 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMRO: Dive into the Attention Mechanism of LVLM to Reduce Object Hallucination
Paper and Code
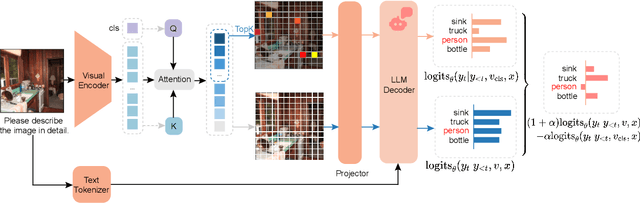
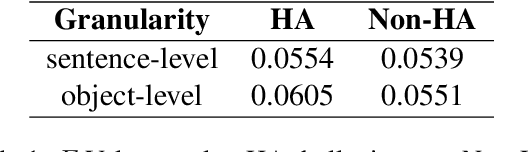

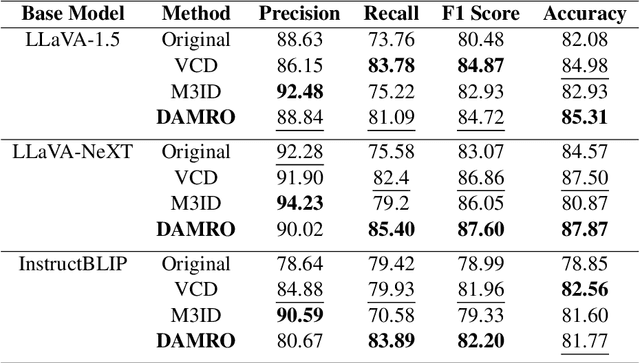
Despite the great success of Large Vision-Language Models (LVLMs), they inevitably suffer from hallucination. As we know, both the visual encoder and the Large Language Model (LLM) decoder in LVLMs are Transformer-based, allowing the model to extract visual information and generate text outputs via attention mechanisms. We find that the attention distribution of LLM decoder on image tokens is highly consistent with the visual encoder and both distributions tend to focus on particular background tokens rather than the referred objects in the image. We attribute to the unexpected attention distribution to an inherent flaw in the visual encoder itself, which misguides LLMs to over emphasize the redundant information and generate object hallucination. To address the issue, we propose DAMRO, a novel training-free strategy that $D$ive into $A$ttention $M$echanism of LVLM to $R$educe $O$bject Hallucination. Specifically, our approach employs classification token (CLS) of ViT to filter out high-attention outlier tokens scattered in the background and then eliminate their influence during decoding stage. We evaluate our method on LVLMs including LLaVA-1.5, LLaVA-NeXT and InstructBLIP, using various benchmarks such as POPE, CHAIR, MME and GPT-4V Aided Evaluation. The results demonstrate that our approach significantly reduces the impact of these outlier tokens, thus effectively alleviating the hallucination of LVLMs. The code of our method will be released soon.