 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOT-ALD: Aligning Latent Distributions with Optimal Transport for Accelerated Image-to-Image Translation
Nov 14, 2025The Dual Diffusion Implicit Bridge (DDIB) is an emerging image-to-image (I2I) translation method that preserves cycle consistency while achieving strong flexibility. It links two independently trained diffusion models (DMs) in the source and target domains by first adding noise to a source image to obtain a latent code, then denoising it in the target domain to generate the translated image. However, this method faces two key challenges: (1) low translation efficiency, and (2) translation trajectory deviations caused by mismatched latent distributions. To address these issues, we propose a novel I2I translation framework, OT-ALD, grounded in optimal transport (OT) theory, which retains the strengths of DDIB-based approach. Specifically, we compute an OT map from the latent distribution of the source domain to that of the target domain, and use the mapped distribution as the starting point for the reverse diffusion process in the target domain. Our error analysis confirms that OT-ALD eliminates latent distribution mismatches. Moreover, OT-ALD effectively balances faster image translation with improved image quality. Experiments on four translation tasks across three high-resolution datasets show that OT-ALD improves sampling efficiency by 20.29% and reduces the FID score by 2.6 on average compared to the top-performing baseline models.
Solving Prior Distribution Mismatch in Diffusion Models via Optimal Transport
Oct 17, 2024


In recent years, the knowledge surrounding diffusion models(DMs) has grown significantly, though several theoretical gaps remain. Particularly noteworthy is prior error, defined as the discrepancy between the termination distribution of the forward process and the initial distribution of the reverse process. To address these deficiencies, this paper explores the deeper relationship between optimal transport(OT) theory and DMs with discrete initial distribution. Specifically, we demonstrate that the two stages of DMs fundamentally involve computing time-dependent OT. However, unavoidable prior error result in deviation during the reverse process under quadratic transport cost. By proving that as the diffusion termination time increases, the probability flow exponentially converges to the gradient of the solution to the classical Monge-Amp\`ere equation, we establish a vital link between these fields. Therefore, static OT emerges as the most intrinsic single-step method for bridging this theoretical potential gap. Additionally, we apply these insights to accelerate sampling in both unconditional and conditional generation scenarios. Experimental results across multiple image datasets validate the effectiveness of our approach.
DPM-OT: A New Diffusion Probabilistic Model Based on Optimal Transport
Jul 21, 2023
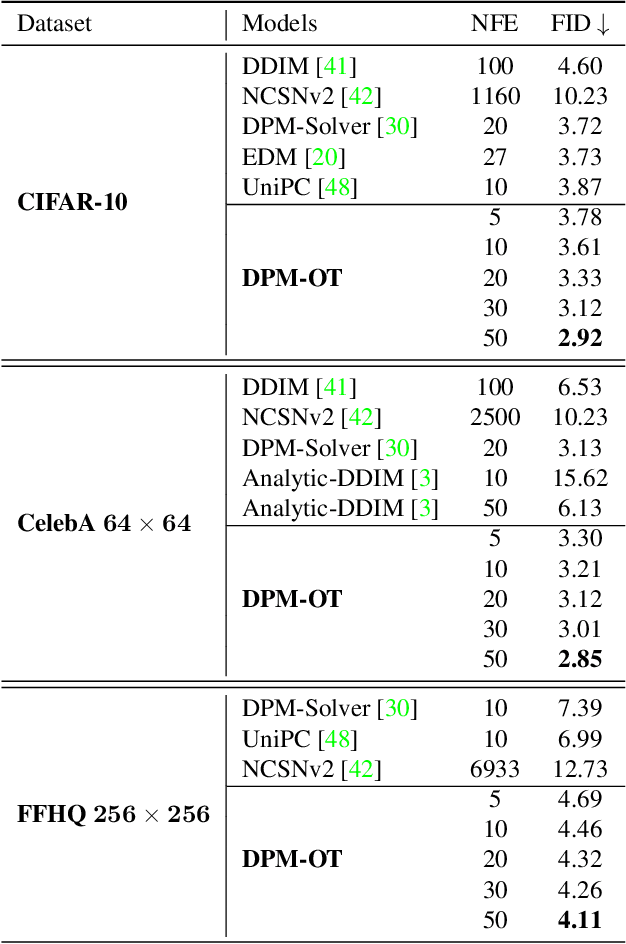


Sampling from diffusion probabilistic models (DPMs) can be viewed as a piecewise distribution transformation, which generally requires hundreds or thousands of steps of the inverse diffusion trajectory to get a high-quality image. Recent progress in designing fast samplers for DPMs achieves a trade-off between sampling speed and sample quality by knowledge distillation or adjusting the variance schedule or the denoising equation. However, it can't be optimal in both aspects and often suffer from mode mixture in short steps. To tackle this problem, we innovatively regard inverse diffusion as an optimal transport (OT) problem between latents at different stages and propose the DPM-OT, a unified learning framework for fast DPMs with a direct expressway represented by OT map, which can generate high-quality samples within around 10 function evaluations. By calculating the semi-discrete optimal transport map between the data latents and the white noise, we obtain an expressway from the prior distribution to the data distribution, while significantly alleviating the problem of mode mixture. In addition, we give the error bound of the proposed method, which theoretically guarantees the stability of the algorithm. Extensive experiments validate the effectiveness and advantages of DPM-OT in terms of speed and quality (FID and mode mixture), thus representing an efficient solution for generative modeling. Source codes are available at https://github.com/cognaclee/DPM-OT
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.