 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeInv: Free Lunch for Improving DDIM Inversion
Mar 29, 2025



Naive DDIM inversion process usually suffers from a trajectory deviation issue, i.e., the latent trajectory during reconstruction deviates from the one during inversion. To alleviate this issue, previous methods either learn to mitigate the deviation or design cumbersome compensation strategy to reduce the mismatch error, exhibiting substantial time and computation cost. In this work, we present a nearly free-lunch method (named FreeInv) to address the issue more effectively and efficiently. In FreeInv, we randomly transform the latent representation and keep the transformation the same between the corresponding inversion and reconstruction time-step. It is motivated from a statistical perspective that an ensemble of DDIM inversion processes for multiple trajectories yields a smaller trajectory mismatch error on expectation. Moreover, through theoretical analysis and empirical study, we show that FreeInv performs an efficient ensemble of multiple trajectories. FreeInv can be freely integrated into existing inversion-based image and video editing techniques. Especially for inverting video sequences, it brings more significant fidelity and efficiency improvements. Comprehensive quantitative and qualitative evaluation on PIE benchmark and DAVIS dataset shows that FreeInv remarkably outperforms conventional DDIM inversion, and is competitive among previous state-of-the-art inversion methods, with superior computation efficiency.
Normalizing Batch Normalization for Long-Tailed Recognition
Jan 06, 2025



In real-world scenarios, the number of training samples across classes usually subjects to a long-tailed distribution. The conventionally trained network may achieve unexpected inferior performance on the rare class compared to the frequent class. Most previous works attempt to rectify the network bias from the data-level or from the classifier-level. Differently, in this paper, we identify that the bias towards the frequent class may be encoded into features, i.e., the rare-specific features which play a key role in discriminating the rare class are much weaker than the frequent-specific features. Based on such an observation, we introduce a simple yet effective approach, normalizing the parameters of Batch Normalization (BN) layer to explicitly rectify the feature bias. To achieve this end, we represent the Weight/Bias parameters of a BN layer as a vector, normalize it into a unit one and multiply the unit vector by a scalar learnable parameter. Through decoupling the direction and magnitude of parameters in BN layer to learn, the Weight/Bias exhibits a more balanced distribution and thus the strength of features becomes more even. Extensive experiments on various long-tailed recognition benchmarks (i.e., CIFAR-10/100-LT, ImageNet-LT and iNaturalist 2018) show that our method outperforms previous state-of-the-arts remarkably. The code and checkpoints are available at https://github.com/yuxiangbao/NBN.
Federated Learning via Input-Output Collaborative Distillation
Dec 22, 2023



Federated learning (FL) is a machine learning paradigm in which distributed local nodes collaboratively train a central model without sharing individually held private data. Existing FL methods either iteratively share local model parameters or deploy co-distillation. However, the former is highly susceptible to private data leakage, and the latter design relies on the prerequisites of task-relevant real data. Instead, we propose a data-free FL framework based on local-to-central collaborative distillation with direct input and output space exploitation. Our design eliminates any requirement of recursive local parameter exchange or auxiliary task-relevant data to transfer knowledge, thereby giving direct privacy control to local users. In particular, to cope with the inherent data heterogeneity across locals, our technique learns to distill input on which each local model produces consensual yet unique results to represent each expertise. Our proposed FL framework achieves notable privacy-utility trade-offs with extensive experiments on image classification and segmentation tasks under various real-world heterogeneous federated learning settings on both natural and medical images.
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation
Nov 01, 2023
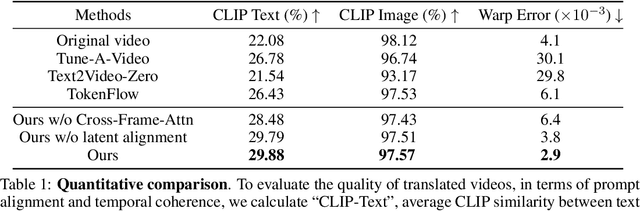

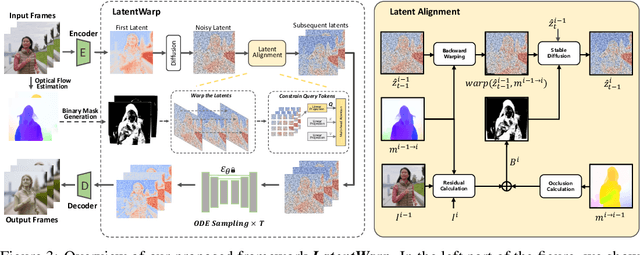
Leveraging the generative ability of image diffusion models offers great potential for zero-shot video-to-video translation. The key lies in how to maintain temporal consistency across generated video frames by image diffusion models. Previous methods typically adopt cross-frame attention, \emph{i.e.,} sharing the \textit{key} and \textit{value} tokens across attentions of different frames, to encourage the temporal consistency. However, in those works, temporal inconsistency issue may not be thoroughly solved, rendering the fidelity of generated videos limited.%The current state of the art cross-frame attention method aims at maintaining fine-grained visual details across frames, but it is still challenged by the temporal coherence problem. In this paper, we find the bottleneck lies in the unconstrained query tokens and propose a new zero-shot video-to-video translation framework, named \textit{LatentWarp}. Our approach is simple: to constrain the query tokens to be temporally consistent, we further incorporate a warping operation in the latent space to constrain the query tokens. Specifically, based on the optical flow obtained from the original video, we warp the generated latent features of last frame to align with the current frame during the denoising process. As a result, the corresponding regions across the adjacent frames can share closely-related query tokens and attention outputs, which can further improve latent-level consistency to enhance visual temporal coherence of generated videos. Extensive experiment results demonstrate the superiority of \textit{LatentWarp} in achieving video-to-video translation with temporal coherence.
Anti-Retroactive Interference for Lifelong Learning
Aug 27, 2022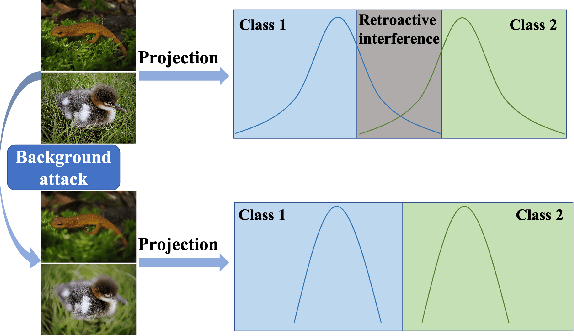

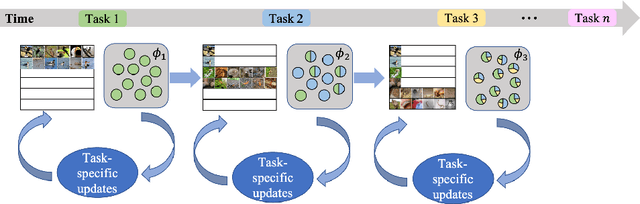

Humans can continuously learn new knowledge. However, machine learning models suffer from drastic dropping in performance on previous tasks after learning new tasks. Cognitive science points out that the competition of similar knowledge is an important cause of forgetting. In this paper, we design a paradigm for lifelong learning based on meta-learning and associative mechanism of the brain. It tackles the problem from two aspects: extracting knowledge and memorizing knowledge. First, we disrupt the sample's background distribution through a background attack, which strengthens the model to extract the key features of each task. Second, according to the similarity between incremental knowledge and base knowledge, we design an adaptive fusion of incremental knowledge, which helps the model allocate capacity to the knowledge of different difficulties. It is theoretically analyzed that the proposed learning paradigm can make the models of different tasks converge to the same optimum. The proposed method is validated on the MNIST, CIFAR100, CUB200 and ImageNet100 datasets.