 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

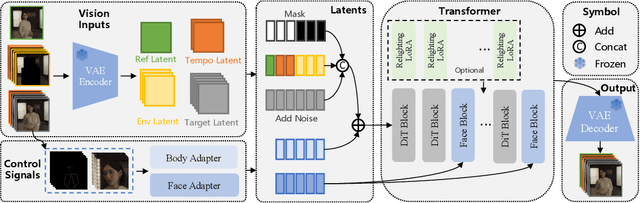
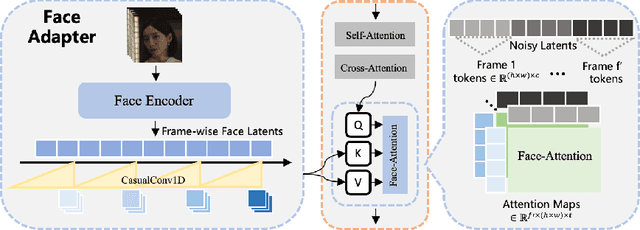
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
Feb 10, 2025



Recent character image animation methods based on diffusion models, such as Animate Anyone, have made significant progress in generating consistent and generalizable character animations. However, these approaches fail to produce reasonable associations between characters and their environments. To address this limitation, we introduce Animate Anyone 2, aiming to animate characters with environment affordance. Beyond extracting motion signals from source video, we additionally capture environmental representations as conditional inputs. The environment is formulated as the region with the exclusion of characters and our model generates characters to populate these regions while maintaining coherence with the environmental context. We propose a shape-agnostic mask strategy that more effectively characterizes the relationship between character and environment. Furthermore, to enhance the fidelity of object interactions, we leverage an object guider to extract features of interacting objects and employ spatial blending for feature injection. We also introduce a pose modulation strategy that enables the model to handle more diverse motion patterns. Experimental results demonstrate the superior performance of the proposed method.
OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Jul 23, 2024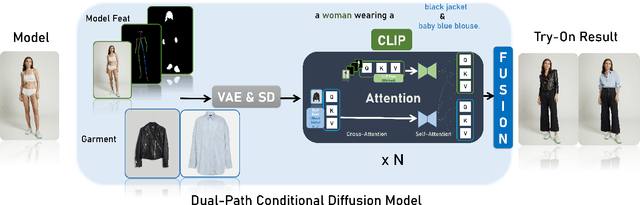
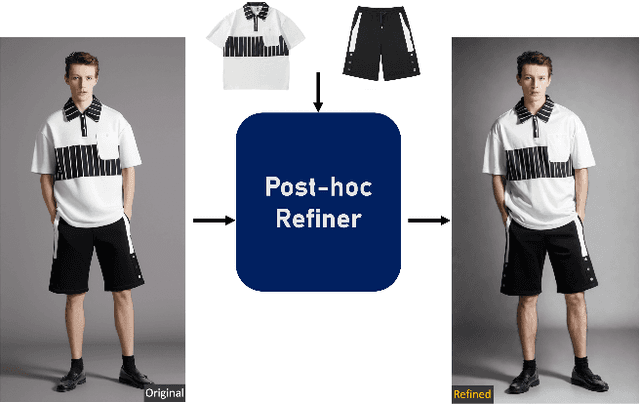


Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images. OutfitAnyone's performance in diverse scenarios underscores its utility and readiness for real-world deployment. For more details and animated results, please see \url{https://humanaigc.github.io/outfit-anyone/}.
Deformable Gabor Feature Networks for Biomedical Image Classification
Dec 07, 2020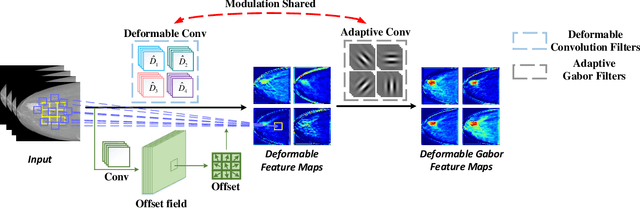

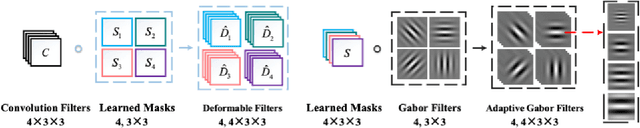
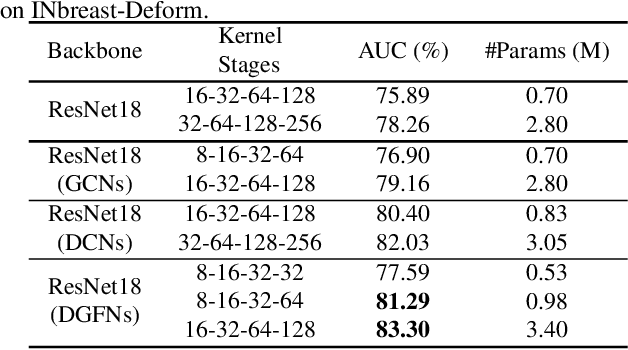
In recent years, deep learning has dominated progress in the field of medical image analysis. We find however, that the ability of current deep learning approaches to represent the complex geometric structures of many medical images is insufficient. One limitation is that deep learning models require a tremendous amount of data, and it is very difficult to obtain a sufficient amount with the necessary detail. A second limitation is that there are underlying features of these medical images that are well established, but the black-box nature of existing convolutional neural networks (CNNs) do not allow us to exploit them. In this paper, we revisit Gabor filters and introduce a deformable Gabor convolution (DGConv) to expand deep networks interpretability and enable complex spatial variations. The features are learned at deformable sampling locations with adaptive Gabor convolutions to improve representativeness and robustness to complex objects. The DGConv replaces standard convolutional layers and is easily trained end-to-end, resulting in deformable Gabor feature network (DGFN) with few additional parameters and minimal additional training cost. We introduce DGFN for addressing deep multi-instance multi-label classification on the INbreast dataset for mammograms and on the ChestX-ray14 dataset for pulmonary x-ray images.
The Structure Transfer Machine Theory and Applications
Apr 01, 2018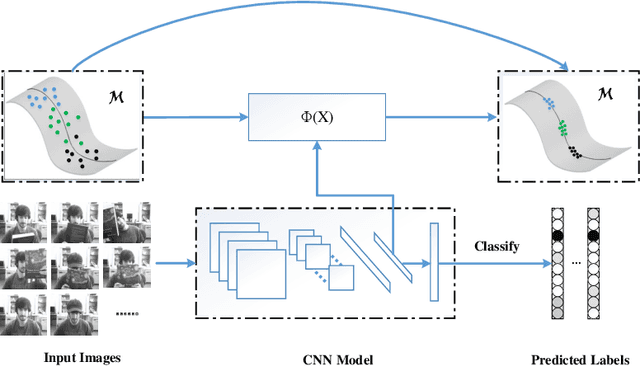
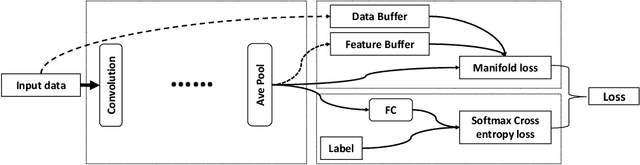
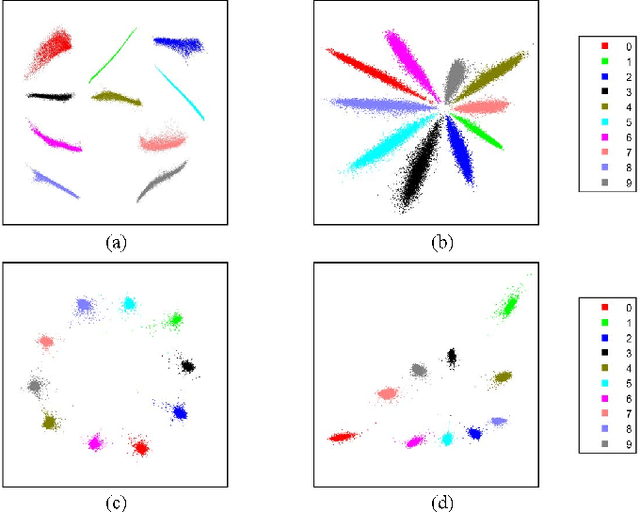
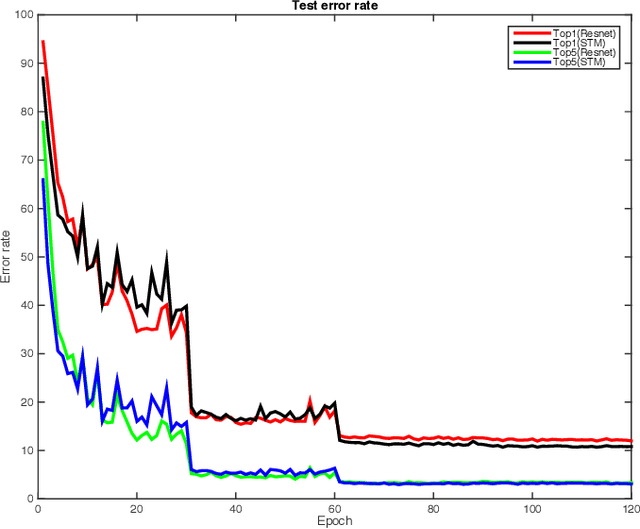
Representation learning is a fundamental but challenging problem, especially when the distribution of data is unknown. We propose a new representation learning method, termed Structure Transfer Machine (STM), which enables feature learning process to converge at the representation expectation in a probabilistic way. We theoretically show that such an expected value of the representation (mean) is achievable if the manifold structure can be transferred from the data space to the feature space. The resulting structure regularization term, named manifold loss, is incorporated into the loss function of the typical deep learning pipeline. The STM architecture is constructed to enforce the learned deep representation to satisfy the intrinsic manifold structure from the data, which results in robust features that suit various application scenarios, such as digit recognition, image classification and object tracking. Compared to state-of-the-art CNN architectures, we achieve the better results on several commonly used benchmarks\footnote{The source code is available. https://github.com/stmstmstm/stm }.