 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP-LLM: Generating CAD STEP Models from Natural Language with Large Language Models
Jan 19, 2026Computer-aided design (CAD) is vital to modern manufacturing, yet model creation remains labor-intensive and expertise-heavy. To enable non-experts to translate intuitive design intent into manufacturable artifacts, recent large language models-based text-to-CAD efforts focus on command sequences or script-based formats like CadQuery. However, these formats are kernel-dependent and lack universality for manufacturing. In contrast, the Standard for the Exchange of Product Data (STEP, ISO 10303) file is a widely adopted, neutral boundary representation (B-rep) format directly compatible with manufacturing, but its graph-structured, cross-referenced nature poses unique challenges for auto-regressive LLMs. To address this, we curate a dataset of ~40K STEP-caption pairs and introduce novel preprocessing tailored for the graph-structured format of STEP, including a depth-first search-based reserialization that linearizes cross-references while preserving locality and chain-of-thought(CoT)-style structural annotations that guide global coherence. We integrate retrieval-augmented generation to ground predictions in relevant examples for supervised fine-tuning, and refine generation quality through reinforcement learning with a specific Chamfer Distance-based geometric reward. Experiments demonstrate consistent gains of our STEP-LLM in geometric fidelity over the Text2CAD baseline, with improvements arising from multiple stages of our framework: the RAG module substantially enhances completeness and renderability, the DFS-based reserialization strengthens overall accuracy, and the RL further reduces geometric discrepancy. Both metrics and visual comparisons confirm that STEP-LLM generates shapes with higher fidelity than Text2CAD. These results show the feasibility of LLM-driven STEP model generation from natural language, showing its potential to democratize CAD design for manufacturing.
Machine Learning-Driven Creep Law Discovery Across Alloy Compositional Space
Jan 13, 2026Hihg-temperature creep characterization of structural alloys traditionally relies on serial uniaxial tests, which are highly inefficient for exploring the large search space of alloy compositions and for material discovery. Here, we introduce a machine-learning-assisted, high-throughput framework for creep law identification based on a dimple array bulge instrument (DABI) configuration, which enables parallel creep testing of 25 dimples, each fabricated from a different alloy, in a single experiment. Full-field surface displacements of dimples undergoing time-dependent creep-induced bulging under inert gas pressure are measured by 3D digital image correlation. We train a recurrent neural network (RNN) as a surrogate model, mapping creep parameters and loading conditions to the time-dependent deformation response of DABI. Coupling this surrogate with a particle swarm optimization scheme enables rapid and global inverse identification with sparsity regularization of creep parameters from experiment displacement-time histories. In addition, we propose a phenomenological creep law with a time-dependent stress exponent that captures the sigmoidal primary creep observed in wrought INCONEL 625 and extracts its temperature dependence from DABI test at multiple temperatures. Furthermore, we employ a general creep law combining several conventional forms together with regularized inversion to identify the creep laws for 47 additional Fe-, Ni-, and Co-rich alloys and to automatically select the dominant functional form for each alloy. This workflow combined with DABI experiment provides a quantitative, high-throughput creep characterization platform that is compatible with data mining, composition-property modeling, and nonlinear structural optimization with creep behavior across a large alloy design space.
GLOW: Graph-Language Co-Reasoning for Agentic Workflow Performance Prediction
Dec 11, 2025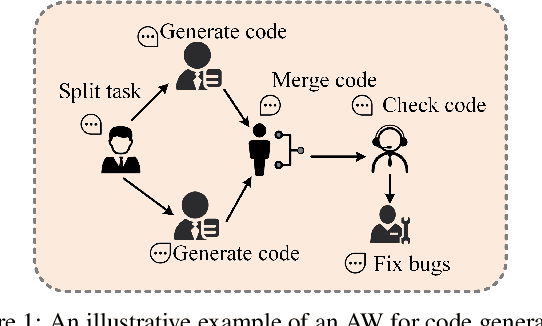



Agentic Workflows (AWs) have emerged as a promising paradigm for solving complex tasks. However, the scalability of automating their generation is severely constrained by the high cost and latency of execution-based evaluation. Existing AW performance prediction methods act as surrogates but fail to simultaneously capture the intricate topological dependencies and the deep semantic logic embedded in AWs. To address this limitation, we propose GLOW, a unified framework for AW performance prediction that combines the graph-structure modeling capabilities of GNNs with the reasoning power of LLMs. Specifically, we introduce a graph-oriented LLM, instruction-tuned on graph tasks, to extract topologically aware semantic features, which are fused with GNN-encoded structural representations. A contrastive alignment strategy further refines the latent space to distinguish high-quality AWs. Extensive experiments on FLORA-Bench show that GLOW outperforms state-of-the-art baselines in prediction accuracy and ranking utility.
Adaptive Digital Twin of Sheet Metal Forming via Proper Orthogonal Decomposition-Based Koopman Operator with Model Predictive Control
Nov 13, 2025

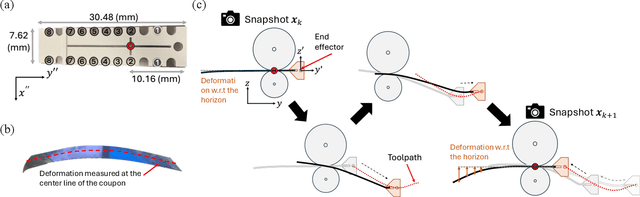
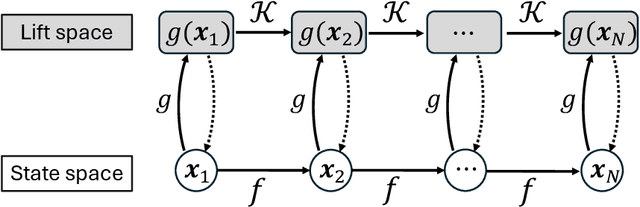
Digital Twin (DT) technologies are transforming manufacturing by enabling real-time prediction, monitoring, and control of complex processes. Yet, applying DT to deformation-based metal forming remains challenging because of the strongly coupled spatial-temporal behavior and the nonlinear relationship between toolpath and material response. For instance, sheet-metal forming by the English wheel, a highly flexible but artisan-dependent process, still lacks digital counterparts that can autonomously plan and adapt forming strategies. This study presents an adaptive DT framework that integrates Proper Orthogonal Decomposition (POD) for physics-aware dimensionality reduction with a Koopman operator for representing nonlinear system in a linear lifted space for the real-time decision-making via model predictive control (MPC). To accommodate evolving process conditions or material states, an online Recursive Least Squares (RLS) algorithm is introduced to update the operator coefficients in real time, enabling continuous adaptation of the DT model as new deformation data become available. The proposed framework is experimentally demonstrated on a robotic English Wheel sheet metal forming system, where deformation fields are measured and modeled under varying toolpaths. Results show that the adaptive DT is capable of controlling the forming process to achieve the given target shape by effectively capturing non-stationary process behaviors. Beyond this case study, the proposed framework establishes a generalizable approach for interpretable, adaptive, and computationally-efficient DT of nonlinear manufacturing systems, bridging reduced-order physics representations with data-driven adaptability to support autonomous process control and optimization.
EDGC: Entropy-driven Dynamic Gradient Compression for Efficient LLM Training
Nov 13, 2025Training large language models (LLMs) poses significant challenges regarding computational resources and memory capacity. Although distributed training techniques help mitigate these issues, they still suffer from considerable communication overhead. Existing approaches primarily rely on static gradient compression to enhance communication efficiency; however, these methods neglect the dynamic nature of evolving gradients during training, leading to performance degradation. Accelerating LLM training via compression without sacrificing performance remains a challenge. In this paper, we propose an entropy-driven dynamic gradient compression framework called EDGC. The core concept is to adjust the compression rate during LLM training based on the evolving trends of gradient entropy, taking into account both compression efficiency and error. EDGC consists of three key components.First, it employs a down-sampling method to efficiently estimate gradient entropy, reducing computation overhead. Second, it establishes a theoretical model linking compression rate with gradient entropy, enabling more informed compression decisions. Lastly, a window-based adjustment mechanism dynamically adapts the compression rate across pipeline stages, improving communication efficiency and maintaining model performance. We implemented EDGC on a 32-NVIDIA-V100 cluster and a 64-NVIDIA-H100 cluster to train GPT2-2.5B and GPT2-12.1B, respectively. The results show that EDGC significantly reduces communication latency and training time by up to 46.45% and 16.13% while preserving LLM accuracy.
Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture
Nov 11, 2025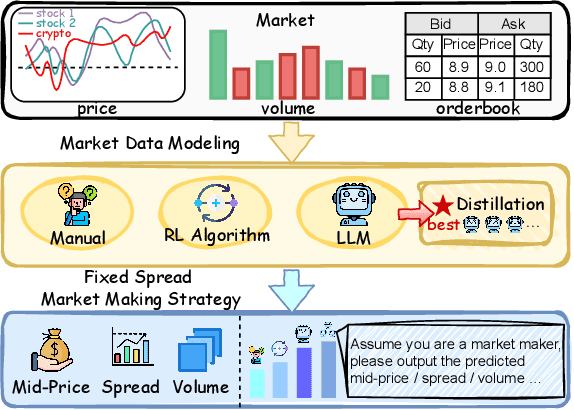

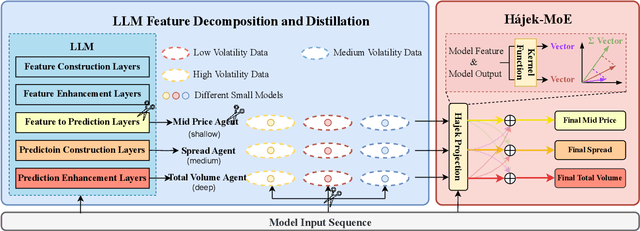

Market making (MM) through Reinforcement Learning (RL) has attracted significant attention in financial trading. With the development of Large Language Models (LLMs), more and more attempts are being made to apply LLMs to financial areas. A simple, direct application of LLM as an agent shows significant performance. Such methods are hindered by their slow inference speed, while most of the current research has not studied LLM distillation for this specific task. To address this, we first propose the normalized fluorescent probe to study the mechanism of the LLM's feature. Based on the observation found by our investigation, we propose Cooperative Market Making (CMM), a novel framework that decouples LLM features across three orthogonal dimensions: layer, task, and data. Various student models collaboratively learn simple LLM features along with different dimensions, with each model responsible for a distinct feature to achieve knowledge distillation. Furthermore, CMM introduces an Hájek-MoE to integrate the output of the student models by investigating the contribution of different models in a kernel function-generated common feature space. Extensive experimental results on four real-world market datasets demonstrate the superiority of CMM over the current distillation method and RL-based market-making strategies.
COLUR: Confidence-Oriented Learning, Unlearning and Relearning with Noisy-Label Data for Model Restoration and Refinement
Jun 24, 2025Large deep learning models have achieved significant success in various tasks. However, the performance of a model can significantly degrade if it is needed to train on datasets with noisy labels with misleading or ambiguous information. To date, there are limited investigations on how to restore performance when model degradation has been incurred by noisy label data. Inspired by the ``forgetting mechanism'' in neuroscience, which enables accelerating the relearning of correct knowledge by unlearning the wrong knowledge, we propose a robust model restoration and refinement (MRR) framework COLUR, namely Confidence-Oriented Learning, Unlearning and Relearning. Specifically, we implement COLUR with an efficient co-training architecture to unlearn the influence of label noise, and then refine model confidence on each label for relearning. Extensive experiments are conducted on four real datasets and all evaluation results show that COLUR consistently outperforms other SOTA methods after MRR.
Recalling The Forgotten Class Memberships: Unlearned Models Can Be Noisy Labelers to Leak Privacy
Jun 24, 2025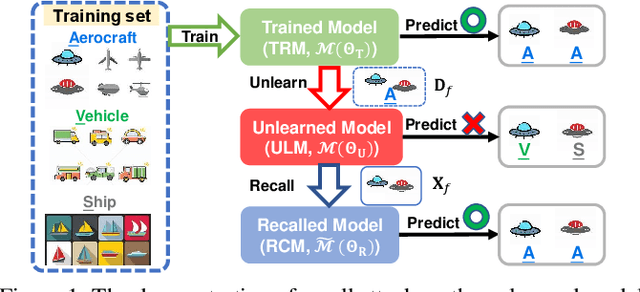
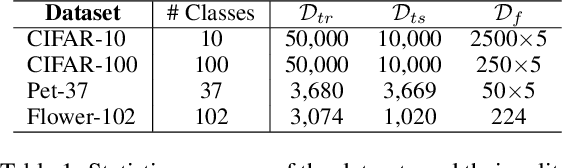
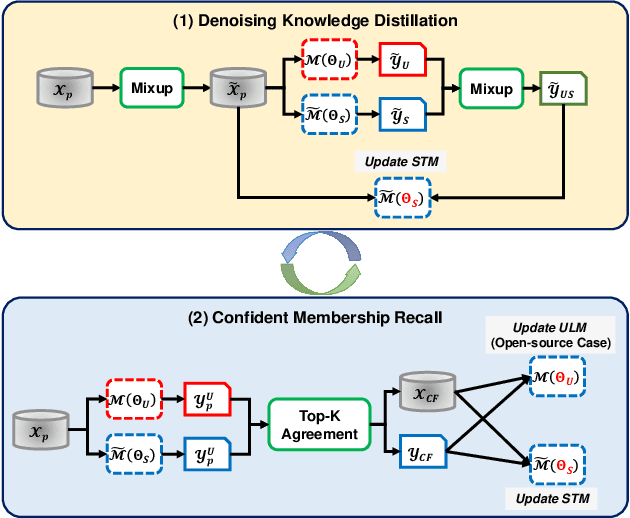
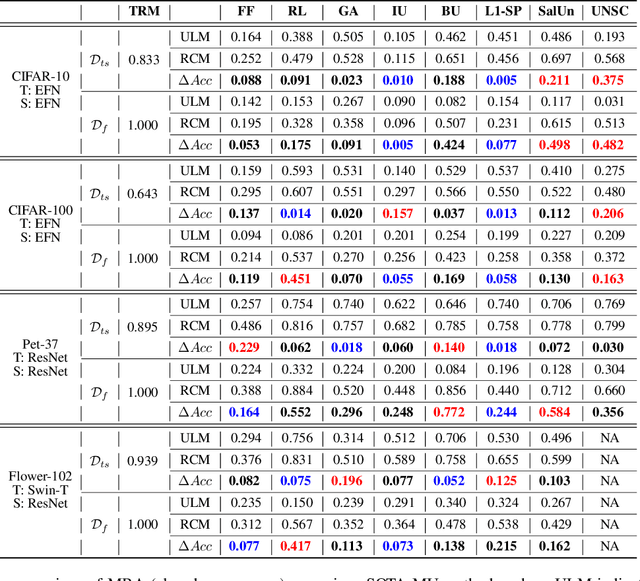
Machine Unlearning (MU) technology facilitates the removal of the influence of specific data instances from trained models on request. Despite rapid advancements in MU technology, its vulnerabilities are still underexplored, posing potential risks of privacy breaches through leaks of ostensibly unlearned information. Current limited research on MU attacks requires access to original models containing privacy data, which violates the critical privacy-preserving objective of MU. To address this gap, we initiate an innovative study on recalling the forgotten class memberships from unlearned models (ULMs) without requiring access to the original one. Specifically, we implement a Membership Recall Attack (MRA) framework with a teacher-student knowledge distillation architecture, where ULMs serve as noisy labelers to transfer knowledge to student models. Then, it is translated into a Learning with Noisy Labels (LNL) problem for inferring the correct labels of the forgetting instances. Extensive experiments on state-of-the-art MU methods with multiple real datasets demonstrate that the proposed MRA strategy exhibits high efficacy in recovering class memberships of unlearned instances. As a result, our study and evaluation have established a benchmark for future research on MU vulnerabilities.
HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark
Jun 04, 2025As AI evolves, collaboration among heterogeneous models helps overcome data scarcity by enabling knowledge transfer across institutions and devices. Traditional Federated Learning (FL) only supports homogeneous models, limiting collaboration among clients with heterogeneous model architectures. To address this, Heterogeneous Federated Learning (HtFL) methods are developed to enable collaboration across diverse heterogeneous models while tackling the data heterogeneity issue at the same time. However, a comprehensive benchmark for standardized evaluation and analysis of the rapidly growing HtFL methods is lacking. Firstly, the highly varied datasets, model heterogeneity scenarios, and different method implementations become hurdles to making easy and fair comparisons among HtFL methods. Secondly, the effectiveness and robustness of HtFL methods are under-explored in various scenarios, such as the medical domain and sensor signal modality. To fill this gap, we introduce the first Heterogeneous Federated Learning Library (HtFLlib), an easy-to-use and extensible framework that integrates multiple datasets and model heterogeneity scenarios, offering a robust benchmark for research and practical applications. Specifically, HtFLlib integrates (1) 12 datasets spanning various domains, modalities, and data heterogeneity scenarios; (2) 40 model architectures, ranging from small to large, across three modalities; (3) a modularized and easy-to-extend HtFL codebase with implementations of 10 representative HtFL methods; and (4) systematic evaluations in terms of accuracy, convergence, computation costs, and communication costs. We emphasize the advantages and potential of state-of-the-art HtFL methods and hope that HtFLlib will catalyze advancing HtFL research and enable its broader applications. The code is released at https://github.com/TsingZ0/HtFLlib.
LKD-KGC: Domain-Specific KG Construction via LLM-driven Knowledge Dependency Parsing
May 30, 2025Knowledge Graphs (KGs) structure real-world entities and their relationships into triples, enhancing machine reasoning for various tasks. While domain-specific KGs offer substantial benefits, their manual construction is often inefficient and requires specialized knowledge. Recent approaches for knowledge graph construction (KGC) based on large language models (LLMs), such as schema-guided KGC and reference knowledge integration, have proven efficient. However, these methods are constrained by their reliance on manually defined schema, single-document processing, and public-domain references, making them less effective for domain-specific corpora that exhibit complex knowledge dependencies and specificity, as well as limited reference knowledge. To address these challenges, we propose LKD-KGC, a novel framework for unsupervised domain-specific KG construction. LKD-KGC autonomously analyzes document repositories to infer knowledge dependencies, determines optimal processing sequences via LLM driven prioritization, and autoregressively generates entity schema by integrating hierarchical inter-document contexts. This schema guides the unsupervised extraction of entities and relationships, eliminating reliance on predefined structures or external knowledge. Extensive experiments show that compared with state-of-the-art baselines, LKD-KGC generally achieves improvements of 10% to 20% in both precision and recall rate, demonstrating its potential in constructing high-quality domain-specific KGs.