 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Paper and Code
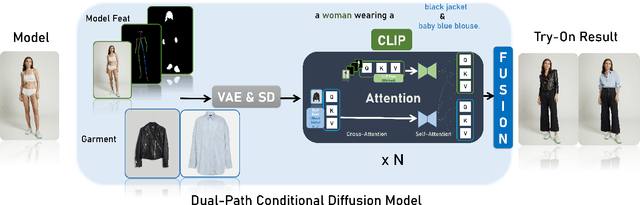
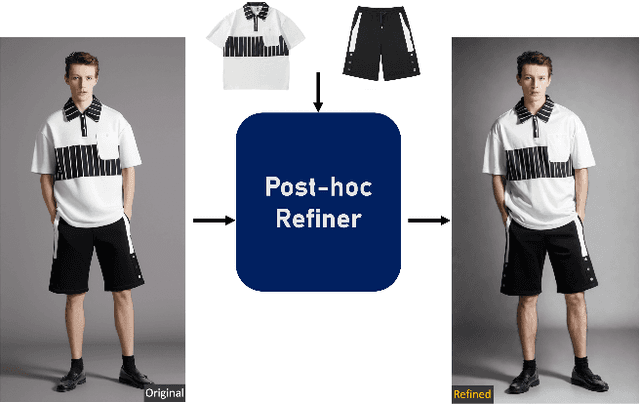


Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images. OutfitAnyone's performance in diverse scenarios underscores its utility and readiness for real-world deployment. For more details and animated results, please see \url{https://humanaigc.github.io/outfit-anyone/}.