 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTutti: Expressive Multi-Singer Synthesis via Structure-Level Timbre Control and Vocal Texture Modeling
Feb 09, 2026While existing Singing Voice Synthesis systems achieve high-fidelity solo performances, they are constrained by global timbre control, failing to address dynamic multi-singer arrangement and vocal texture within a single song. To address this, we propose Tutti, a unified framework designed for structured multi-singer generation. Specifically, we introduce a Structure-Aware Singer Prompt to enable flexible singer scheduling evolving with musical structure, and propose Complementary Texture Learning via Condition-Guided VAE to capture implicit acoustic textures (e.g., spatial reverberation and spectral fusion) that are complementary to explicit controls. Experiments demonstrate that Tutti excels in precise multi-singer scheduling and significantly enhances the acoustic realism of choral generation, offering a novel paradigm for complex multi-singer arrangement. Audio samples are available at https://annoauth123-ctrl.github.io/Tutii_Demo/.
F2RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model
Aug 25, 2025Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users' actual needs for revisiting semantically coherent content scattered across long-form conversations. To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To this end, we propose F2RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards promoting semantic precision, relevance, and contextual coherence. To handle varying intra-fragment complexity, from locally dense to sparsely distributed, we introduce difficulty-aware curriculum sampling that ranks training instances by model-predicted difficulty and gradually exposes the model to harder samples. This boosts reasoning ability in long, multi-turn contexts. F2RVLM outperforms popular VLMs in both in-domain and real-domain settings, demonstrating superior retrieval performance.
Enhancing Visual Reliance in Text Generation: A Bayesian Perspective on Mitigating Hallucination in Large Vision-Language Models
May 26, 2025Large Vision-Language Models (LVLMs) usually generate texts which satisfy context coherence but don't match the visual input. Such a hallucination issue hinders LVLMs' applicability in the real world. The key to solving hallucination in LVLM is to make the text generation rely more on the visual content. Most previous works choose to enhance/adjust the features/output of a specific modality (i.e., visual or textual) to alleviate hallucinations in LVLM, which do not explicitly or systematically enhance the visual reliance. In this paper, we comprehensively investigate the factors which may degenerate the visual reliance in text generation of LVLM from a Bayesian perspective. Based on our observations, we propose to mitigate hallucination in LVLM from three aspects. Firstly, we observe that not all visual tokens are informative in generating meaningful texts. We propose to evaluate and remove redundant visual tokens to avoid their disturbance. Secondly, LVLM may encode inappropriate prior information, making it lean toward generating unexpected words. We propose a simple yet effective way to rectify the prior from a Bayesian perspective. Thirdly, we observe that starting from certain steps, the posterior of next-token prediction conditioned on visual tokens may collapse to a prior distribution which does not depend on any informative visual tokens at all. Thus, we propose to stop further text generation to avoid hallucination. Extensive experiments on three benchmarks including POPE, CHAIR, and MME demonstrate that our method can consistently mitigate the hallucination issue of LVLM and performs favorably against previous state-of-the-arts.
Normalizing Batch Normalization for Long-Tailed Recognition
Jan 06, 2025



In real-world scenarios, the number of training samples across classes usually subjects to a long-tailed distribution. The conventionally trained network may achieve unexpected inferior performance on the rare class compared to the frequent class. Most previous works attempt to rectify the network bias from the data-level or from the classifier-level. Differently, in this paper, we identify that the bias towards the frequent class may be encoded into features, i.e., the rare-specific features which play a key role in discriminating the rare class are much weaker than the frequent-specific features. Based on such an observation, we introduce a simple yet effective approach, normalizing the parameters of Batch Normalization (BN) layer to explicitly rectify the feature bias. To achieve this end, we represent the Weight/Bias parameters of a BN layer as a vector, normalize it into a unit one and multiply the unit vector by a scalar learnable parameter. Through decoupling the direction and magnitude of parameters in BN layer to learn, the Weight/Bias exhibits a more balanced distribution and thus the strength of features becomes more even. Extensive experiments on various long-tailed recognition benchmarks (i.e., CIFAR-10/100-LT, ImageNet-LT and iNaturalist 2018) show that our method outperforms previous state-of-the-arts remarkably. The code and checkpoints are available at https://github.com/yuxiangbao/NBN.
Tuning-Free Inversion-Enhanced Control for Consistent Image Editing
Dec 22, 2023



Consistent editing of real images is a challenging task, as it requires performing non-rigid edits (e.g., changing postures) to the main objects in the input image without changing their identity or attributes. To guarantee consistent attributes, some existing methods fine-tune the entire model or the textual embedding for structural consistency, but they are time-consuming and fail to perform non-rigid edits. Other works are tuning-free, but their performances are weakened by the quality of Denoising Diffusion Implicit Model (DDIM) reconstruction, which often fails in real-world scenarios. In this paper, we present a novel approach called Tuning-free Inversion-enhanced Control (TIC), which directly correlates features from the inversion process with those from the sampling process to mitigate the inconsistency in DDIM reconstruction. Specifically, our method effectively obtains inversion features from the key and value features in the self-attention layers, and enhances the sampling process by these inversion features, thus achieving accurate reconstruction and content-consistent editing. To extend the applicability of our method to general editing scenarios, we also propose a mask-guided attention concatenation strategy that combines contents from both the inversion and the naive DDIM editing processes. Experiments show that the proposed method outperforms previous works in reconstruction and consistent editing, and produces impressive results in various settings.
Few-Shot Learning with Visual Distribution Calibration and Cross-Modal Distribution Alignment
May 19, 2023Pre-trained vision-language models have inspired much research on few-shot learning. However, with only a few training images, there exist two crucial problems: (1) the visual feature distributions are easily distracted by class-irrelevant information in images, and (2) the alignment between the visual and language feature distributions is difficult. To deal with the distraction problem, we propose a Selective Attack module, which consists of trainable adapters that generate spatial attention maps of images to guide the attacks on class-irrelevant image areas. By messing up these areas, the critical features are captured and the visual distributions of image features are calibrated. To better align the visual and language feature distributions that describe the same object class, we propose a cross-modal distribution alignment module, in which we introduce a vision-language prototype for each class to align the distributions, and adopt the Earth Mover's Distance (EMD) to optimize the prototypes. For efficient computation, the upper bound of EMD is derived. In addition, we propose an augmentation strategy to increase the diversity of the images and the text prompts, which can reduce overfitting to the few-shot training images. Extensive experiments on 11 datasets demonstrate that our method consistently outperforms prior arts in few-shot learning. The implementation code will be available at https://github.com/bhrqw/SADA.
AttriCLIP: A Non-Incremental Learner for Incremental Knowledge Learning
May 19, 2023



Continual learning aims to enable a model to incrementally learn knowledge from sequentially arrived data. Previous works adopt the conventional classification architecture, which consists of a feature extractor and a classifier. The feature extractor is shared across sequentially arrived tasks or classes, but one specific group of weights of the classifier corresponding to one new class should be incrementally expanded. Consequently, the parameters of a continual learner gradually increase. Moreover, as the classifier contains all historical arrived classes, a certain size of the memory is usually required to store rehearsal data to mitigate classifier bias and catastrophic forgetting. In this paper, we propose a non-incremental learner, named AttriCLIP, to incrementally extract knowledge of new classes or tasks. Specifically, AttriCLIP is built upon the pre-trained visual-language model CLIP. Its image encoder and text encoder are fixed to extract features from both images and text. Text consists of a category name and a fixed number of learnable parameters which are selected from our designed attribute word bank and serve as attributes. As we compute the visual and textual similarity for classification, AttriCLIP is a non-incremental learner. The attribute prompts, which encode the common knowledge useful for classification, can effectively mitigate the catastrophic forgetting and avoid constructing a replay memory. We evaluate our AttriCLIP and compare it with CLIP-based and previous state-of-the-art continual learning methods in realistic settings with domain-shift and long-sequence learning. The results show that our method performs favorably against previous state-of-the-arts. The implementation code can be available at https://github.com/bhrqw/AttriCLIP.
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
May 08, 2023
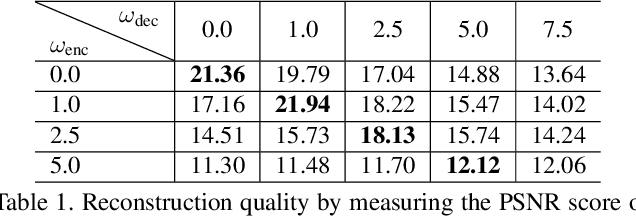
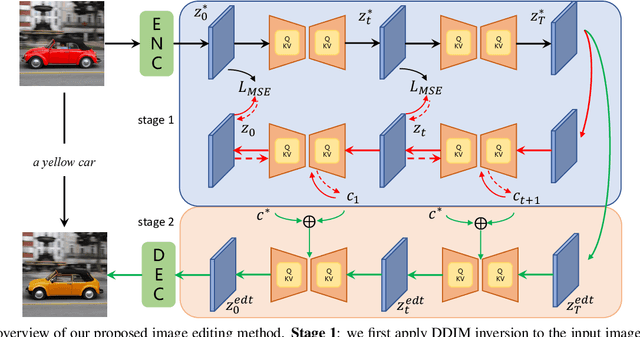
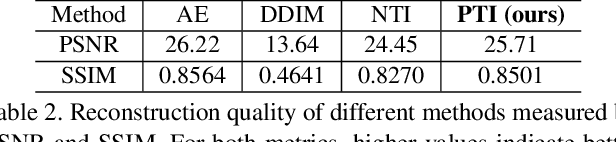
Recently large-scale language-image models (e.g., text-guided diffusion models) have considerably improved the image generation capabilities to generate photorealistic images in various domains. Based on this success, current image editing methods use texts to achieve intuitive and versatile modification of images. To edit a real image using diffusion models, one must first invert the image to a noisy latent from which an edited image is sampled with a target text prompt. However, most methods lack one of the following: user-friendliness (e.g., additional masks or precise descriptions of the input image are required), generalization to larger domains, or high fidelity to the input image. In this paper, we design an accurate and quick inversion technique, Prompt Tuning Inversion, for text-driven image editing. Specifically, our proposed editing method consists of a reconstruction stage and an editing stage. In the first stage, we encode the information of the input image into a learnable conditional embedding via Prompt Tuning Inversion. In the second stage, we apply classifier-free guidance to sample the edited image, where the conditional embedding is calculated by linearly interpolating between the target embedding and the optimized one obtained in the first stage. This technique ensures a superior trade-off between editability and high fidelity to the input image of our method. For example, we can change the color of a specific object while preserving its original shape and background under the guidance of only a target text prompt. Extensive experiments on ImageNet demonstrate the superior editing performance of our method compared to the state-of-the-art baselines.
Rethinking the Number of Shots in Robust Model-Agnostic Meta-Learning
Nov 28, 2022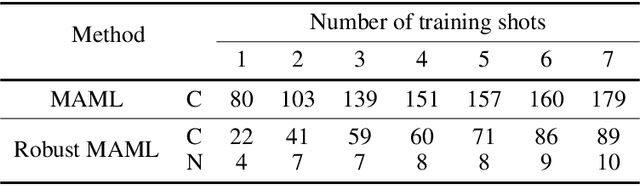
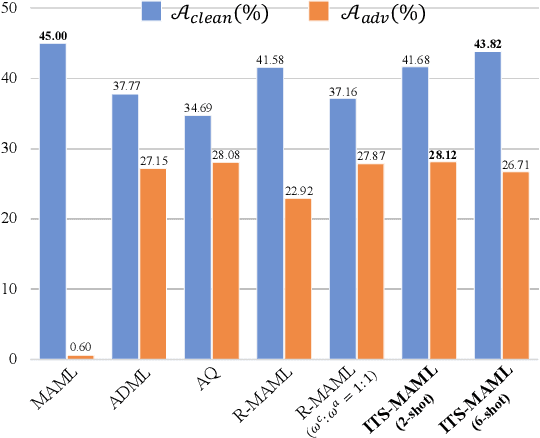

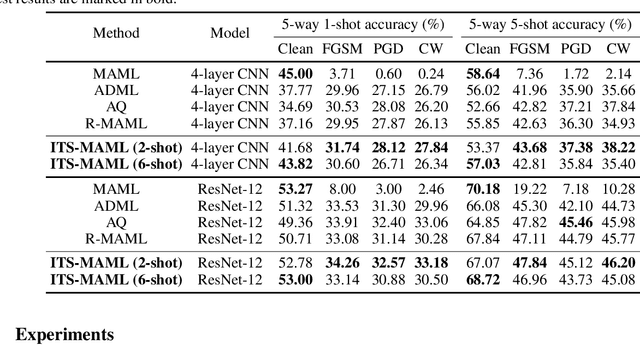
Robust Model-Agnostic Meta-Learning (MAML) is usually adopted to train a meta-model which may fast adapt to novel classes with only a few exemplars and meanwhile remain robust to adversarial attacks. The conventional solution for robust MAML is to introduce robustness-promoting regularization during meta-training stage. With such a regularization, previous robust MAML methods simply follow the typical MAML practice that the number of training shots should match with the number of test shots to achieve an optimal adaptation performance. However, although the robustness can be largely improved, previous methods sacrifice clean accuracy a lot. In this paper, we observe that introducing robustness-promoting regularization into MAML reduces the intrinsic dimension of clean sample features, which results in a lower capacity of clean representations. This may explain why the clean accuracy of previous robust MAML methods drops severely. Based on this observation, we propose a simple strategy, i.e., increasing the number of training shots, to mitigate the loss of intrinsic dimension caused by robustness-promoting regularization. Though simple, our method remarkably improves the clean accuracy of MAML without much loss of robustness, producing a robust yet accurate model. Extensive experiments demonstrate that our method outperforms prior arts in achieving a better trade-off between accuracy and robustness. Besides, we observe that our method is less sensitive to the number of fine-tuning steps during meta-training, which allows for a reduced number of fine-tuning steps to improve training efficiency.
Associative Adversarial Learning Based on Selective Attack
Jan 04, 2022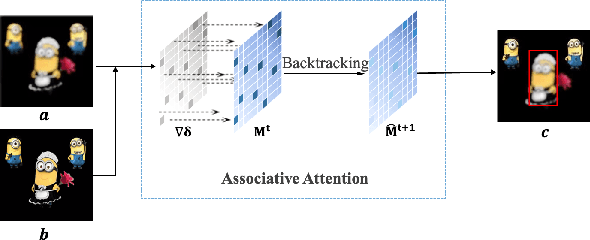
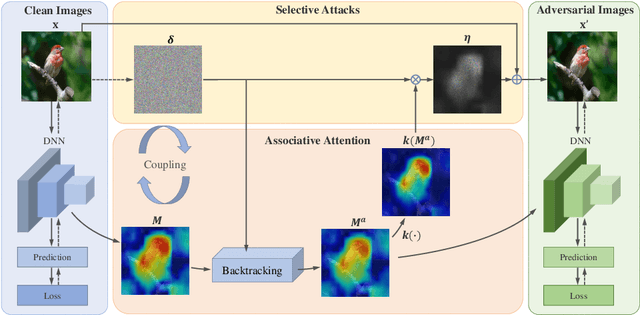
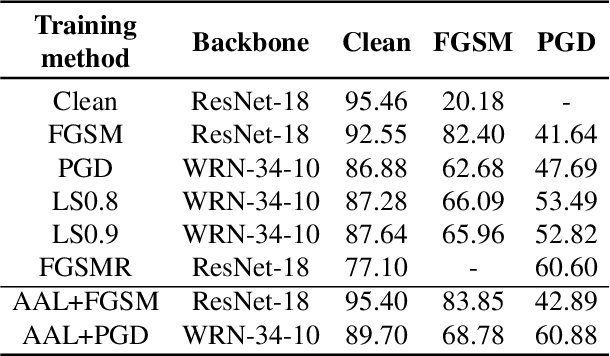
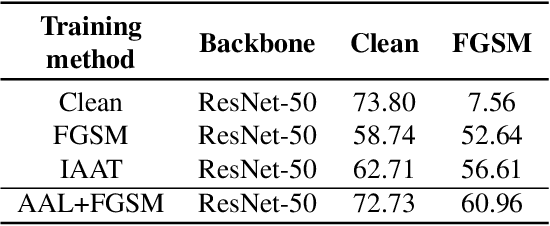
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.