 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Dec 17, 2025

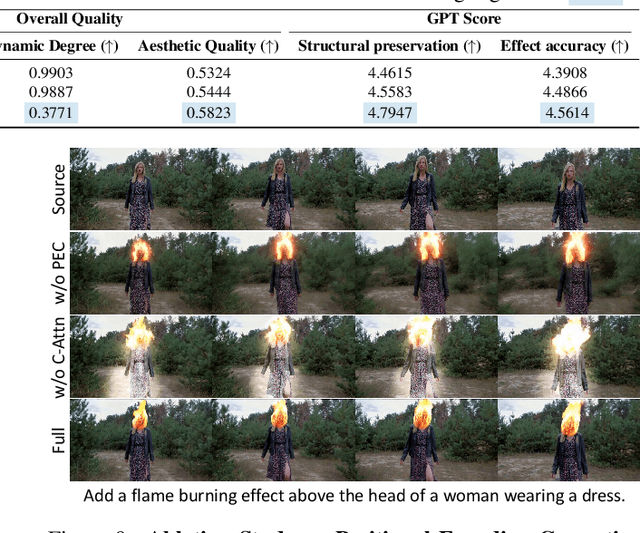

We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
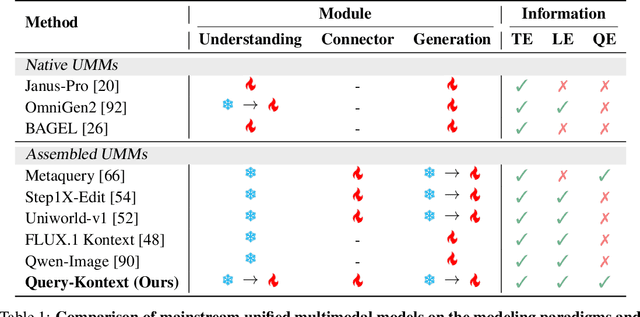
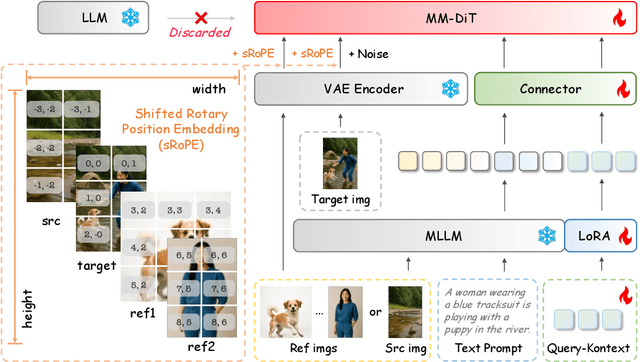
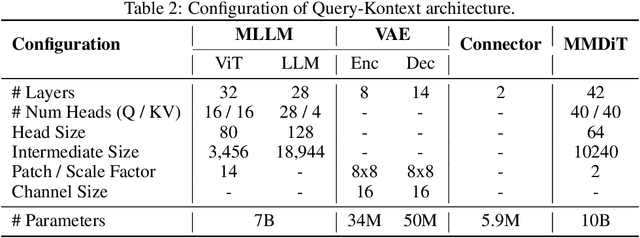
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Sparse Optimization for Transfer Learning: A L0-Regularized Framework for Multi-Source Domain Adaptation
Apr 07, 2025



This paper explores transfer learning in heterogeneous multi-source environments with distributional divergence between target and auxiliary domains. To address challenges in statistical bias and computational efficiency, we propose a Sparse Optimization for Transfer Learning (SOTL) framework based on L0-regularization. The method extends the Joint Estimation Transferred from Strata (JETS) paradigm with two key innovations: (1) L0-constrained exact sparsity for parameter space compression and complexity reduction, and (2) refining optimization focus to emphasize target parameters over redundant ones. Simulations show that SOTL significantly improves both estimation accuracy and computational speed, especially under adversarial auxiliary domain conditions. Empirical validation on the Community and Crime benchmarks demonstrates the statistical robustness of the SOTL method in cross-domain transfer.
Communication-Efficient l_0 Penalized Least Square
Apr 01, 2025


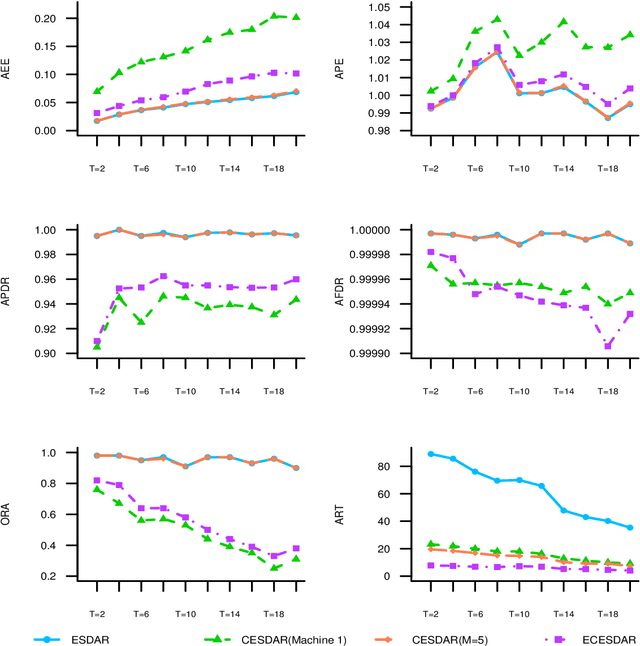
In this paper, we propose a communication-efficient penalized regression algorithm for high-dimensional sparse linear regression models with massive data. This approach incorporates an optimized distributed system communication algorithm, named CESDAR algorithm, based on the Enhanced Support Detection and Root finding algorithm. The CESDAR algorithm leverages data distributed across multiple machines to compute and update the active set and introduces the communication-efficient surrogate likelihood framework to approximate the optimal solution for the full sample on the active set, resulting in the avoidance of raw data transmission, which enhances privacy and data security, while significantly improving algorithm execution speed and substantially reducing communication costs. Notably, this approach achieves the same statistical accuracy as the global estimator. Furthermore, this paper explores an extended version of CESDAR and an adaptive version of CESDAR to enhance algorithmic speed and optimize parameter selection, respectively. Simulations and real data benchmarks experiments demonstrate the efficiency and accuracy of the CESDAR algorithm.
DeepVARMA: A Hybrid Deep Learning and VARMA Model for Chemical Industry Index Forecasting
Apr 26, 2024



Since the chemical industry index is one of the important indicators to measure the development of the chemical industry, forecasting it is critical for understanding the economic situation and trends of the industry. Taking the multivariable nonstationary series-synthetic material index as the main research object, this paper proposes a new prediction model: DeepVARMA, and its variants Deep-VARMA-re and DeepVARMA-en, which combine LSTM and VARMAX models. The new model firstly uses the deep learning model such as the LSTM remove the trends of the target time series and also learn the representation of endogenous variables, and then uses the VARMAX model to predict the detrended target time series with the embeddings of endogenous variables, and finally combines the trend learned by the LSTM and dependency learned by the VARMAX model to obtain the final predictive values. The experimental results show that (1) the new model achieves the best prediction accuracy by combining the LSTM encoding of the exogenous variables and the VARMAX model. (2) In multivariate non-stationary series prediction, DeepVARMA uses a phased processing strategy to show higher adaptability and accuracy compared to the traditional VARMA model as well as the machine learning models LSTM, RF and XGBoost. (3) Compared with smooth sequence prediction, the traditional VARMA and VARMAX models fluctuate more in predicting non-smooth sequences, while DeepVARMA shows more flexibility and robustness. This study provides more accurate tools and methods for future development and scientific decision-making in the chemical industry.
CLOP: Video-and-Language Pre-Training with Knowledge Regularizations
Nov 07, 2022Video-and-language pre-training has shown promising results for learning generalizable representations. Most existing approaches usually model video and text in an implicit manner, without considering explicit structural representations of the multi-modal content. We denote such form of representations as structural knowledge, which express rich semantics of multiple granularities. There are related works that propose object-aware approaches to inject similar knowledge as inputs. However, the existing methods usually fail to effectively utilize such knowledge as regularizations to shape a superior cross-modal representation space. To this end, we propose a Cross-modaL knOwledge-enhanced Pre-training (CLOP) method with Knowledge Regularizations. There are two key designs of ours: 1) a simple yet effective Structural Knowledge Prediction (SKP) task to pull together the latent representations of similar videos; and 2) a novel Knowledge-guided sampling approach for Contrastive Learning (KCL) to push apart cross-modal hard negative samples. We evaluate our method on four text-video retrieval tasks and one multi-choice QA task. The experiments show clear improvements, outperforming prior works by a substantial margin. Besides, we provide ablations and insights of how our methods affect the latent representation space, demonstrating the value of incorporating knowledge regularizations into video-and-language pre-training.
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.
Temporal-Spatial dependencies ENhanced deep learning model (TSEN) for household leverage series forecasting
Oct 17, 2022
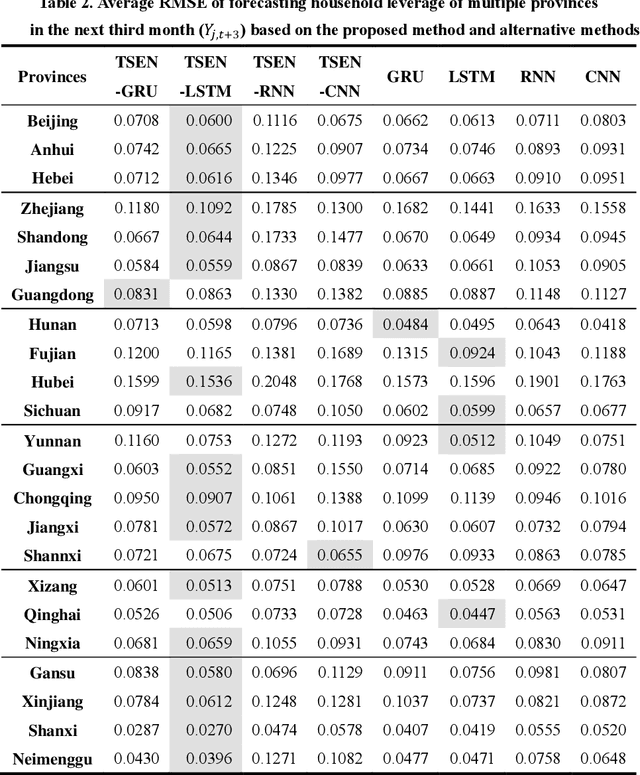

Analyzing both temporal and spatial patterns for an accurate forecasting model for financial time series forecasting is a challenge due to the complex nature of temporal-spatial dynamics: time series from different locations often have distinct patterns; and for the same time series, patterns may vary as time goes by. Inspired by the successful applications of deep learning, we propose a new model to resolve the issues of forecasting household leverage in China. Our solution consists of multiple RNN-based layers and an attention layer: each RNN-based layer automatically learns the temporal pattern of a specific series with multivariate exogenous series, and then the attention layer learns the spatial correlative weight and obtains the global representations simultaneously. The results show that the new approach can capture the temporal-spatial dynamics of household leverage well and get more accurate and solid predictive results. More, the simulation also studies show that clustering and choosing correlative series are necessary to obtain accurate forecasting results.
A transfer learning enhanced the physics-informed neural network model for vortex-induced vibration
Dec 29, 2021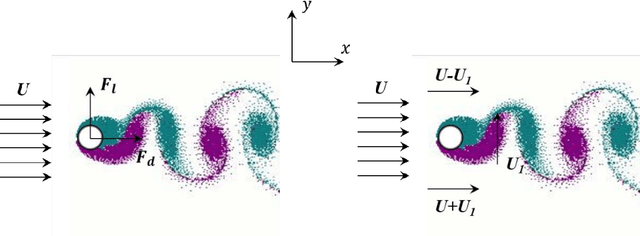

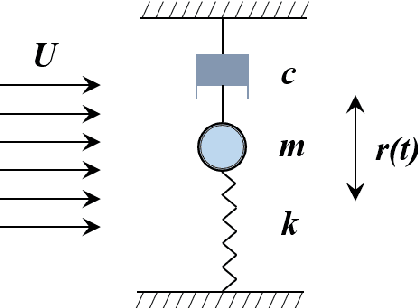

Vortex-induced vibration (VIV) is a typical nonlinear fluid-structure interaction phenomenon, which widely exists in practical engineering (the flexible riser, the bridge and the aircraft wing, etc). The conventional finite element model (FEM)-based and data-driven approaches for VIV analysis often suffer from the challenges of the computational cost and acquisition of datasets. This paper proposed a transfer learning enhanced the physics-informed neural network (PINN) model to study the VIV (2D). The physics-informed neural network, when used in conjunction with the transfer learning method, enhances learning efficiency and keeps predictability in the target task by common characteristics knowledge from the source model without requiring a huge quantity of datasets. The datasets obtained from VIV experiment are divided evenly two parts (source domain and target domain), to evaluate the performance of the model. The results show that the proposed method match closely with the results available in the literature using conventional PINN algorithms even though the quantity of datasets acquired in training model gradually becomes smaller. The application of the model can break the limitation of monitoring equipment and methods in the practical projects, and promote the in-depth study of VIV.