution, we design a loss function that leverages the model similarity to determine the degree of attraction and repulsion between any two models. Experiments on several datasets show that DiversiFed can benefit from dissimilar clients and thus outperform the state-of-the-art methods.
Decoupling General and Personalized Knowledge in Federated Learning via Additive and Low-Rank Decomposition
Jun 28, 2024



To address data heterogeneity, the key strategy of Personalized Federated Learning (PFL) is to decouple general knowledge (shared among clients) and client-specific knowledge, as the latter can have a negative impact on collaboration if not removed. Existing PFL methods primarily adopt a parameter partitioning approach, where the parameters of a model are designated as one of two types: parameters shared with other clients to extract general knowledge and parameters retained locally to learn client-specific knowledge. However, as these two types of parameters are put together like a jigsaw puzzle into a single model during the training process, each parameter may simultaneously absorb both general and client-specific knowledge, thus struggling to separate the two types of knowledge effectively. In this paper, we introduce FedDecomp, a simple but effective PFL paradigm that employs parameter additive decomposition to address this issue. Instead of assigning each parameter of a model as either a shared or personalized one, FedDecomp decomposes each parameter into the sum of two parameters: a shared one and a personalized one, thus achieving a more thorough decoupling of shared and personalized knowledge compared to the parameter partitioning method. In addition, as we find that retaining local knowledge of specific clients requires much lower model capacity compared with general knowledge across all clients, we let the matrix containing personalized parameters be low rank during the training process. Moreover, a new alternating training strategy is proposed to further improve the performance. Experimental results across multiple datasets and varying degrees of data heterogeneity demonstrate that FedDecomp outperforms state-of-the-art methods up to 4.9\%.
Estimating before Debiasing: A Bayesian Approach to Detaching Prior Bias in Federated Semi-Supervised Learning
May 30, 2024



Federated Semi-Supervised Learning (FSSL) leverages both labeled and unlabeled data on clients to collaboratively train a model.In FSSL, the heterogeneous data can introduce prediction bias into the model, causing the model's prediction to skew towards some certain classes. Existing FSSL methods primarily tackle this issue by enhancing consistency in model parameters or outputs. However, as the models themselves are biased, merely constraining their consistency is not sufficient to alleviate prediction bias. In this paper, we explore this bias from a Bayesian perspective and demonstrate that it principally originates from label prior bias within the training data. Building upon this insight, we propose a debiasing method for FSSL named FedDB. FedDB utilizes the Average Prediction Probability of Unlabeled Data (APP-U) to approximate the biased prior.During local training, FedDB employs APP-U to refine pseudo-labeling through Bayes' theorem, thereby significantly reducing the label prior bias. Concurrently, during the model aggregation, FedDB uses APP-U from participating clients to formulate unbiased aggregate weights, thereby effectively diminishing bias in the global model. Experimental results show that FedDB can surpass existing FSSL methods. The code is available at https://github.com/GuogangZhu/FedDB.
Tackling Noisy Labels with Network Parameter Additive Decomposition
Mar 20, 2024



Given data with noisy labels, over-parameterized deep networks suffer overfitting mislabeled data, resulting in poor generalization. The memorization effect of deep networks shows that although the networks have the ability to memorize all noisy data, they would first memorize clean training data, and then gradually memorize mislabeled training data. A simple and effective method that exploits the memorization effect to combat noisy labels is early stopping. However, early stopping cannot distinguish the memorization of clean data and mislabeled data, resulting in the network still inevitably overfitting mislabeled data in the early training stage.In this paper, to decouple the memorization of clean data and mislabeled data, and further reduce the side effect of mislabeled data, we perform additive decomposition on network parameters. Namely, all parameters are additively decomposed into two groups, i.e., parameters $\mathbf{w}$ are decomposed as $\mathbf{w}=\bm{\sigma}+\bm{\gamma}$. Afterward, the parameters $\bm{\sigma}$ are considered to memorize clean data, while the parameters $\bm{\gamma}$ are considered to memorize mislabeled data. Benefiting from the memorization effect, the updates of the parameters $\bm{\sigma}$ are encouraged to fully memorize clean data in early training, and then discouraged with the increase of training epochs to reduce interference of mislabeled data. The updates of the parameters $\bm{\gamma}$ are the opposite. In testing, only the parameters $\bm{\sigma}$ are employed to enhance generalization. Extensive experiments on both simulated and real-world benchmarks confirm the superior performance of our method.