 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
Mar 19, 2026Current instruction-guided video editing models struggle to simultaneously balance precise semantic modifications with faithful motion preservation. While existing approaches rely on injecting explicit external priors (e.g., VLM features or structural conditions) to mitigate these issues, this reliance severely bottlenecks model robustness and generalization. To overcome this limitation, we present SAMA (factorized Semantic Anchoring and Motion Alignment), a framework that factorizes video editing into semantic anchoring and motion modeling. First, we introduce Semantic Anchoring, which establishes a reliable visual anchor by jointly predicting semantic tokens and video latents at sparse anchor frames, enabling purely instruction-aware structural planning. Second, Motion Alignment pre-trains the same backbone on motion-centric video restoration pretext tasks (cube inpainting, speed perturbation, and tube shuffle), enabling the model to internalize temporal dynamics directly from raw videos. SAMA is optimized with a two-stage pipeline: a factorized pre-training stage that learns inherent semantic-motion representations without paired video-instruction editing data, followed by supervised fine-tuning on paired editing data. Remarkably, the factorized pre-training alone already yields strong zero-shot video editing ability, validating the proposed factorization. SAMA achieves state-of-the-art performance among open-source models and is competitive with leading commercial systems (e.g., Kling-Omni). Code, models, and datasets will be released.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
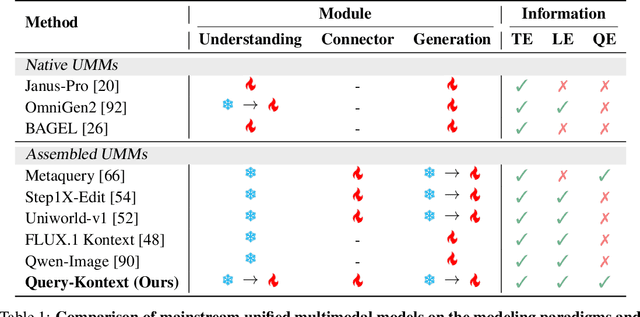
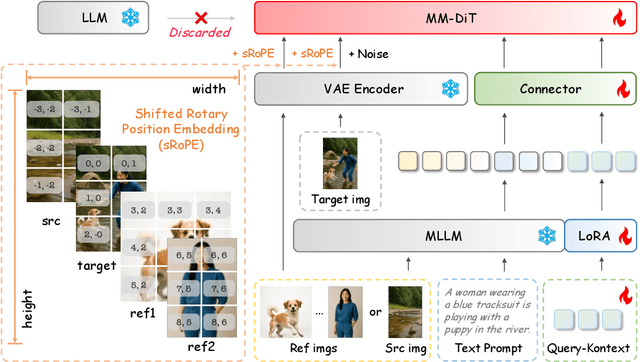
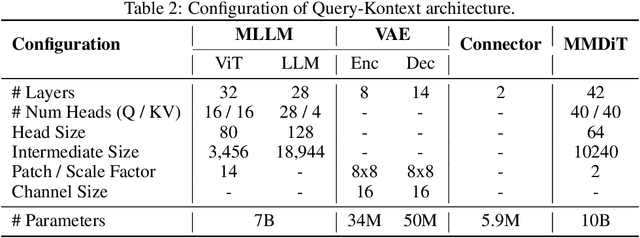
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
May 08, 2023
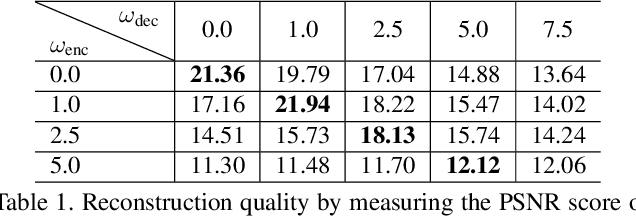
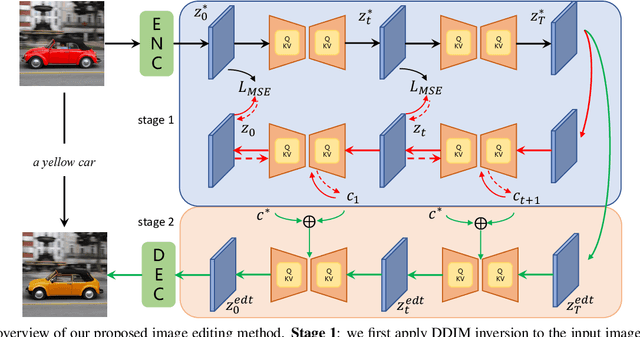
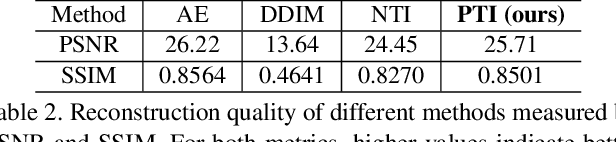
Recently large-scale language-image models (e.g., text-guided diffusion models) have considerably improved the image generation capabilities to generate photorealistic images in various domains. Based on this success, current image editing methods use texts to achieve intuitive and versatile modification of images. To edit a real image using diffusion models, one must first invert the image to a noisy latent from which an edited image is sampled with a target text prompt. However, most methods lack one of the following: user-friendliness (e.g., additional masks or precise descriptions of the input image are required), generalization to larger domains, or high fidelity to the input image. In this paper, we design an accurate and quick inversion technique, Prompt Tuning Inversion, for text-driven image editing. Specifically, our proposed editing method consists of a reconstruction stage and an editing stage. In the first stage, we encode the information of the input image into a learnable conditional embedding via Prompt Tuning Inversion. In the second stage, we apply classifier-free guidance to sample the edited image, where the conditional embedding is calculated by linearly interpolating between the target embedding and the optimized one obtained in the first stage. This technique ensures a superior trade-off between editability and high fidelity to the input image of our method. For example, we can change the color of a specific object while preserving its original shape and background under the guidance of only a target text prompt. Extensive experiments on ImageNet demonstrate the superior editing performance of our method compared to the state-of-the-art baselines.
MF2-MVQA: A Multi-stage Feature Fusion method for Medical Visual Question Answering
Nov 11, 2022There is a key problem in the medical visual question answering task that how to effectively realize the feature fusion of language and medical images with limited datasets. In order to better utilize multi-scale information of medical images, previous methods directly embed the multi-stage visual feature maps as tokens of same size respectively and fuse them with text representation. However, this will cause the confusion of visual features at different stages. To this end, we propose a simple but powerful multi-stage feature fusion method, MF2-MVQA, which stage-wise fuses multi-level visual features with textual semantics. MF2-MVQA achieves the State-Of-The-Art performance on VQA-Med 2019 and VQA-RAD dataset. The results of visualization also verify that our model outperforms previous work.