 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLLaVA: Fairness-Aware Parameter-Efficient Fine-Tuning for Large Vision-Language Assistants
Mar 27, 2026While powerful in image-conditioned generation, multimodal large language models (MLLMs) can display uneven performance across demographic groups, highlighting fairness risks. In safety-critical clinical settings, such disparities risk producing unequal diagnostic narratives and eroding trust in AI-assisted decision-making. While fairness has been studied extensively in vision-only and language-only models, its impact on MLLMs remains largely underexplored. To address these biases, we introduce FairLLaVA, a parameter-efficient fine-tuning method that mitigates group disparities in visual instruction tuning without compromising overall performance. By minimizing the mutual information between target attributes, FairLLaVA regularizes the model's representations to be demographic-invariant. The method can be incorporated as a lightweight plug-in, maintaining efficiency with low-rank adapter fine-tuning, and provides an architecture-agnostic approach to fair visual instruction following. Extensive experiments on large-scale chest radiology report generation and dermoscopy visual question answering benchmarks show that FairLLaVA consistently reduces inter-group disparities while improving both equity-scaled clinical performance and natural language generation quality across diverse medical imaging modalities. Code can be accessed at https://github.com/bhosalems/FairLLaVA.
VCORE: Variance-Controlled Optimization-based Reweighting for Chain-of-Thought Supervision
Oct 31, 2025



Supervised fine-tuning (SFT) on long chain-of-thought (CoT) trajectories has emerged as a crucial technique for enhancing the reasoning abilities of large language models (LLMs). However, the standard cross-entropy loss treats all tokens equally, ignoring their heterogeneous contributions across a reasoning trajectory. This uniform treatment leads to misallocated supervision and weak generalization, especially in complex, long-form reasoning tasks. To address this, we introduce \textbf{V}ariance-\textbf{C}ontrolled \textbf{O}ptimization-based \textbf{RE}weighting (VCORE), a principled framework that reformulates CoT supervision as a constrained optimization problem. By adopting an optimization-theoretic perspective, VCORE enables a principled and adaptive allocation of supervision across tokens, thereby aligning the training objective more closely with the goal of robust reasoning generalization. Empirical evaluations demonstrate that VCORE consistently outperforms existing token reweighting methods. Across both in-domain and out-of-domain settings, VCORE achieves substantial performance gains on mathematical and coding benchmarks, using models from the Qwen3 series (4B, 8B, 32B) and LLaMA-3.1-8B-Instruct. Moreover, we show that VCORE serves as a more effective initialization for subsequent reinforcement learning, establishing a stronger foundation for advancing the reasoning capabilities of LLMs. The Code will be released at https://github.com/coder-gx/VCORE.
From Parameters to Prompts: Understanding and Mitigating the Factuality Gap between Fine-Tuned LLMs
May 29, 2025Factual knowledge extraction aims to explicitly extract knowledge parameterized in pre-trained language models for application in downstream tasks. While prior work has been investigating the impact of supervised fine-tuning data on the factuality of large language models (LLMs), its mechanism remains poorly understood. We revisit this impact through systematic experiments, with a particular focus on the factuality gap that arises when fine-tuning on known versus unknown knowledge. Our findings show that this gap can be mitigated at the inference stage, either under out-of-distribution (OOD) settings or by using appropriate in-context learning (ICL) prompts (i.e., few-shot learning and Chain of Thought (CoT)). We prove this phenomenon theoretically from the perspective of knowledge graphs, showing that the test-time prompt may diminish or even overshadow the impact of fine-tuning data and play a dominant role in knowledge extraction. Ultimately, our results shed light on the interaction between finetuning data and test-time prompt, demonstrating that ICL can effectively compensate for shortcomings in fine-tuning data, and highlighting the need to reconsider the use of ICL prompting as a means to evaluate the effectiveness of fine-tuning data selection methods.
CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Computational Pathology
Dec 16, 2024The emergence of large multimodal models (LMMs) has brought significant advancements to pathology. Previous research has primarily focused on separately training patch-level and whole-slide image (WSI)-level models, limiting the integration of learned knowledge across patches and WSIs, and resulting in redundant models. In this work, we introduce CPath-Omni, the first 15-billion-parameter LMM designed to unify both patch and WSI level image analysis, consolidating a variety of tasks at both levels, including classification, visual question answering, captioning, and visual referring prompting. Extensive experiments demonstrate that CPath-Omni achieves state-of-the-art (SOTA) performance across seven diverse tasks on 39 out of 42 datasets, outperforming or matching task-specific models trained for individual tasks. Additionally, we develop a specialized pathology CLIP-based visual processor for CPath-Omni, CPath-CLIP, which, for the first time, integrates different vision models and incorporates a large language model as a text encoder to build a more powerful CLIP model, which achieves SOTA performance on nine zero-shot and four few-shot datasets. Our findings highlight CPath-Omni's ability to unify diverse pathology tasks, demonstrating its potential to streamline and advance the field of foundation model in pathology.
DAMRO: Dive into the Attention Mechanism of LVLM to Reduce Object Hallucination
Oct 06, 2024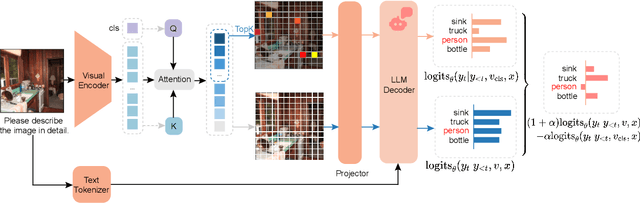
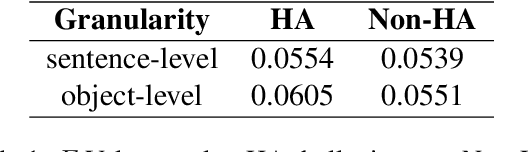

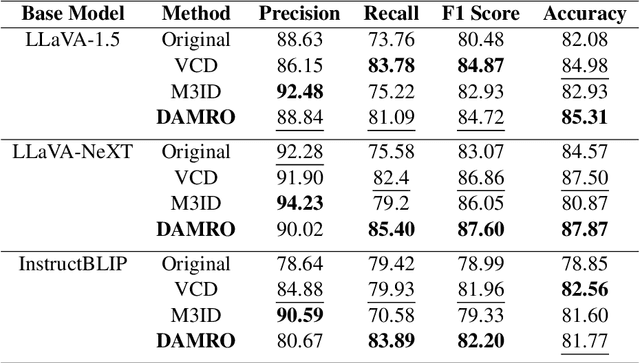
Despite the great success of Large Vision-Language Models (LVLMs), they inevitably suffer from hallucination. As we know, both the visual encoder and the Large Language Model (LLM) decoder in LVLMs are Transformer-based, allowing the model to extract visual information and generate text outputs via attention mechanisms. We find that the attention distribution of LLM decoder on image tokens is highly consistent with the visual encoder and both distributions tend to focus on particular background tokens rather than the referred objects in the image. We attribute to the unexpected attention distribution to an inherent flaw in the visual encoder itself, which misguides LLMs to over emphasize the redundant information and generate object hallucination. To address the issue, we propose DAMRO, a novel training-free strategy that $D$ive into $A$ttention $M$echanism of LVLM to $R$educe $O$bject Hallucination. Specifically, our approach employs classification token (CLS) of ViT to filter out high-attention outlier tokens scattered in the background and then eliminate their influence during decoding stage. We evaluate our method on LVLMs including LLaVA-1.5, LLaVA-NeXT and InstructBLIP, using various benchmarks such as POPE, CHAIR, MME and GPT-4V Aided Evaluation. The results demonstrate that our approach significantly reduces the impact of these outlier tokens, thus effectively alleviating the hallucination of LVLMs. The code of our method will be released soon.
Self-supervised 3D Patient Modeling with Multi-modal Attentive Fusion
Mar 05, 20243D patient body modeling is critical to the success of automated patient positioning for smart medical scanning and operating rooms. Existing CNN-based end-to-end patient modeling solutions typically require a) customized network designs demanding large amount of relevant training data, covering extensive realistic clinical scenarios (e.g., patient covered by sheets), which leads to suboptimal generalizability in practical deployment, b) expensive 3D human model annotations, i.e., requiring huge amount of manual effort, resulting in systems that scale poorly. To address these issues, we propose a generic modularized 3D patient modeling method consists of (a) a multi-modal keypoint detection module with attentive fusion for 2D patient joint localization, to learn complementary cross-modality patient body information, leading to improved keypoint localization robustness and generalizability in a wide variety of imaging (e.g., CT, MRI etc.) and clinical scenarios (e.g., heavy occlusions); and (b) a self-supervised 3D mesh regression module which does not require expensive 3D mesh parameter annotations to train, bringing immediate cost benefits for clinical deployment. We demonstrate the efficacy of the proposed method by extensive patient positioning experiments on both public and clinical data. Our evaluation results achieve superior patient positioning performance across various imaging modalities in real clinical scenarios.
Spectrum AUC Difference (SAUCD): Human-aligned 3D Shape Evaluation
Mar 03, 2024



Existing 3D mesh shape evaluation metrics mainly focus on the overall shape but are usually less sensitive to local details. This makes them inconsistent with human evaluation, as human perception cares about both overall and detailed shape. In this paper, we propose an analytic metric named Spectrum Area Under the Curve Difference (SAUCD) that demonstrates better consistency with human evaluation. To compare the difference between two shapes, we first transform the 3D mesh to the spectrum domain using the discrete Laplace-Beltrami operator and Fourier transform. Then, we calculate the Area Under the Curve (AUC) difference between the two spectrums, so that each frequency band that captures either the overall or detailed shape is equitably considered. Taking human sensitivity across frequency bands into account, we further extend our metric by learning suitable weights for each frequency band which better aligns with human perception. To measure the performance of SAUCD, we build a 3D mesh evaluation dataset called Shape Grading, along with manual annotations from more than 800 subjects. By measuring the correlation between our metric and human evaluation, we demonstrate that SAUCD is well aligned with human evaluation, and outperforms previous 3D mesh metrics.
Federated Learning via Input-Output Collaborative Distillation
Dec 22, 2023



Federated learning (FL) is a machine learning paradigm in which distributed local nodes collaboratively train a central model without sharing individually held private data. Existing FL methods either iteratively share local model parameters or deploy co-distillation. However, the former is highly susceptible to private data leakage, and the latter design relies on the prerequisites of task-relevant real data. Instead, we propose a data-free FL framework based on local-to-central collaborative distillation with direct input and output space exploitation. Our design eliminates any requirement of recursive local parameter exchange or auxiliary task-relevant data to transfer knowledge, thereby giving direct privacy control to local users. In particular, to cope with the inherent data heterogeneity across locals, our technique learns to distill input on which each local model produces consensual yet unique results to represent each expertise. Our proposed FL framework achieves notable privacy-utility trade-offs with extensive experiments on image classification and segmentation tasks under various real-world heterogeneous federated learning settings on both natural and medical images.
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
May 27, 2023



Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.
Harnessing Low-Frequency Neural Fields for Few-Shot View Synthesis
Mar 15, 2023



Neural Radiance Fields (NeRF) have led to breakthroughs in the novel view synthesis problem. Positional Encoding (P.E.) is a critical factor that brings the impressive performance of NeRF, where low-dimensional coordinates are mapped to high-dimensional space to better recover scene details. However, blindly increasing the frequency of P.E. leads to overfitting when the reconstruction problem is highly underconstrained, \eg, few-shot images for training. We harness low-frequency neural fields to regularize high-frequency neural fields from overfitting to better address the problem of few-shot view synthesis. We propose reconstructing with a low-frequency only field and then finishing details with a high-frequency equipped field. Unlike most existing solutions that regularize the output space (\ie, rendered images), our regularization is conducted in the input space (\ie, signal frequency). We further propose a simple-yet-effective strategy for tuning the frequency to avoid overfitting few-shot inputs: enforcing consistency among the frequency domain of rendered 2D images. Thanks to the input space regularizing scheme, our method readily applies to inputs beyond spatial locations, such as the time dimension in dynamic scenes. Comparisons with state-of-the-art on both synthetic and natural datasets validate the effectiveness of our proposed solution for few-shot view synthesis. Code is available at \href{https://github.com/lsongx/halo}{https://github.com/lsongx/halo}.